 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal-Horizon Social Robot Navigation in Heterogeneous Crowds
Feb 28, 2026Navigating social robots in dense, dynamic crowds is challenging due to environmental uncertainty and complex human-robot interactions. While Model Predictive Control (MPC) offers strong real-time performance, its reliance on a fixed prediction horizon limits adaptability to changing environments and social dynamics. Furthermore, most MPC approaches treat pedestrians as homogeneous obstacles, ignoring social heterogeneity and cooperative or adversarial interactions, which often causes the Frozen Robot Problem in partially observable real-world environments. In this paper, we identify the planning horizon as a socially conditioned decision variable rather than a fixed design choice. Building on this insight, we propose an optimal-horizon social navigation framework that optimizes MPC foresight online according to inferred social context. A spatio-temporal Transformer infers pedestrian cooperation attributes from local trajectory observations, which serve as social priors for a reinforcement learning policy that optimally selects the prediction horizon under a task-driven objective. The resulting horizon-aware MPC incorporates socially conditioned safety constraints to balance navigation efficiency and interaction safety. Extensive simulations and real-world robot experiments demonstrate that optimal foresight selection is critical for robust social navigation in partially observable crowds. Compared to state-of-the-art baselines, the proposed approach achieves a 6.8\% improvement in success rate, reduces collisions by 50\%, and shortens navigation time by 19\%, with a low timeout rate of 0.8\%, validating the necessity of socially optimal planning horizons for efficient and safe robot navigation in crowded environments. Code and videos are available at Under Review.
PET Head Motion Estimation Using Supervised Deep Learning with Attention
Oct 14, 2025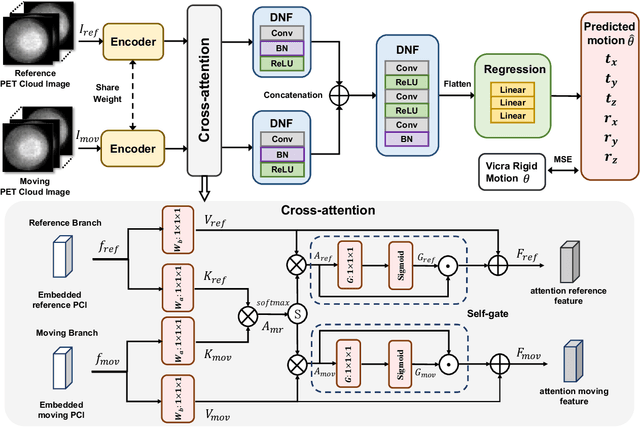
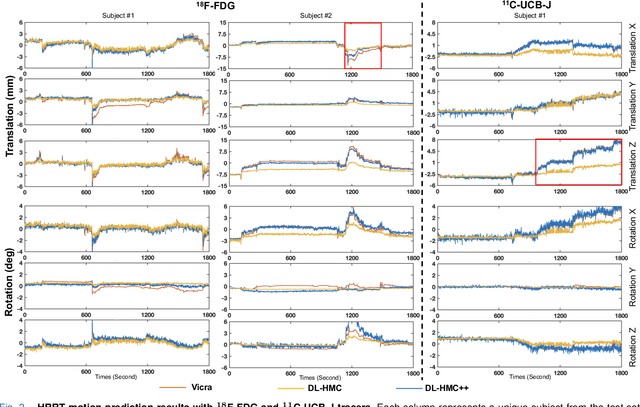
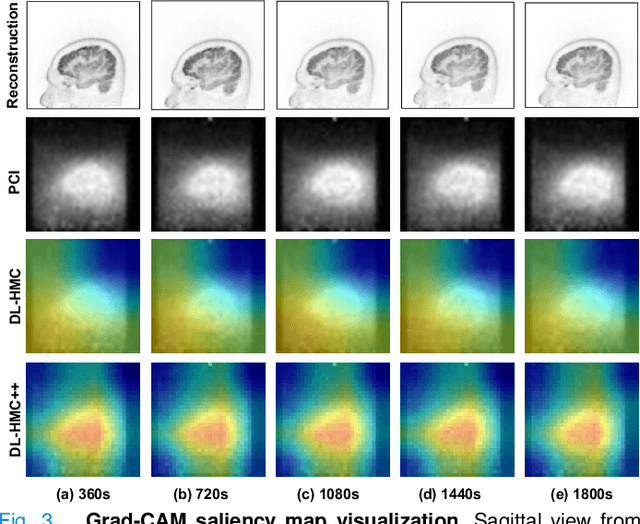
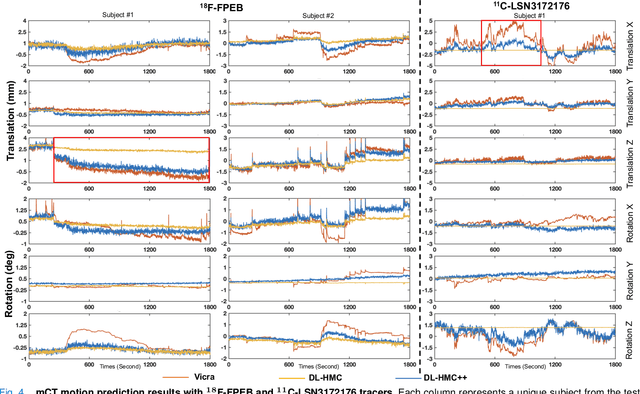
