 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnveiling the Potential of Text in High-Dimensional Time Series Forecasting
Jan 13, 2025


Time series forecasting has traditionally focused on univariate and multivariate numerical data, often overlooking the benefits of incorporating multimodal information, particularly textual data. In this paper, we propose a novel framework that integrates time series models with Large Language Models to improve high-dimensional time series forecasting. Inspired by multimodal models, our method combines time series and textual data in the dual-tower structure. This fusion of information creates a comprehensive representation, which is then processed through a linear layer to generate the final forecast. Extensive experiments demonstrate that incorporating text enhances high-dimensional time series forecasting performance. This work paves the way for further research in multimodal time series forecasting.
Scalable and Effective Negative Sample Generation for Hyperedge Prediction
Nov 19, 2024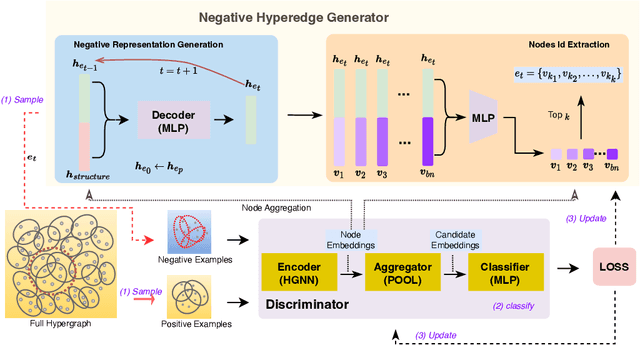
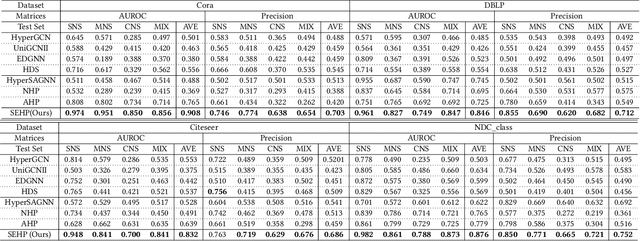
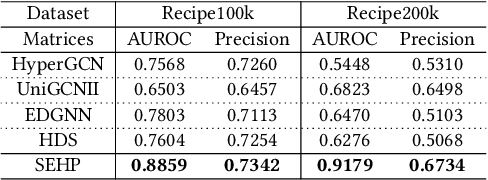
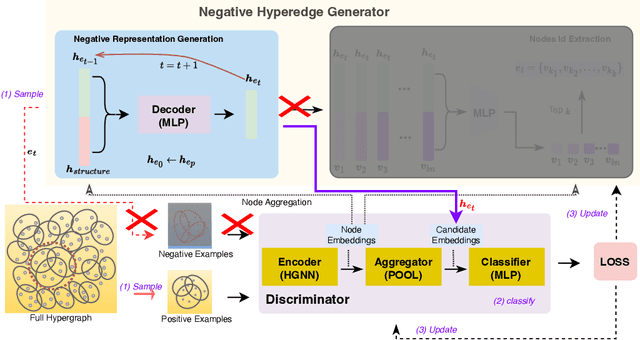
Hyperedge prediction is crucial in hypergraph analysis for understanding complex multi-entity interactions in various web-based applications, including social networks and e-commerce systems. Traditional methods often face difficulties in generating high-quality negative samples due to the imbalance between positive and negative instances. To address this, we present the Scalable and Effective Negative Sample Generation for Hyperedge Prediction (SEHP) framework, which utilizes diffusion models to tackle these challenges. SEHP employs a boundary-aware loss function that iteratively refines negative samples, moving them closer to decision boundaries to improve classification performance. SEHP samples positive instances to form sub-hypergraphs for scalable batch processing. By using structural information from sub-hypergraphs as conditions within the diffusion process, SEHP effectively captures global patterns. To enhance efficiency, our approach operates directly in latent space, avoiding the need for discrete ID generation and resulting in significant speed improvements while preserving accuracy. Extensive experiments show that SEHP outperforms existing methods in accuracy, efficiency, and scalability, representing a substantial advancement in hyperedge prediction techniques. Our code is available here.
