 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMarkovScale: Towards Optimal Sequential Scaling at Inference Time
Feb 01, 2026Sequential scaling is a prominent inference-time scaling paradigm, yet its performance improvements are typically modest and not well understood, largely due to the prevalence of heuristic, non-principled approaches that obscure clear optimality bounds. To address this, we propose a principled framework that models sequential scaling as a two-state Markov process. This approach reveals the underlying properties of sequential scaling and yields closed-form solutions for essential aspects, such as the specific conditions under which accuracy is improved and the theoretical upper, neutral, and lower performance bounds. Leveraging this formulation, we develop MarkovScale, a practical system that applies these optimality criteria to achieve a theoretically grounded balance between accuracy and efficiency. Comprehensive experiments across 3 backbone LLMs, 5 benchmarks, and over 20 configurations show that MarkovScale consistently outperforms state-of-the-art parallel and sequential scaling methods, representing a significant step toward optimal and resource-efficient inference in LLMs. The source code will be open upon acceptance at https://open-upon-acceptance.
PILD: Physics-Informed Learning via Diffusion
Jan 29, 2026Diffusion models have emerged as powerful generative tools for modeling complex data distributions, yet their purely data-driven nature limits applicability in practical engineering and scientific problems where physical laws need to be followed. This paper proposes Physics-Informed Learning via Diffusion (PILD), a framework that unifies diffusion modeling and first-principles physical constraints by introducing a virtual residual observation sampled from a Laplace distribution to supervise generation during training. To further integrate physical laws, a conditional embedding module is incorporated to inject physical information into the denoising network at multiple layers, ensuring consistent guidance throughout the diffusion process. The proposed PILD framework is concise, modular, and broadly applicable to problems governed by ordinary differential equations, partial differential equations, as well as algebraic equations or inequality constraints. Extensive experiments across engineering and scientific tasks including estimating vehicle trajectories, tire forces, Darcy flow and plasma dynamics, demonstrate that our PILD substantially improves accuracy, stability, and generalization over existing physics-informed and diffusion-based baselines.
PET Head Motion Estimation Using Supervised Deep Learning with Attention
Oct 14, 2025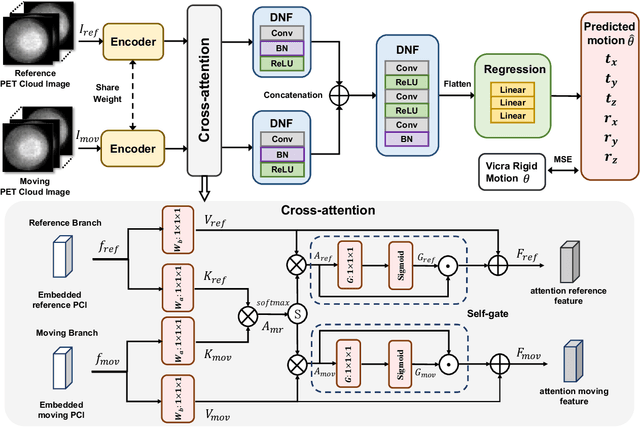
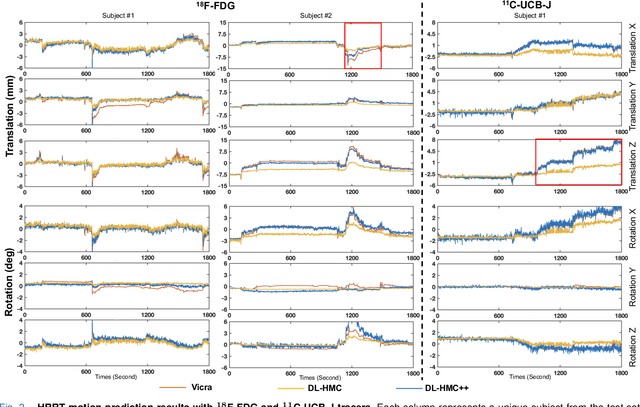
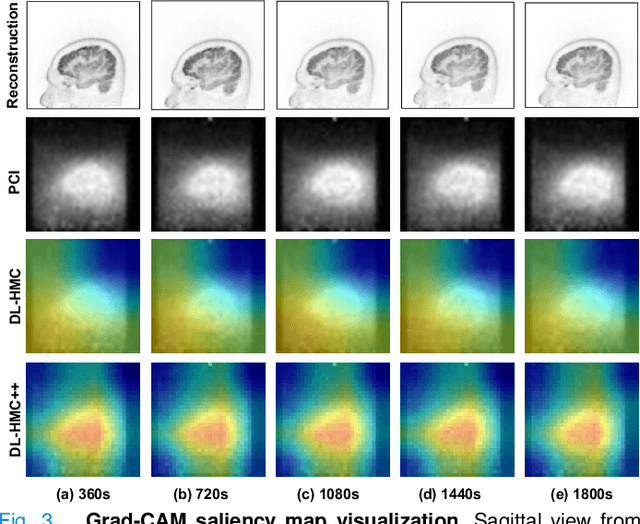
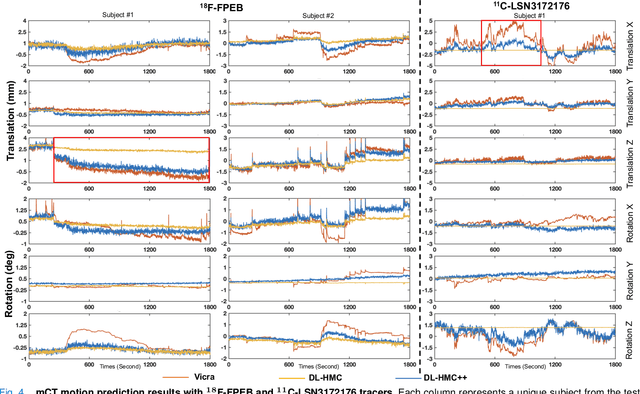