Head movement poses a significant challenge in brain positron emission tomography (PET) imaging, resulting in image artifacts and tracer uptake quantification inaccuracies. Effective head motion estimation and correction are crucial for precise quantitative image analysis and accurate diagnosis of neurological disorders. Hardware-based motion tracking (HMT) has limited applicability in real-world clinical practice. To overcome this limitation, we propose a deep-learning head motion correction approach with cross-attention (DL-HMC++) to predict rigid head motion from one-second 3D PET raw data. DL-HMC++ is trained in a supervised manner by leveraging existing dynamic PET scans with gold-standard motion measurements from external HMT. We evaluate DL-HMC++ on two PET scanners (HRRT and mCT) and four radiotracers (18F-FDG, 18F-FPEB, 11C-UCB-J, and 11C-LSN3172176) to demonstrate the effectiveness and generalization of the approach in large cohort PET studies. Quantitative and qualitative results demonstrate that DL-HMC++ consistently outperforms state-of-the-art data-driven motion estimation methods, producing motion-free images with clear delineation of brain structures and reduced motion artifacts that are indistinguishable from gold-standard HMT. Brain region of interest standard uptake value analysis exhibits average difference ratios between DL-HMC++ and gold-standard HMT to be 1.2 plus-minus 0.5% for HRRT and 0.5 plus-minus 0.2% for mCT. DL-HMC++ demonstrates the potential for data-driven PET head motion correction to remove the burden of HMT, making motion correction accessible to clinical populations beyond research settings. The code is available at https://github.com/maxxxxxxcai/DL-HMC-TMI.
Discovering Common Information in Multi-view Data
Jun 21, 2024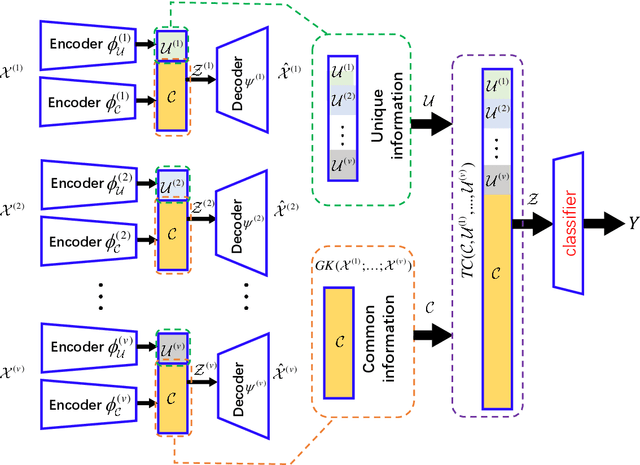
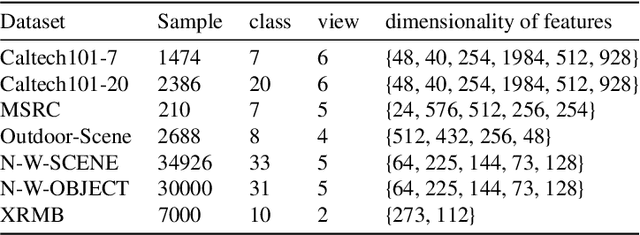
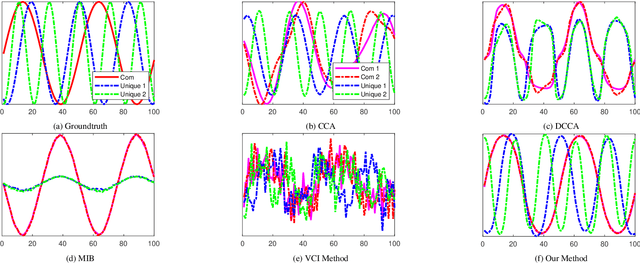
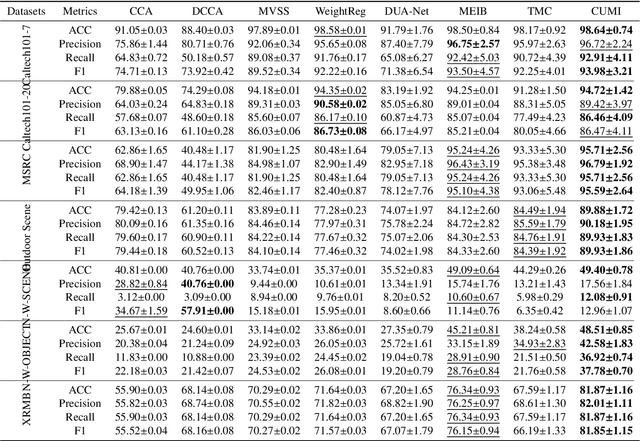
We introduce an innovative and mathematically rigorous definition for computing common information from multi-view data, drawing inspiration from G\'acs-K\"orner common information in information theory. Leveraging this definition, we develop a novel supervised multi-view learning framework to capture both common and unique information. By explicitly minimizing a total correlation term, the extracted common information and the unique information from each view are forced to be independent