Scalable Frame-based Construction of Sociocultural NormBases for Socially-Aware Dialogues
Oct 04, 2024


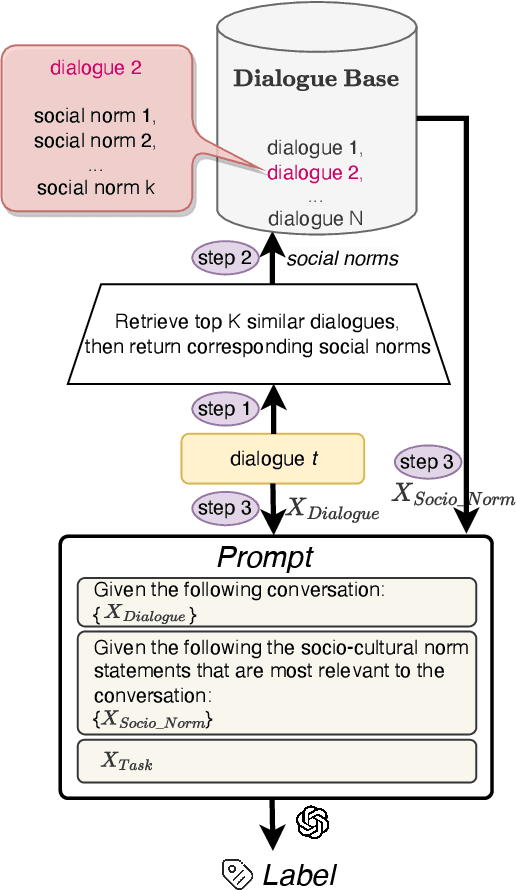
Sociocultural norms serve as guiding principles for personal conduct in social interactions, emphasizing respect, cooperation, and appropriate behavior, which is able to benefit tasks including conversational information retrieval, contextual information retrieval and retrieval-enhanced machine learning. We propose a scalable approach for constructing a Sociocultural Norm (SCN) Base using Large Language Models (LLMs) for socially aware dialogues. We construct a comprehensive and publicly accessible Chinese Sociocultural NormBase. Our approach utilizes socially aware dialogues, enriched with contextual frames, as the primary data source to constrain the generating process and reduce the hallucinations. This enables extracting of high-quality and nuanced natural-language norm statements, leveraging the pragmatic implications of utterances with respect to the situation. As real dialogue annotated with gold frames are not readily available, we propose using synthetic data. Our empirical results show: (i) the quality of the SCNs derived from synthetic data is comparable to that from real dialogues annotated with gold frames, and (ii) the quality of the SCNs extracted from real data, annotated with either silver (predicted) or gold frames, surpasses that without the frame annotations. We further show the effectiveness of the extracted SCNs in a RAG-based (Retrieval-Augmented Generation) model to reason about multiple downstream dialogue tasks.
* 17 pages
Scalable Transformer for High Dimensional Multivariate Time Series Forecasting
Aug 08, 2024



Deep models for Multivariate Time Series (MTS) forecasting have recently demonstrated significant success. Channel-dependent models capture complex dependencies that channel-independent models cannot capture. However, the number of channels in real-world applications outpaces the capabilities of existing channel-dependent models, and contrary to common expectations, some models underperform the channel-independent models in handling high-dimensional data, which raises questions about the performance of channel-dependent models. To address this, our study first investigates the reasons behind the suboptimal performance of these channel-dependent models on high-dimensional MTS data. Our analysis reveals that two primary issues lie in the introduced noise from unrelated series that increases the difficulty of capturing the crucial inter-channel dependencies, and challenges in training strategies due to high-dimensional data. To address these issues, we propose STHD, the Scalable Transformer for High-Dimensional Multivariate Time Series Forecasting. STHD has three components: a) Relation Matrix Sparsity that limits the noise introduced and alleviates the memory issue; b) ReIndex applied as a training strategy to enable a more flexible batch size setting and increase the diversity of training data; and c) Transformer that handles 2-D inputs and captures channel dependencies. These components jointly enable STHD to manage the high-dimensional MTS while maintaining computational feasibility. Furthermore, experimental results show STHD's considerable improvement on three high-dimensional datasets: Crime-Chicago, Wiki-People, and Traffic. The source code and dataset are publicly available https://github.com/xinzzzhou/ScalableTransformer4HighDimensionMTSF.git.
