 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRare Event Early Detection: A Dataset of Sepsis Onset for Critically Ill Trauma Patients
Feb 03, 2026Sepsis is a major public health concern due to its high morbidity, mortality, and cost. Its clinical outcome can be substantially improved through early detection and timely intervention. By leveraging publicly available datasets, machine learning (ML) has driven advances in both research and clinical practice. However, existing public datasets consider ICU patients (Intensive Care Unit) as a uniform group and neglect the potential challenges presented by critically ill trauma patients in whom injury-related inflammation and organ dysfunction can overlap with the clinical features of sepsis. We propose that a targeted identification of post-traumatic sepsis is necessary in order to develop methods for early detection. Therefore, we introduce a publicly available standardized post-trauma sepsis onset dataset extracted, relabeled using standardized post-trauma clinical facts, and validated from MIMIC-III. Furthermore, we frame early detection of post-trauma sepsis onset according to clinical workflow in ICUs in a daily basis resulting in a new rare event detection problem. We then establish a general benchmark through comprehensive experiments, which shows the necessity of further advancements using this new dataset. The data code is available at https://github.com/ML4UWHealth/SepsisOnset_TraumaCohort.git.
Ultra-imbalanced classification guided by statistical information
Sep 06, 2024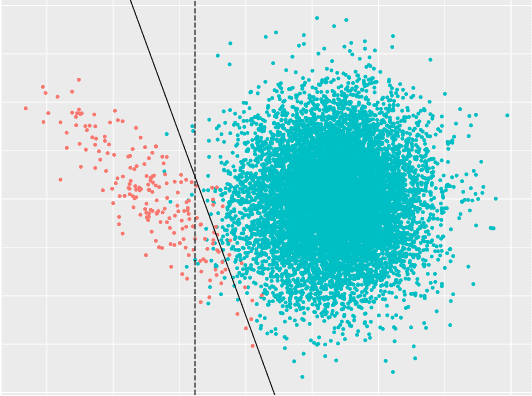
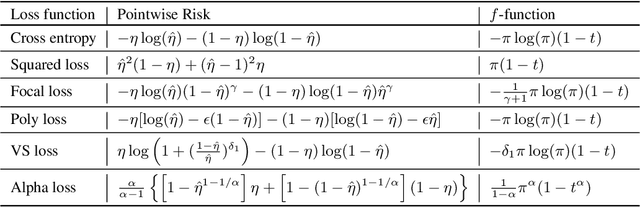
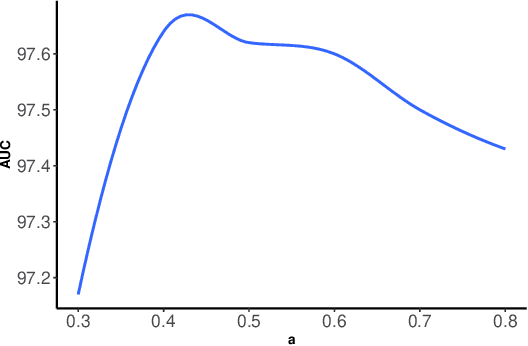
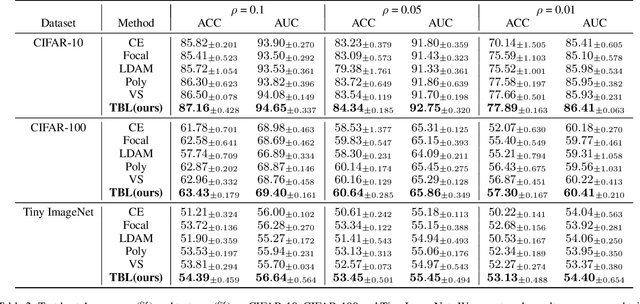
Imbalanced data are frequently encountered in real-world classification tasks. Previous works on imbalanced learning mostly focused on learning with a minority class of few samples. However, the notion of imbalance also applies to cases where the minority class contains abundant samples, which is usually the case for industrial applications like fraud detection in the area of financial risk management. In this paper, we take a population-level approach to imbalanced learning by proposing a new formulation called \emph{ultra-imbalanced classification} (UIC). Under UIC, loss functions behave differently even if infinite amount of training samples are available. To understand the intrinsic difficulty of UIC problems, we borrow ideas from information theory and establish a framework to compare different loss functions through the lens of statistical information. A novel learning objective termed Tunable Boosting Loss is developed which is provably resistant against data imbalance under UIC, as well as being empirically efficient verified by extensive experimental studies on both public and industrial datasets.