 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrated Weak Learning
Jun 19, 2022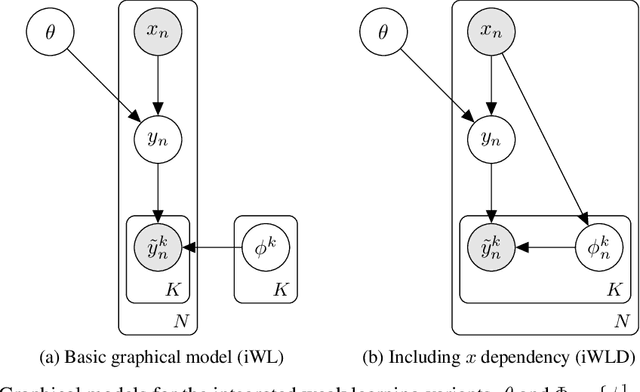
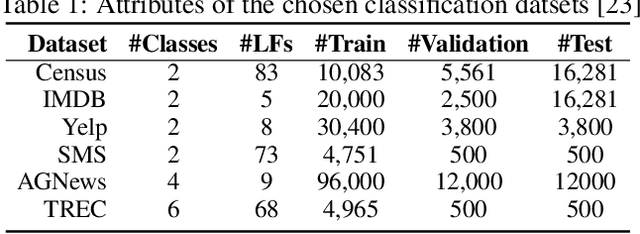
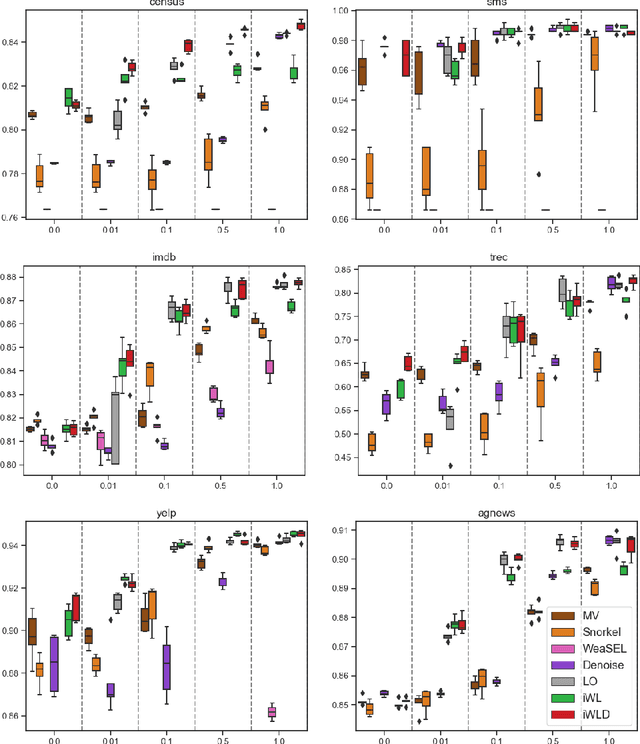
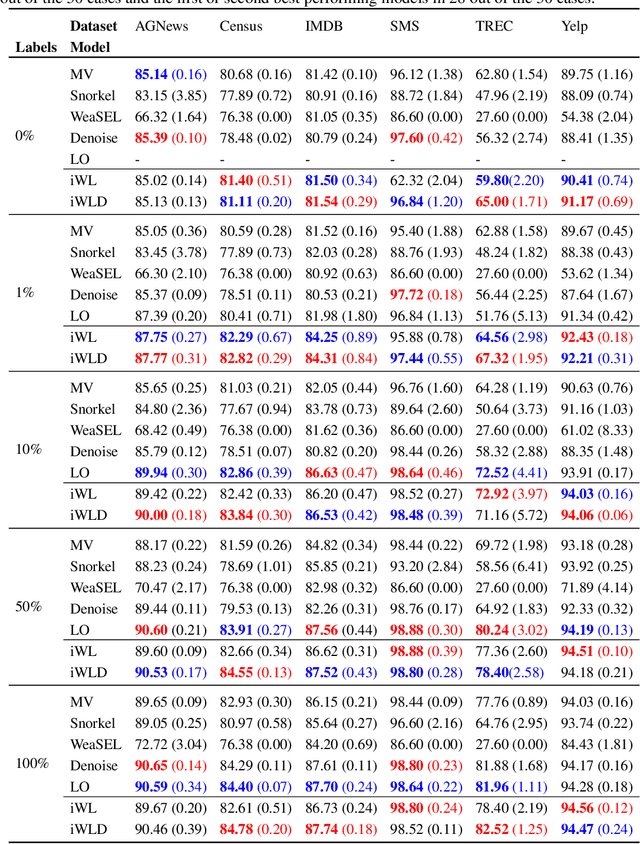
We introduce Integrated Weak Learning, a principled framework that integrates weak supervision into the training process of machine learning models. Our approach jointly trains the end-model and a label model that aggregates multiple sources of weak supervision. We introduce a label model that can learn to aggregate weak supervision sources differently for different datapoints and takes into consideration the performance of the end-model during training. We show that our approach outperforms existing weak learning techniques across a set of 6 benchmark classification datasets. When both a small amount of labeled data and weak supervision are present the increase in performance is both consistent and large, reliably getting a 2-5 point test F1 score gain over non-integrated methods.
Sample Efficient Model Evaluation
Sep 24, 2021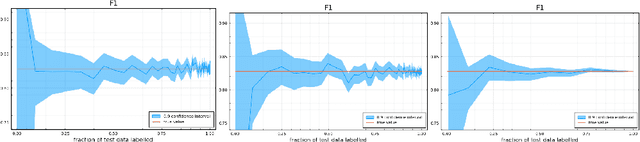
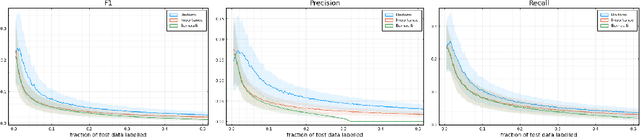
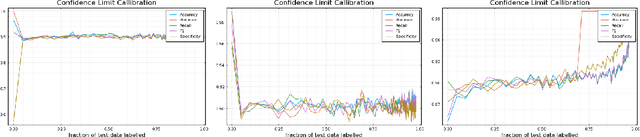
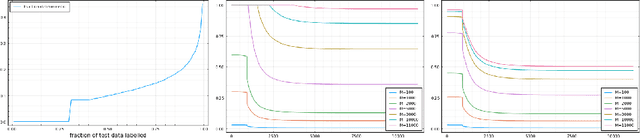
