Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSample Efficient Model Evaluation
Paper and Code
Sep 24, 2021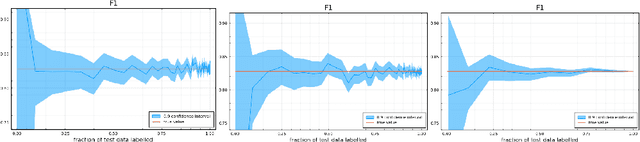
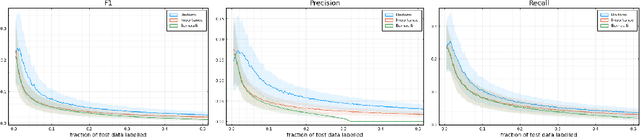
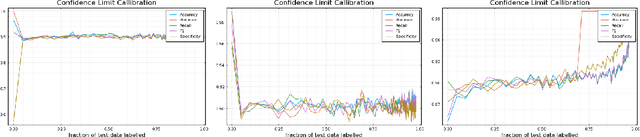
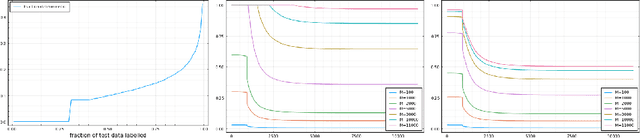
Labelling data is a major practical bottleneck in training and testing classifiers. Given a collection of unlabelled data points, we address how to select which subset to label to best estimate test metrics such as accuracy, $F_1$ score or micro/macro $F_1$. We consider two sampling based approaches, namely the well-known Importance Sampling and we introduce a novel application of Poisson Sampling. For both approaches we derive the minimal error sampling distributions and how to approximate and use them to form estimators and confidence intervals. We show that Poisson Sampling outperforms Importance Sampling both theoretically and experimentally.
View paper on