 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMSDformer: Multi-scale Discrete Transformer For Time Series Generation
May 20, 2025Discrete Token Modeling (DTM), which employs vector quantization techniques, has demonstrated remarkable success in modeling non-natural language modalities, particularly in time series generation. While our prior work SDformer established the first DTM-based framework to achieve state-of-the-art performance in this domain, two critical limitations persist in existing DTM approaches: 1) their inability to capture multi-scale temporal patterns inherent to complex time series data, and 2) the absence of theoretical foundations to guide model optimization. To address these challenges, we proposes a novel multi-scale DTM-based time series generation method, called Multi-Scale Discrete Transformer (MSDformer). MSDformer employs a multi-scale time series tokenizer to learn discrete token representations at multiple scales, which jointly characterize the complex nature of time series data. Subsequently, MSDformer applies a multi-scale autoregressive token modeling technique to capture the multi-scale patterns of time series within the discrete latent space. Theoretically, we validate the effectiveness of the DTM method and the rationality of MSDformer through the rate-distortion theorem. Comprehensive experiments demonstrate that MSDformer significantly outperforms state-of-the-art methods. Both theoretical analysis and experimental results demonstrate that incorporating multi-scale information and modeling multi-scale patterns can substantially enhance the quality of generated time series in DTM-based approaches. The code will be released upon acceptance.
TS-LIF: A Temporal Segment Spiking Neuron Network for Time Series Forecasting
Mar 07, 2025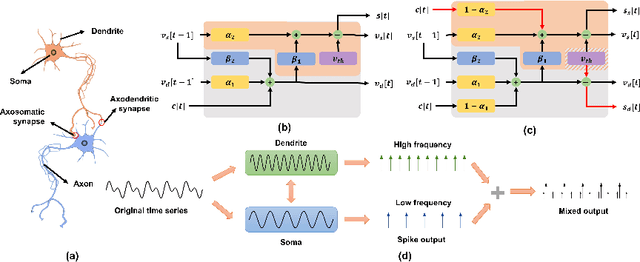



Spiking Neural Networks (SNNs) offer a promising, biologically inspired approach for processing spatiotemporal data, particularly for time series forecasting. However, conventional neuron models like the Leaky Integrate-and-Fire (LIF) struggle to capture long-term dependencies and effectively process multi-scale temporal dynamics. To overcome these limitations, we introduce the Temporal Segment Leaky Integrate-and-Fire (TS-LIF) model, featuring a novel dual-compartment architecture. The dendritic and somatic compartments specialize in capturing distinct frequency components, providing functional heterogeneity that enhances the neuron's ability to process both low- and high-frequency information. Furthermore, the newly introduced direct somatic current injection reduces information loss during intra-neuronal transmission, while dendritic spike generation improves multi-scale information extraction. We provide a theoretical stability analysis of the TS-LIF model and explain how each compartment contributes to distinct frequency response characteristics. Experimental results show that TS-LIF outperforms traditional SNNs in time series forecasting, demonstrating better accuracy and robustness, even with missing data. TS-LIF advances the application of SNNs in time-series forecasting, providing a biologically inspired approach that captures complex temporal dynamics and offers potential for practical implementation in diverse forecasting scenarios. The source code is available at https://github.com/kkking-kk/TS-LIF.
