 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOccluNet: Spatio-Temporal Deep Learning for Occlusion Detection on DSA
Aug 19, 2025Accurate detection of vascular occlusions during endovascular thrombectomy (EVT) is critical in acute ischemic stroke (AIS). Interpretation of digital subtraction angiography (DSA) sequences poses challenges due to anatomical complexity and time constraints. This work proposes OccluNet, a spatio-temporal deep learning model that integrates YOLOX, a single-stage object detector, with transformer-based temporal attention mechanisms to automate occlusion detection in DSA sequences. We compared OccluNet with a YOLOv11 baseline trained on either individual DSA frames or minimum intensity projections. Two spatio-temporal variants were explored for OccluNet: pure temporal attention and divided space-time attention. Evaluation on DSA images from the MR CLEAN Registry revealed the model's capability to capture temporally consistent features, achieving precision and recall of 89.02% and 74.87%, respectively. OccluNet significantly outperformed the baseline models, and both attention variants attained similar performance. Source code is available at https://github.com/anushka-kore/OccluNet.git
An automated framework for brain vessel centerline extraction from CTA images
Jan 13, 2024Accurate automated extraction of brain vessel centerlines from CTA images plays an important role in diagnosis and therapy of cerebrovascular diseases, such as stroke. However, this task remains challenging due to the complex cerebrovascular structure, the varying imaging quality, and vessel pathology effects. In this paper, we consider automatic lumen segmentation generation without additional annotation effort by physicians and more effective use of the generated lumen segmentation for improved centerline extraction performance. We propose an automated framework for brain vessel centerline extraction from CTA images. The framework consists of four major components: (1) pre-processing approaches that register CTA images with a CT atlas and divide these images into input patches, (2) lumen segmentation generation from annotated vessel centerlines using graph cuts and robust kernel regression, (3) a dual-branch topology-aware UNet (DTUNet) that can effectively utilize the annotated vessel centerlines and the generated lumen segmentation through a topology-aware loss (TAL) and its dual-branch design, and (4) post-processing approaches that skeletonize the predicted lumen segmentation. Extensive experiments on a multi-center dataset demonstrate that the proposed framework outperforms state-of-the-art methods in terms of average symmetric centerline distance (ASCD) and overlap (OV). Subgroup analyses further suggest that the proposed framework holds promise in clinical applications for stroke treatment. Code is publicly available at https://github.com/Liusj-gh/DTUNet.
AngioMoCo: Learning-based Motion Correction in Cerebral Digital Subtraction Angiography
Oct 09, 2023Cerebral X-ray digital subtraction angiography (DSA) is the standard imaging technique for visualizing blood flow and guiding endovascular treatments. The quality of DSA is often negatively impacted by body motion during acquisition, leading to decreased diagnostic value. Time-consuming iterative methods address motion correction based on non-rigid registration, and employ sparse key points and non-rigidity penalties to limit vessel distortion. Recent methods alleviate subtraction artifacts by predicting the subtracted frame from the corresponding unsubtracted frame, but do not explicitly compensate for motion-induced misalignment between frames. This hinders the serial evaluation of blood flow, and often causes undesired vasculature and contrast flow alterations, leading to impeded usability in clinical practice. To address these limitations, we present AngioMoCo, a learning-based framework that generates motion-compensated DSA sequences from X-ray angiography. AngioMoCo integrates contrast extraction and motion correction, enabling differentiation between patient motion and intensity changes caused by contrast flow. This strategy improves registration quality while being substantially faster than iterative elastix-based methods. We demonstrate AngioMoCo on a large national multi-center dataset (MR CLEAN Registry) of clinically acquired angiographic images through comprehensive qualitative and quantitative analyses. AngioMoCo produces high-quality motion-compensated DSA, removing motion artifacts while preserving contrast flow. Code is publicly available at https://github.com/RuishengSu/AngioMoCo.
