 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInternVLA-A1: Unifying Understanding, Generation and Action for Robotic Manipulation
Jan 05, 2026Prevalent Vision-Language-Action (VLA) models are typically built upon Multimodal Large Language Models (MLLMs) and demonstrate exceptional proficiency in semantic understanding, but they inherently lack the capability to deduce physical world dynamics. Consequently, recent approaches have shifted toward World Models, typically formulated via video prediction; however, these methods often suffer from a lack of semantic grounding and exhibit brittleness when handling prediction errors. To synergize semantic understanding with dynamic predictive capabilities, we present InternVLA-A1. This model employs a unified Mixture-of-Transformers architecture, coordinating three experts for scene understanding, visual foresight generation, and action execution. These components interact seamlessly through a unified masked self-attention mechanism. Building upon InternVL3 and Qwen3-VL, we instantiate InternVLA-A1 at 2B and 3B parameter scales. We pre-train these models on hybrid synthetic-real datasets spanning InternData-A1 and Agibot-World, covering over 533M frames. This hybrid training strategy effectively harnesses the diversity of synthetic simulation data while minimizing the sim-to-real gap. We evaluated InternVLA-A1 across 12 real-world robotic tasks and simulation benchmark. It significantly outperforms leading models like pi0 and GR00T N1.5, achieving a 14.5\% improvement in daily tasks and a 40\%-73.3\% boost in dynamic settings, such as conveyor belt sorting.
StructVPR++: Distill Structural and Semantic Knowledge with Weighting Samples for Visual Place Recognition
Mar 09, 2025Visual place recognition is a challenging task for autonomous driving and robotics, which is usually considered as an image retrieval problem. A commonly used two-stage strategy involves global retrieval followed by re-ranking using patch-level descriptors. Most deep learning-based methods in an end-to-end manner cannot extract global features with sufficient semantic information from RGB images. In contrast, re-ranking can utilize more explicit structural and semantic information in one-to-one matching process, but it is time-consuming. To bridge the gap between global retrieval and re-ranking and achieve a good trade-off between accuracy and efficiency, we propose StructVPR++, a framework that embeds structural and semantic knowledge into RGB global representations via segmentation-guided distillation. Our key innovation lies in decoupling label-specific features from global descriptors, enabling explicit semantic alignment between image pairs without requiring segmentation during deployment. Furthermore, we introduce a sample-wise weighted distillation strategy that prioritizes reliable training pairs while suppressing noisy ones. Experiments on four benchmarks demonstrate that StructVPR++ surpasses state-of-the-art global methods by 5-23% in Recall@1 and even outperforms many two-stage approaches, achieving real-time efficiency with a single RGB input.
ForestLPR: LiDAR Place Recognition in Forests Attentioning Multiple BEV Density Images
Mar 06, 2025Place recognition is essential to maintain global consistency in large-scale localization systems. While research in urban environments has progressed significantly using LiDARs or cameras, applications in natural forest-like environments remain largely under-explored. Furthermore, forests present particular challenges due to high self-similarity and substantial variations in vegetation growth over time. In this work, we propose a robust LiDAR-based place recognition method for natural forests, ForestLPR. We hypothesize that a set of cross-sectional images of the forest's geometry at different heights contains the information needed to recognize revisiting a place. The cross-sectional images are represented by \ac{bev} density images of horizontal slices of the point cloud at different heights. Our approach utilizes a visual transformer as the shared backbone to produce sets of local descriptors and introduces a multi-BEV interaction module to attend to information at different heights adaptively. It is followed by an aggregation layer that produces a rotation-invariant place descriptor. We evaluated the efficacy of our method extensively on real-world data from public benchmarks as well as robotic datasets and compared it against the state-of-the-art (SOTA) methods. The results indicate that ForestLPR has consistently good performance on all evaluations and achieves an average increase of 7.38\% and 9.11\% on Recall@1 over the closest competitor on intra-sequence loop closure detection and inter-sequence re-localization, respectively, validating our hypothesis
