 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrated Weak Learning
Jun 19, 2022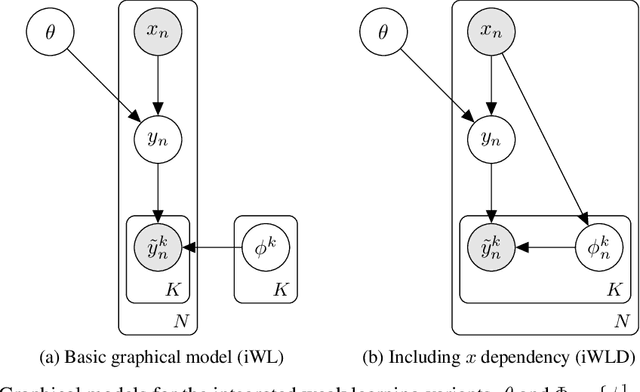
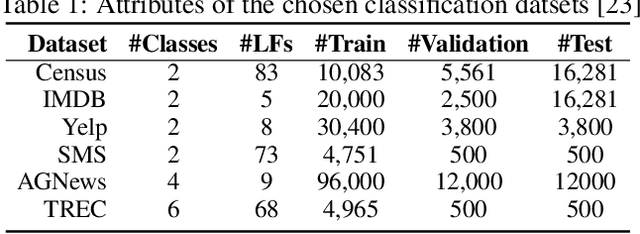
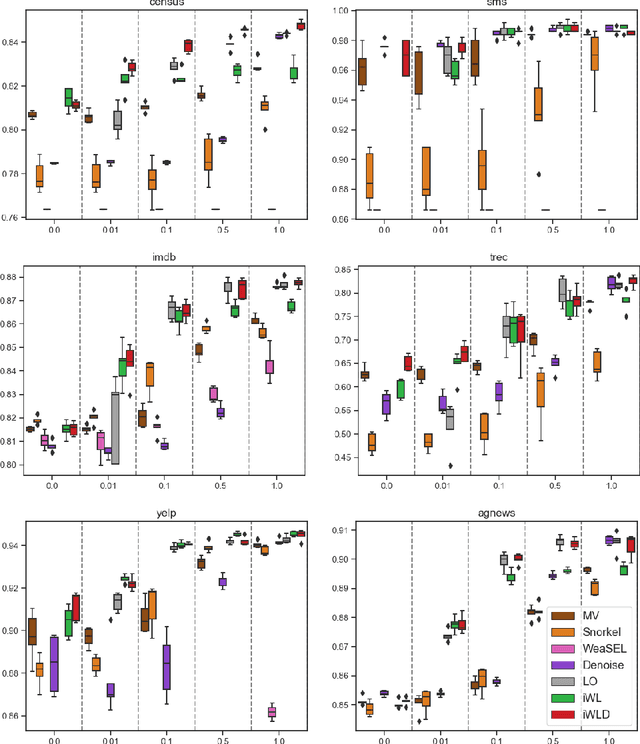
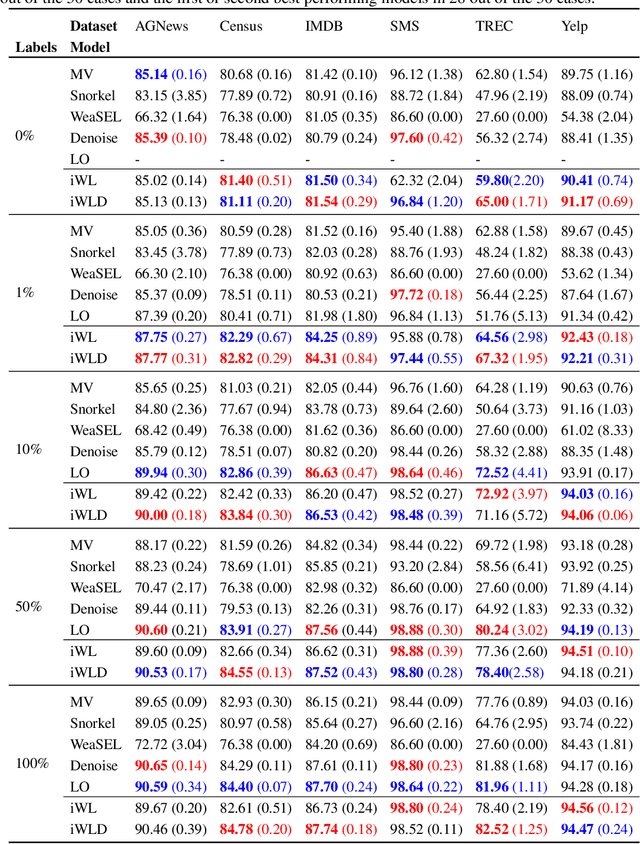
We introduce Integrated Weak Learning, a principled framework that integrates weak supervision into the training process of machine learning models. Our approach jointly trains the end-model and a label model that aggregates multiple sources of weak supervision. We introduce a label model that can learn to aggregate weak supervision sources differently for different datapoints and takes into consideration the performance of the end-model during training. We show that our approach outperforms existing weak learning techniques across a set of 6 benchmark classification datasets. When both a small amount of labeled data and weak supervision are present the increase in performance is both consistent and large, reliably getting a 2-5 point test F1 score gain over non-integrated methods.