of each other, which, in turn, theoretically guarantees the effectiveness of our framework. To estimate information-theoretic quantities, our framework employs matrix-based R{\'e}nyi's $\alpha$-order entropy functional, which forgoes the need for variational approximation and distributional estimation in high-dimensional space. Theoretical proof is provided that our framework can faithfully discover both common and unique information from multi-view data. Experiments on synthetic and seven benchmark real-world datasets demonstrate the superior performance of our proposed framework over state-of-the-art approaches.
An automated framework for brain vessel centerline extraction from CTA images
Jan 13, 2024Accurate automated extraction of brain vessel centerlines from CTA images plays an important role in diagnosis and therapy of cerebrovascular diseases, such as stroke. However, this task remains challenging due to the complex cerebrovascular structure, the varying imaging quality, and vessel pathology effects. In this paper, we consider automatic lumen segmentation generation without additional annotation effort by physicians and more effective use of the generated lumen segmentation for improved centerline extraction performance. We propose an automated framework for brain vessel centerline extraction from CTA images. The framework consists of four major components: (1) pre-processing approaches that register CTA images with a CT atlas and divide these images into input patches, (2) lumen segmentation generation from annotated vessel centerlines using graph cuts and robust kernel regression, (3) a dual-branch topology-aware UNet (DTUNet) that can effectively utilize the annotated vessel centerlines and the generated lumen segmentation through a topology-aware loss (TAL) and its dual-branch design, and (4) post-processing approaches that skeletonize the predicted lumen segmentation. Extensive experiments on a multi-center dataset demonstrate that the proposed framework outperforms state-of-the-art methods in terms of average symmetric centerline distance (ASCD) and overlap (OV). Subgroup analyses further suggest that the proposed framework holds promise in clinical applications for stroke treatment. Code is publicly available at https://github.com/Liusj-gh/DTUNet.