Head movement poses a significant challenge in brain positron emission tomography (PET) imaging, resulting in image artifacts and tracer uptake quantification inaccuracies. Effective head motion estimation and correction are crucial for precise quantitative image analysis and accurate diagnosis of neurological disorders. Hardware-based motion tracking (HMT) has limited applicability in real-world clinical practice. To overcome this limitation, we propose a deep-learning head motion correction approach with cross-attention (DL-HMC++) to predict rigid head motion from one-second 3D PET raw data. DL-HMC++ is trained in a supervised manner by leveraging existing dynamic PET scans with gold-standard motion measurements from external HMT. We evaluate DL-HMC++ on two PET scanners (HRRT and mCT) and four radiotracers (18F-FDG, 18F-FPEB, 11C-UCB-J, and 11C-LSN3172176) to demonstrate the effectiveness and generalization of the approach in large cohort PET studies. Quantitative and qualitative results demonstrate that DL-HMC++ consistently outperforms state-of-the-art data-driven motion estimation methods, producing motion-free images with clear delineation of brain structures and reduced motion artifacts that are indistinguishable from gold-standard HMT. Brain region of interest standard uptake value analysis exhibits average difference ratios between DL-HMC++ and gold-standard HMT to be 1.2 plus-minus 0.5% for HRRT and 0.5 plus-minus 0.2% for mCT. DL-HMC++ demonstrates the potential for data-driven PET head motion correction to remove the burden of HMT, making motion correction accessible to clinical populations beyond research settings. The code is available at https://github.com/maxxxxxxcai/DL-HMC-TMI.
Damper-B-PINN: Damper Characteristics-Based Bayesian Physics-Informed Neural Network for Vehicle State Estimation
Feb 28, 2025



State estimation for Multi-Input Multi-Output (MIMO) systems with noise, such as vehicle chassis systems, presents a significant challenge due to the imperfect and complex relationship between inputs and outputs. To solve this problem, we design a Damper characteristics-based Bayesian Physics-Informed Neural Network (Damper-B-PINN). First, we introduce a neuron forward process inspired by the mechanical properties of dampers, which limits abrupt jumps in neuron values between epochs while maintaining search capability. Additionally, we apply an optimized Bayesian dropout layer to the MIMO system to enhance robustness against noise and prevent non-convergence issues. Physical information is incorporated into the loss function to serve as a physical prior for the neural network. The effectiveness of our Damper-B-PINN architecture is then validated across ten datasets and fourteen vehicle types, demonstrating superior accuracy, computational efficiency, and convergence in vehicle state estimation (i.e., dynamic wheel load) compared to other state-of-the-art benchmarks.