Sample Efficient Model Evaluation
Sep 24, 2021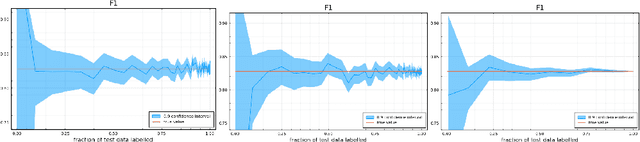
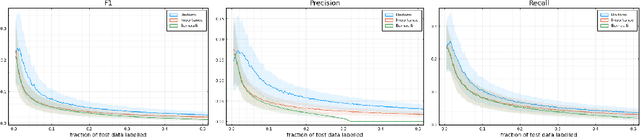
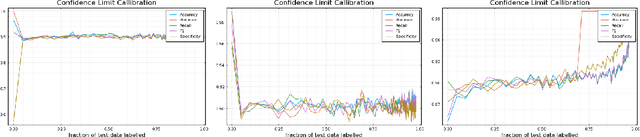
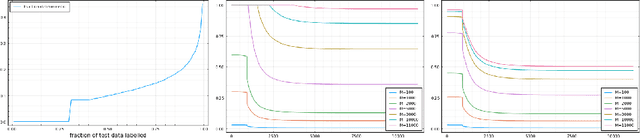
Labelling data is a major practical bottleneck in training and testing classifiers. Given a collection of unlabelled data points, we address how to select which subset to label to best estimate test metrics such as accuracy, $F_1$ score or micro/macro $F_1$. We consider two sampling based approaches, namely the well-known Importance Sampling and we introduce a novel application of Poisson Sampling. For both approaches we derive the minimal error sampling distributions and how to approximate and use them to form estimators and confidence intervals. We show that Poisson Sampling outperforms Importance Sampling both theoretically and experimentally.
One-Shot Learning in Discriminative Neural Networks
Jul 18, 2017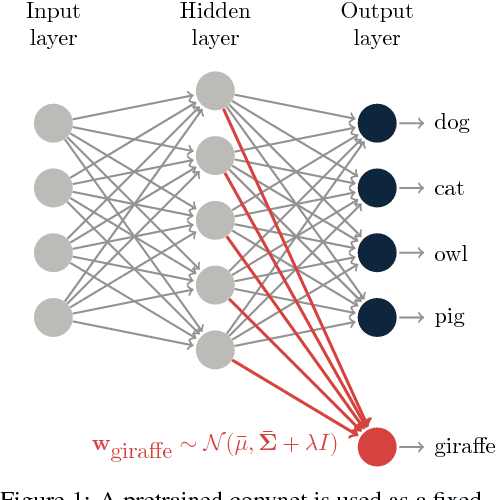
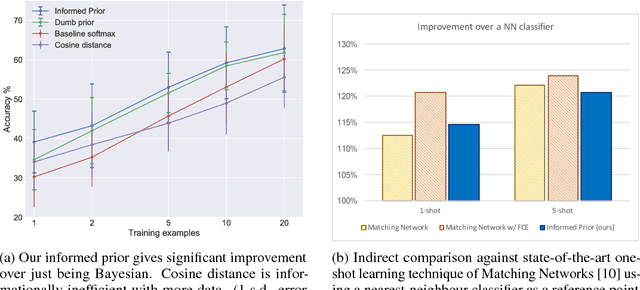
We consider the task of one-shot learning of visual categories. In this paper we explore a Bayesian procedure for updating a pretrained convnet to classify a novel image category for which data is limited. We decompose this convnet into a fixed feature extractor and softmax classifier. We assume that the target weights for the new task come from the same distribution as the pretrained softmax weights, which we model as a multivariate Gaussian. By using this as a prior for the new weights, we demonstrate competitive performance with state-of-the-art methods whilst also being consistent with 'normal' methods for training deep networks on large data.