RENOVI: A Benchmark Towards Remediating Norm Violations in Socio-Cultural Conversations
Feb 17, 2024



Norm violations occur when individuals fail to conform to culturally accepted behaviors, which may lead to potential conflicts. Remediating norm violations requires social awareness and cultural sensitivity of the nuances at play. To equip interactive AI systems with a remediation ability, we offer ReNoVi - a large-scale corpus of 9,258 multi-turn dialogues annotated with social norms, as well as define a sequence of tasks to help understand and remediate norm violations step by step. ReNoVi consists of two parts: 512 human-authored dialogues (real data), and 8,746 synthetic conversations generated by ChatGPT through prompt learning. While collecting sufficient human-authored data is costly, synthetic conversations provide suitable amounts of data to help mitigate the scarcity of training data, as well as the chance to assess the alignment between LLMs and humans in the awareness of social norms. We thus harness the power of ChatGPT to generate synthetic training data for our task. To ensure the quality of both human-authored and synthetic data, we follow a quality control protocol during data collection. Our experimental results demonstrate the importance of remediating norm violations in socio-cultural conversations, as well as the improvement in performance obtained from synthetic data.
Hypergraph Node Representation Learning with One-Stage Message Passing
Dec 01, 2023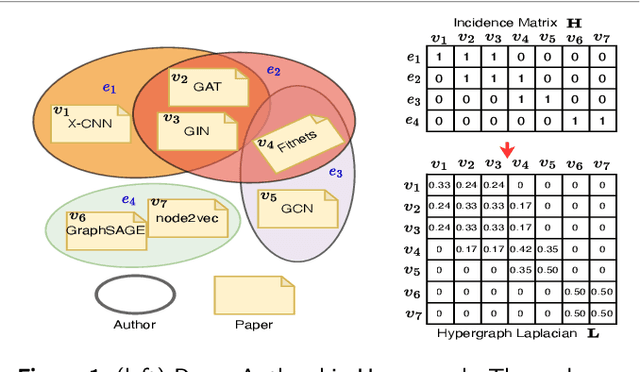
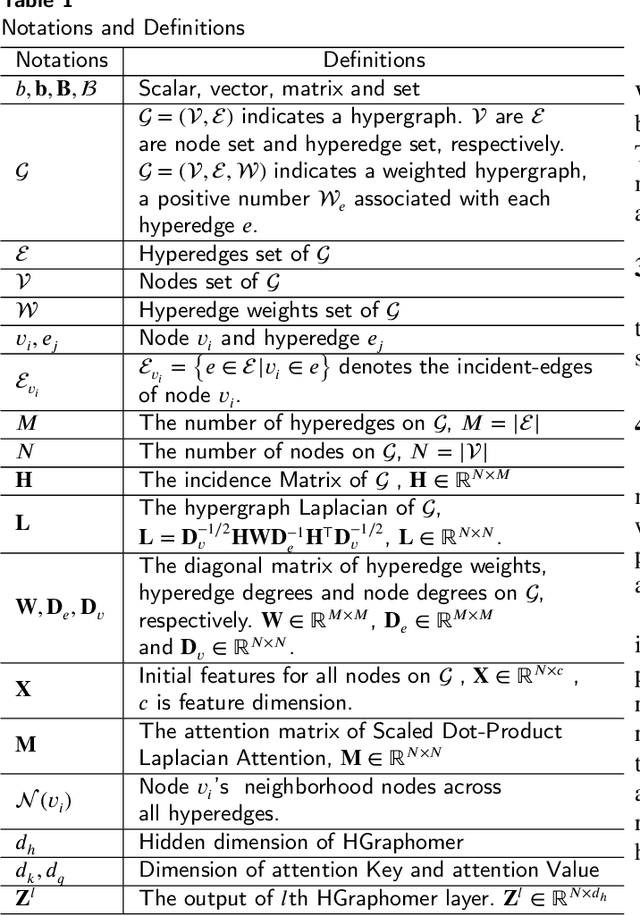
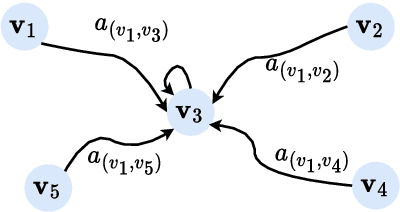
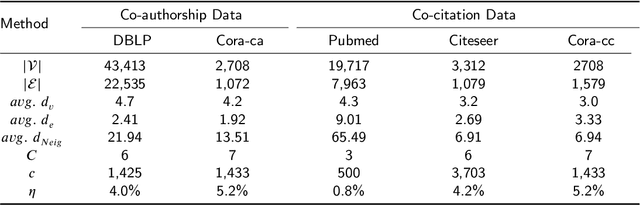
Hypergraphs as an expressive and general structure have attracted considerable attention from various research domains. Most existing hypergraph node representation learning techniques are based on graph neural networks, and thus adopt the two-stage message passing paradigm (i.e. node -> hyperedge -> node). This paradigm only focuses on local information propagation and does not effectively take into account global information, resulting in less optimal representations. Our theoretical analysis of representative