Labelling data is a major practical bottleneck in training and testing classifiers. Given a collection of unlabelled data points, we address how to select which subset to label to best estimate test metrics such as accuracy, $F_1$ score or micro/macro $F_1$. We consider two sampling based approaches, namely the well-known Importance Sampling and we introduce a novel application of Poisson Sampling. For both approaches we derive the minimal error sampling distributions and how to approximate and use them to form estimators and confidence intervals. We show that Poisson Sampling outperforms Importance Sampling both theoretically and experimentally.
Semi-Supervised Generative Modeling for Controllable Speech Synthesis
Oct 03, 2019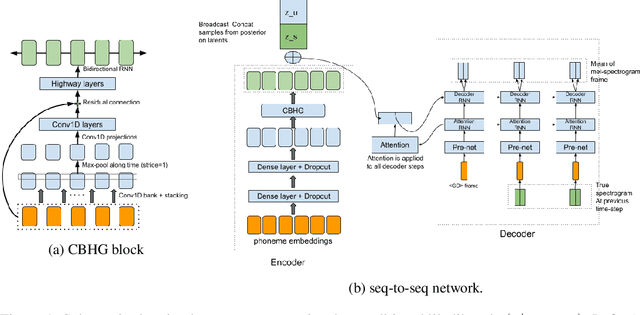


We present a novel generative model that combines state-of-the-art neural text-to-speech (TTS) with semi-supervised probabilistic latent variable models. By providing partial supervision to some of the latent variables, we are able to force them to take on consistent and interpretable purposes, which previously hasn't been possible with purely unsupervised TTS models. We demonstrate that our model is able to reliably discover and control important but rarely labelled attributes of speech, such as affect and speaking rate, with as little as 1% (30 minutes) supervision. Even at such low supervision levels we do not observe a degradation of synthesis quality compared to a state-of-the-art baseline. Audio samples are available on the web.