HDT: Hierarchical Discrete Transformer for Multivariate Time Series Forecasting
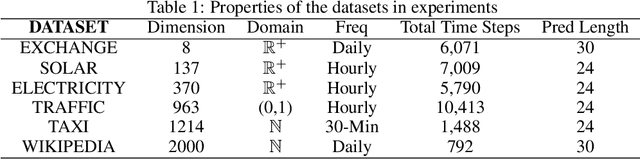
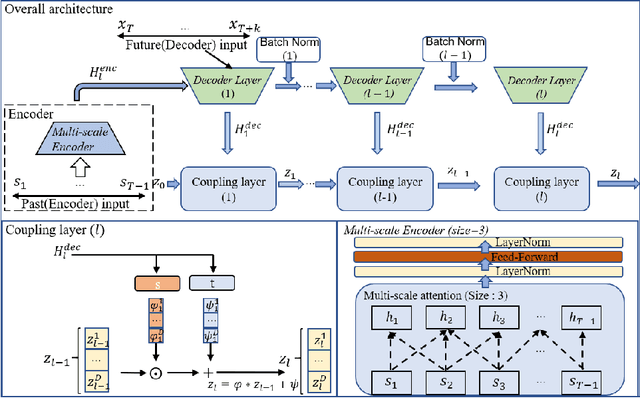
Feb 12, 2025Generative models have gained significant attention in multivariate time series forecasting (MTS), particularly due to their ability to generate high-fidelity samples. Forecasting the probability distribution of multivariate time series is a challenging yet practical task. Although some recent attempts have been made to handle this task, two major challenges persist: 1) some existing generative methods underperform in high-dimensional multivariate time series forecasting, which is hard to scale to higher dimensions; 2) the inherent high-dimensional multivariate attributes constrain the forecasting lengths of existing generative models. In this paper, we point out that discrete token representations can model high-dimensional MTS with faster inference time, and forecasting the target with long-term trends of itself can extend the forecasting length with high accuracy. Motivated by this, we propose a vector quantized framework called Hierarchical Discrete Transformer (HDT) that models time series into discrete token representations with l2 normalization enhanced vector quantized strategy, in which we transform the MTS forecasting into discrete tokens generation. To address the limitations of generative models in long-term forecasting, we propose a hierarchical discrete Transformer. This model captures the discrete long-term trend of the target at the low level and leverages this trend as a condition to generate the discrete representation of the target at the high level that introduces the features of the target itself to extend the forecasting length in high-dimensional MTS. Extensive experiments on five popular MTS datasets verify the effectiveness of our proposed method.
Multi-scale Attention Flow for Probabilistic Time Series Forecasting
May 16, 2022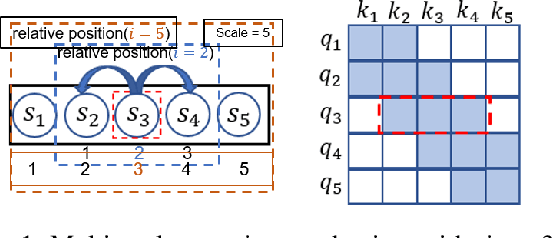
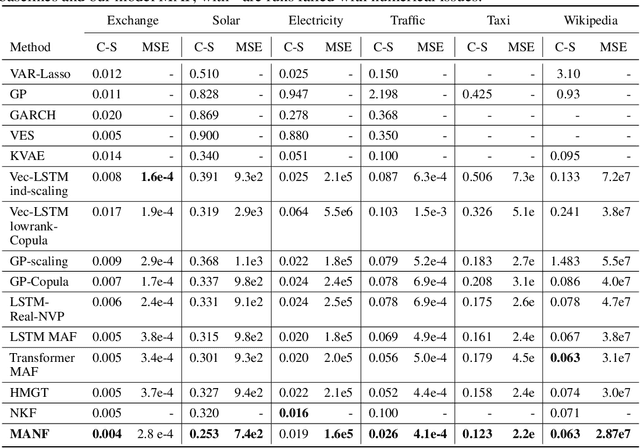
The probability prediction of multivariate time series is a notoriously challenging but practical task. On the one hand, the challenge is how to effectively capture the cross-series correlations between interacting time series, to achieve accurate distribution modeling. On the other hand, we should consider how to capture the contextual information within time series more accurately to model multivariate temporal dynamics of time series. In this work, we proposed a novel non-autoregressive deep learning model, called Multi-scale Attention Normalizing Flow(MANF), where we integrate multi-scale attention and relative position information and the multivariate data distribution is represented by the conditioned normalizing flow. Additionally, compared with autoregressive modeling methods, our model avoids the influence of cumulative error and does not increase the time complexity. Extensive experiments demonstrate that our model achieves state-of-the-art performance on many popular multivariate datasets.