two-stage message passing methods shows that, mathematically, they model different ways of local message passing through hyperedges, and can be unified into one-stage message passing (i.e. node -> node). However, they still only model local information. Motivated by this theoretical analysis, we propose a novel one-stage message passing paradigm to model both global and local information propagation for hypergraphs. We integrate this paradigm into HGraphormer, a Transformer-based framework for hypergraph node representation learning. HGraphormer injects the hypergraph structure information (local information) into Transformers (global information) by combining the attention matrix and hypergraph Laplacian. Extensive experiments demonstrate that HGraphormer outperforms recent hypergraph learning methods on five representative benchmark datasets on the semi-supervised hypernode classification task, setting new state-of-the-art performance, with accuracy improvements between 2.52% and 6.70%. Our code and datasets are available.
NormMark: A Weakly Supervised Markov Model for Socio-cultural Norm Discovery
May 26, 2023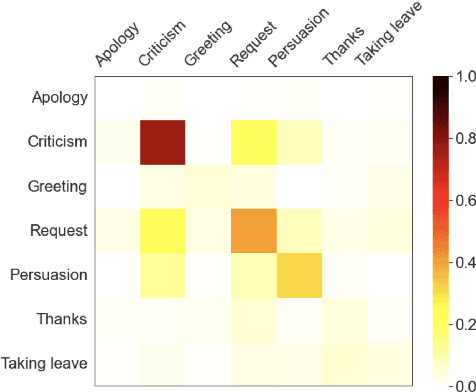
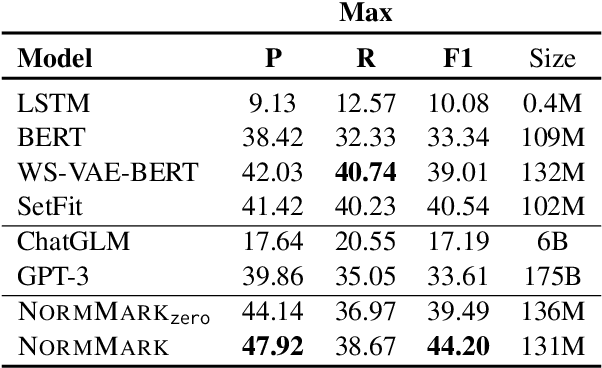
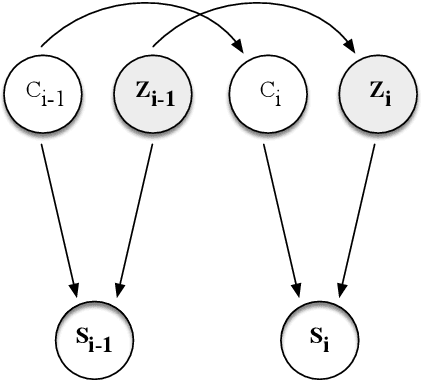
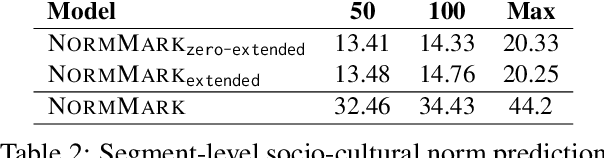
Norms, which are culturally accepted guidelines for behaviours, can be integrated into conversational models to generate utterances that are appropriate for the socio-cultural context. Existing methods for norm recognition tend to focus only on surface-level features of dialogues and do not take into account the interactions within a conversation. To address this issue, we propose NormMark, a probabilistic generative Markov model to carry the latent features throughout a dialogue. These features are captured by discrete and continuous latent variables conditioned on the conversation history, and improve the model's ability in norm recognition. The model is trainable on weakly annotated data using the variational technique. On a dataset with limited norm annotations, we show that our approach achieves higher F1 score, outperforming current state-of-the-art methods, including GPT3.