 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmart Commander: A Hierarchical Reinforcement Learning Framework for Fleet-Level PHM Decision Optimization
Apr 08, 2026Decision-making in military aviation Prognostics and Health Management (PHM) faces significant challenges due to the "curse of dimensionality" in large-scale fleet operations, combined with sparse feedback and stochastic mission profiles. To address these issues, this paper proposes Smart Commander, a novel Hierarchical Reinforcement Learning (HRL) framework designed to optimize sequential maintenance and logistics decisions. The framework decomposes the complex control problem into a two-tier hierarchy: a strategic General Commander manages fleet-level availability and cost objectives, while tactical Operation Commanders execute specific actions for sortie generation, maintenance scheduling, and resource allocation. The proposed approach is validated within a custom-built, high-fidelity discrete-event simulation environment that captures the dynamics of aircraft configuration and support logistics.By integrating layered reward shaping with planning-enhanced neural networks, the method effectively addresses the difficulty of sparse and delayed rewards. Empirical evaluations demonstrate that Smart Commander significantly outperforms conventional monolithic Deep Reinforcement Learning (DRL) and rule-based baselines. Notably, it achieves a substantial reduction in training time while demonstrating superior scalability and robustness in failure-prone environments. These results highlight the potential of HRL as a reliable paradigm for next-generation intelligent fleet management.
Choosing How to Remember: Adaptive Memory Structures for LLM Agents
Feb 15, 2026Memory is critical for enabling large language model (LLM) based agents to maintain coherent behavior over long-horizon interactions. However, existing agent memory systems suffer from two key gaps: they rely on a one-size-fits-all memory structure and do not model memory structure selection as a context-adaptive decision, limiting their ability to handle heterogeneous interaction patterns and resulting in suboptimal performance. We propose a unified framework, FluxMem, that enables adaptive memory organization for LLM agents. Our framework equips agents with multiple complementary memory structures. It explicitly learns to select among these structures based on interaction-level features, using offline supervision derived from downstream response quality and memory utilization. To support robust long-horizon memory evolution, we further introduce a three-level memory hierarchy and a Beta Mixture Model-based probabilistic gate for distribution-aware memory fusion, replacing brittle similarity thresholds. Experiments on two long-horizon benchmarks, PERSONAMEM and LoCoMo, demonstrate that our method achieves average improvements of 9.18% and 6.14%.
Discovering Common Information in Multi-view Data
Jun 21, 2024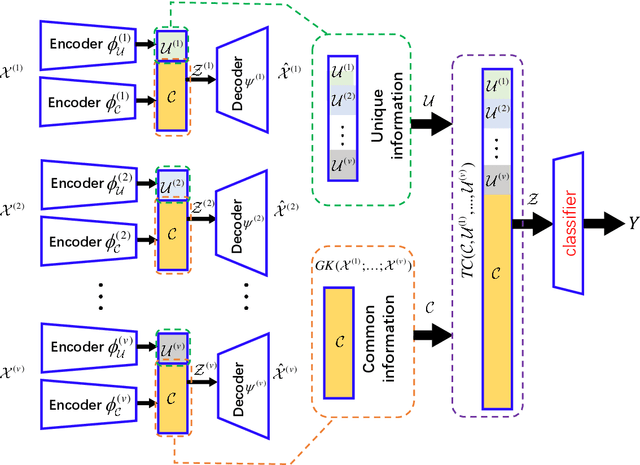
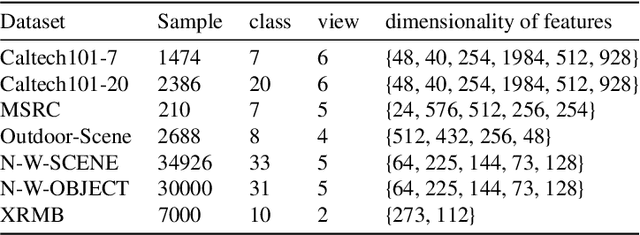
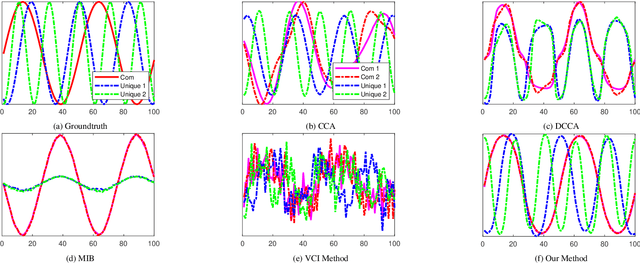
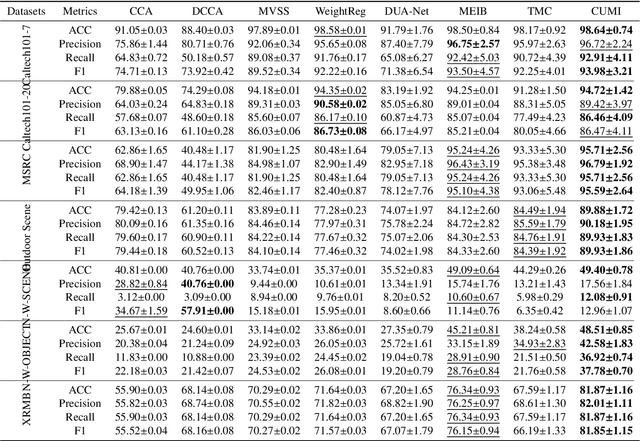
We introduce an innovative and mathematically rigorous definition for computing common information from multi-view data, drawing inspiration from G\'acs-K\"orner common information in information theory. Leveraging this definition, we develop a novel supervised multi-view learning framework to capture both common and unique information. By explicitly minimizing a total correlation term, the extracted common information and the unique information from each view are forced to be independent of each other, which, in turn, theoretically guarantees the effectiveness of our framework. To estimate information-theoretic quantities, our framework employs matrix-based R{\'e}nyi's $\alpha$-order entropy functional, which forgoes the need for variational approximation and distributional estimation in high-dimensional space. Theoretical proof is provided that our framework can faithfully discover both common and unique information from multi-view data. Experiments on synthetic and seven benchmark real-world datasets demonstrate the superior performance of our proposed framework over state-of-the-art approaches.