Spatio-Temporal U-Net for Cerebral Artery and Vein Segmentation in Digital Subtraction Angiography
Aug 03, 2022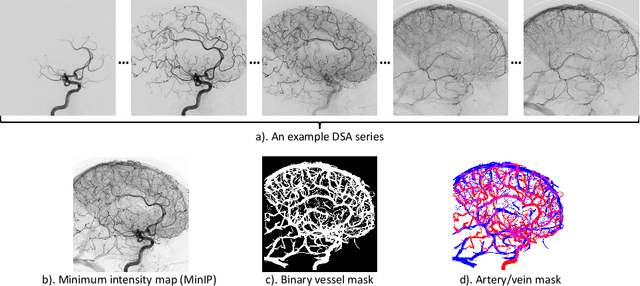
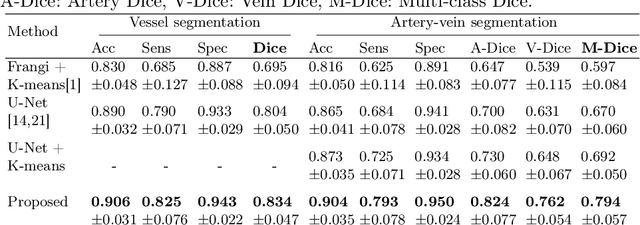
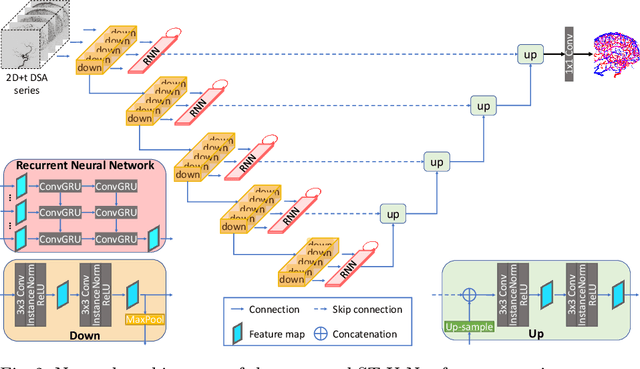
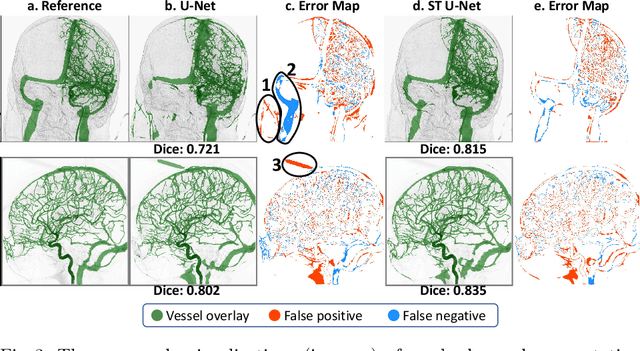
X-ray digital subtraction angiography (DSA) is widely used for vessel and/or flow visualization and interventional guidance during endovascular treatment of patients with a stroke or aneurysm. To assist in peri-operative decision making as well as post-operative prognosis, automatic DSA analysis algorithms are being developed to obtain relevant image-based information. Such analyses include detection of vascular disease, evaluation of perfusion based on time intensity curves (TIC), and quantitative biomarker extraction for automated treatment evaluation in endovascular thrombectomy. Methodologically, such vessel-based analysis tasks may be facilitated by automatic and accurate artery-vein segmentation algorithms. The present work describes to the best of our knowledge the first study that addresses automatic artery-vein segmentation in DSA using deep learning. We propose a novel spatio-temporal U-Net (ST U-Net) architecture which integrates convolutional gated recurrent units (ConvGRU) in the contracting branch of U-Net. The network encodes a 2D+t DSA series of variable length and decodes it into a 2D segmentation image. On a multi-center routinely acquired dataset, the proposed method significantly outperformed U-Net (P<0.001) and traditional Frangi-based K-means clustering (P$<$0.001). Particularly in artery-vein segmentation, ST U-Net achieved a Dice coefficient of 0.794, surpassing the existing state-of-the-art methods by a margin of 12\%-20\%. Code will be made publicly available upon acceptance.