Variational f-divergence Minimization
Jul 27, 2019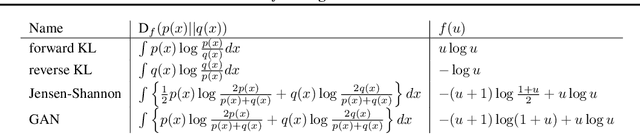

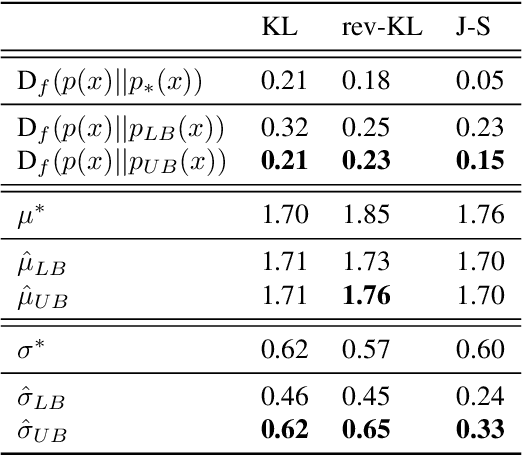
Probabilistic models are often trained by maximum likelihood, which corresponds to minimizing a specific f-divergence between the model and data distribution. In light of recent successes in training Generative Adversarial Networks, alternative non-likelihood training criteria have been proposed. Whilst not necessarily statistically efficient, these alternatives may better match user requirements such as sharp image generation. A general variational method for training probabilistic latent variable models using maximum likelihood is well established; however, how to train latent variable models using other f-divergences is comparatively unknown. We discuss a variational approach that, when combined with the recently introduced Spread Divergence, can be applied to train a large class of latent variable models using any f-divergence.
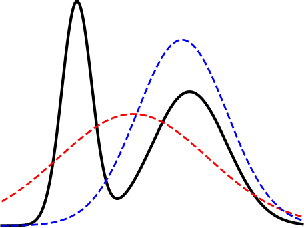
Spread Divergences
Dec 02, 2018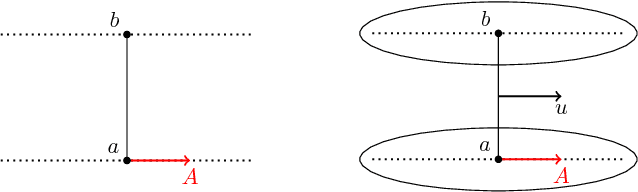
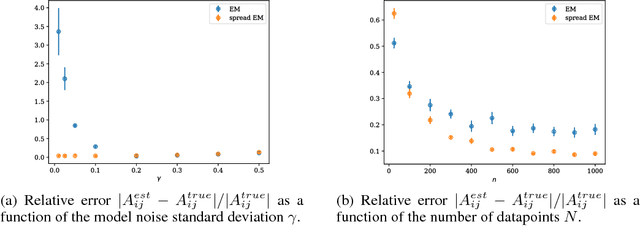


For distributions p and q with different support, the divergence generally will not exist. We define a spread divergence on modified p and q and describe sufficient conditions for the existence of such a divergence. We give examples of using a spread divergence to train implicit generative models, including linear models (Principal Components Analysis and Independent Components Analysis) and non-linear models (Deep Generative Networks).