Generalized Cauchy-Schwarz Divergence and Its Deep Learning Applications
May 07, 2024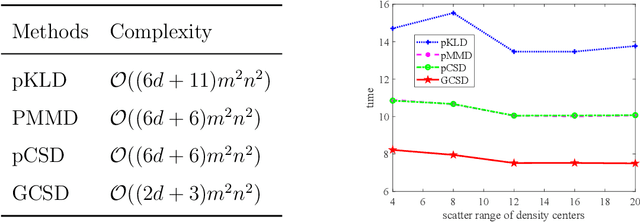
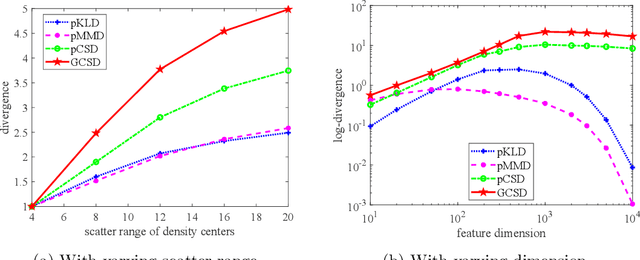
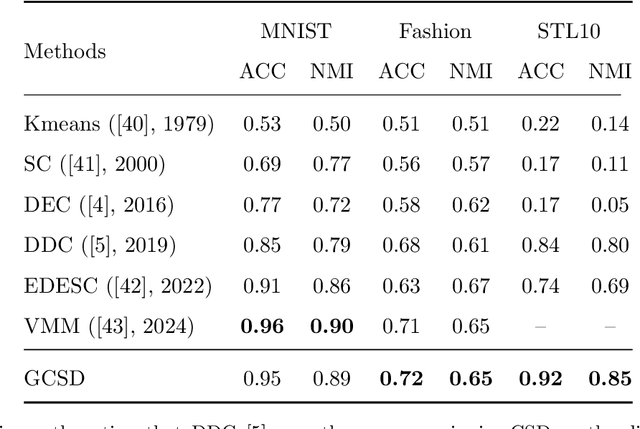
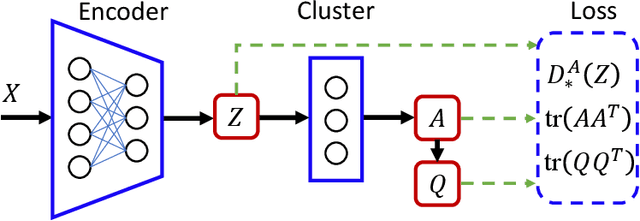
Divergence measures play a central role in machine learning and become increasingly essential in deep learning. However, valid and computationally efficient divergence measures for multiple (more than two) distributions are scarcely investigated. This becomes particularly crucial in areas where the simultaneous management of multiple distributions is both unavoidable and essential. Examples include clustering, multi-source domain adaptation or generalization, and multi-view learning, among others. Although calculating the mean of pairwise distances between any two distributions serves as a common way to quantify the total divergence among multiple distributions, it is crucial to acknowledge that this approach is not straightforward and requires significant computational resources. In this study, we introduce a new divergence measure for multiple distributions named the generalized Cauchy-Schwarz divergence (GCSD), which is inspired by the classic Cauchy-Schwarz divergence. Additionally, we provide a closed-form sample estimator based on kernel density estimation, making it convenient and straightforward to use in various machine-learning applications. Finally, we apply the proposed GCSD to two challenging machine learning tasks, namely deep learning-based clustering and the problem of multi-source domain adaptation. The experimental results showcase the impressive performance of GCSD in both tasks, highlighting its potential application in machine-learning areas that involve quantifying multiple distributions.
On the Adversarial Robustness of Generative Autoencoders in the Latent Space
Jul 05, 2023The generative autoencoders, such as the variational autoencoders or the adversarial autoencoders, have achieved great success in lots of real-world applications, including image generation, and signal communication. However, little concern has been devoted to their robustness during practical deployment. Due to the probabilistic latent structure, variational autoencoders (VAEs) may confront problems such as a mismatch between the posterior distribution of the latent and real data manifold, or discontinuity in the posterior distribution of the latent. This leaves a back door for malicious attackers to collapse VAEs from the latent space, especially in scenarios where the encoder and decoder are used separately, such as communication and compressed sensing. In this work, we provide the first study on the adversarial robustness of generative autoencoders in the latent space. Specifically, we empirically demonstrate the latent vulnerability of popular generative autoencoders through attacks in the latent space. We also evaluate the difference between variational autoencoders and their deterministic variants and observe that the latter performs better in latent robustness. Meanwhile, we identify a potential trade-off between the adversarial robustness and the degree of the disentanglement of the latent codes. Additionally, we also verify the feasibility of improvement for the latent robustness of VAEs through adversarial training. In summary, we suggest concerning the adversarial latent robustness of the generative autoencoders, analyze several robustness-relative issues, and give some insights into a series of key challenges.