InteractionNet: Joint Planning and Prediction for Autonomous Driving with Transformers
Sep 07, 2023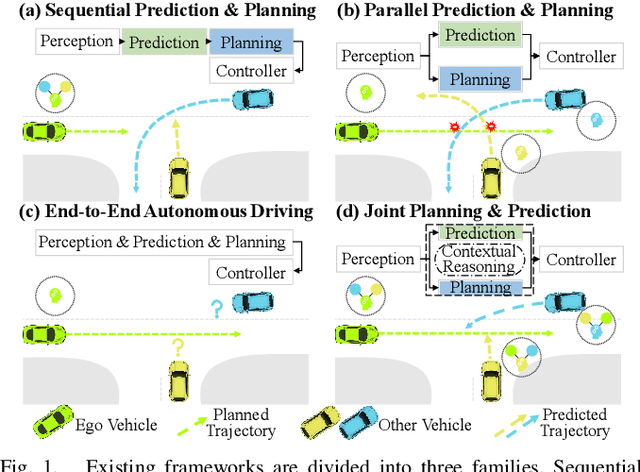
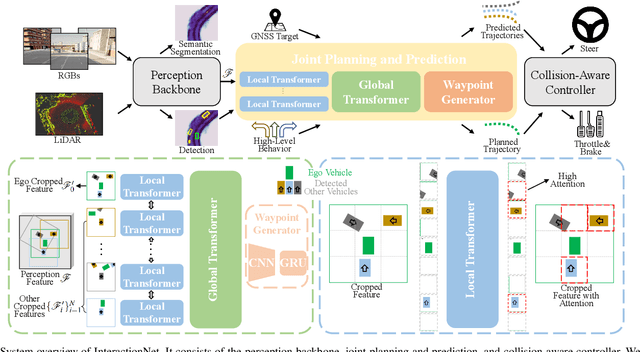
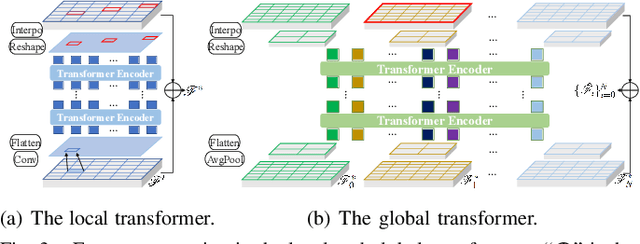

Planning and prediction are two important modules of autonomous driving and have experienced tremendous advancement recently. Nevertheless, most existing methods regard planning and prediction as independent and ignore the correlation between them, leading to the lack of consideration for interaction and dynamic changes of traffic scenarios. To address this challenge, we propose InteractionNet, which leverages transformer to share global contextual reasoning among all traffic participants to capture interaction and interconnect planning and prediction to achieve joint. Besides, InteractionNet deploys another transformer to help the model pay extra attention to the perceived region containing critical or unseen vehicles. InteractionNet outperforms other baselines in several benchmarks, especially in terms of safety, which benefits from the joint consideration of planning and forecasting. The code will be available at https://github.com/fujiawei0724/InteractionNet.
Multi-view Information Bottleneck Without Variational Approximation
Apr 22, 2022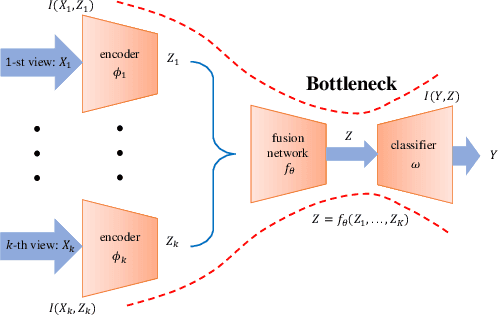
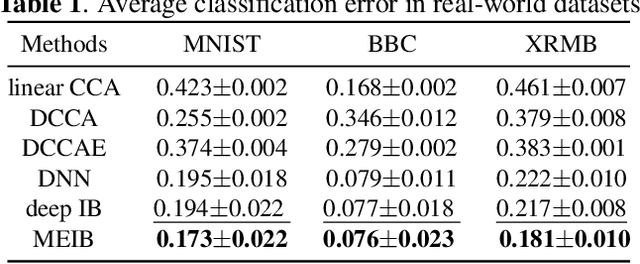
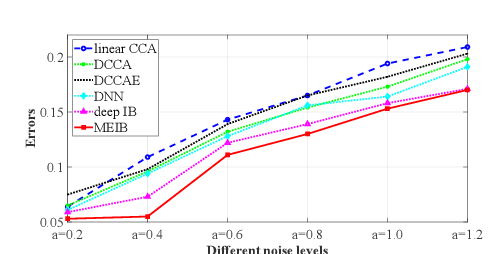
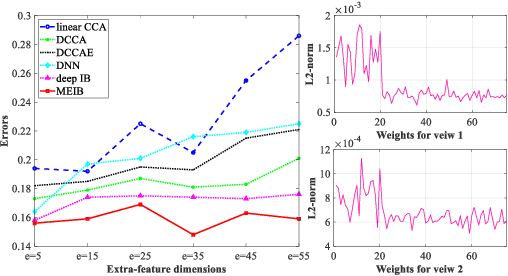
By "intelligently" fusing the complementary information across different views, multi-view learning is able to improve the performance of classification tasks. In this work, we extend the information bottleneck principle to a supervised multi-view learning scenario and use the recently proposed matrix-based R{\'e}nyi's $\alpha$-order entropy functional to optimize the resulting objective directly, without the necessity of variational approximation or adversarial training. Empirical results in both synthetic and real-world datasets suggest that our method enjoys improved robustness to noise and redundant information in each view, especially given limited training samples. Code is available at~\url{https://github.com/archy666/MEIB}.