InteractionNet: Joint Planning and Prediction for Autonomous Driving with Transformers
Sep 07, 2023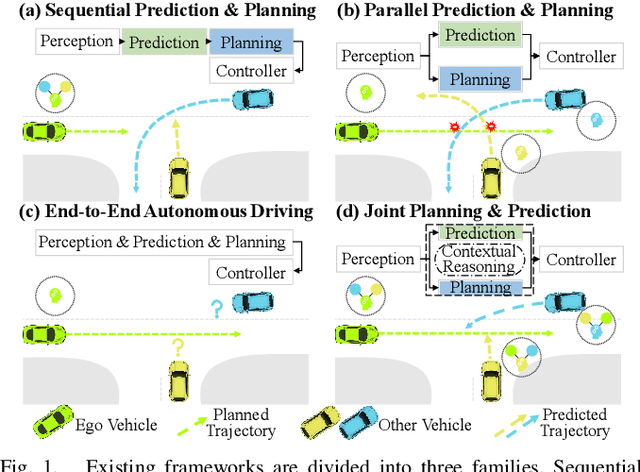
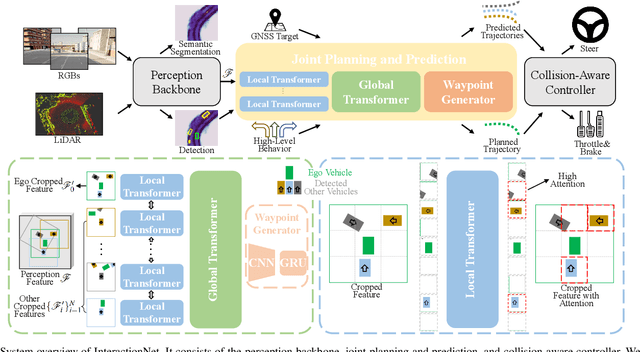
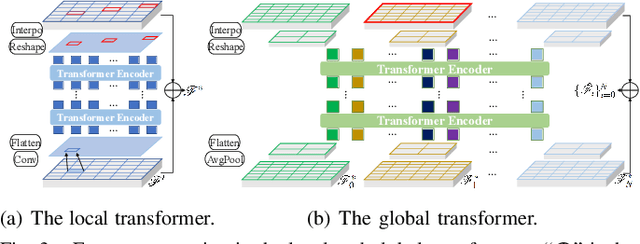

Planning and prediction are two important modules of autonomous driving and have experienced tremendous advancement recently. Nevertheless, most existing methods regard planning and prediction as independent and ignore the correlation between them, leading to the lack of consideration for interaction and dynamic changes of traffic scenarios. To address this challenge, we propose InteractionNet, which leverages transformer to share global contextual reasoning among all traffic participants to capture interaction and interconnect planning and prediction to achieve joint. Besides, InteractionNet deploys another transformer to help the model pay extra attention to the perceived region containing critical or unseen vehicles. InteractionNet outperforms other baselines in several benchmarks, especially in terms of safety, which benefits from the joint consideration of planning and forecasting. The code will be available at https://github.com/fujiawei0724/InteractionNet.
MLF-DET: Multi-Level Fusion for Cross-Modal 3D Object Detection
Jul 18, 2023In this paper, we propose a novel and effective Multi-Level Fusion network, named as MLF-DET, for high-performance cross-modal 3D object DETection, which integrates both the feature-level fusion and decision-level fusion to fully utilize the information in the image. For the feature-level fusion, we present the Multi-scale Voxel Image fusion (MVI) module, which densely aligns multi-scale voxel features with image features. For the decision-level fusion, we propose the lightweight Feature-cued Confidence Rectification (FCR) module which further exploits image semantics to rectify the confidence of detection candidates. Besides, we design an effective data augmentation strategy termed Occlusion-aware GT Sampling (OGS) to reserve more sampled objects in the training scenes, so as to reduce overfitting. Extensive experiments on the KITTI dataset demonstrate the effectiveness of our method. Notably, on the extremely competitive KITTI car 3D object detection benchmark, our method reaches 82.89% moderate AP and achieves state-of-the-art performance without bells and whistles.
StructVPR: Distill Structural Knowledge with Weighting Samples for Visual Place Recognition
Dec 09, 2022Visual place recognition (VPR) is usually considered as a specific image retrieval problem. Limited by existing training frameworks, most deep learning-based works cannot extract sufficiently stable global features from RGB images and rely on a time-consuming re-ranking step to exploit spatial structural information for better performance. In this paper, we propose StructVPR, a novel training architecture for VPR, to enhance structural knowledge in RGB global features and thus improve feature stability in a constantly changing environment. Specifically, StructVPR uses segmentation images as a more definitive source of structural knowledge input into a CNN network and applies knowledge distillation to avoid online segmentation and inference of seg-branch in testing. Considering that not all samples contain high-quality and helpful knowledge, and some even hurt the performance of distillation, we partition samples and weigh each sample's distillation loss to enhance the expected knowledge precisely. Finally, StructVPR achieves impressive performance on several benchmarks using only global retrieval and even outperforms many two-stage approaches by a large margin. After adding additional re-ranking, ours achieves state-of-the-art performance while maintaining a low computational cost.
TransVPR: Transformer-based place recognition with multi-level attention aggregation
Jan 06, 2022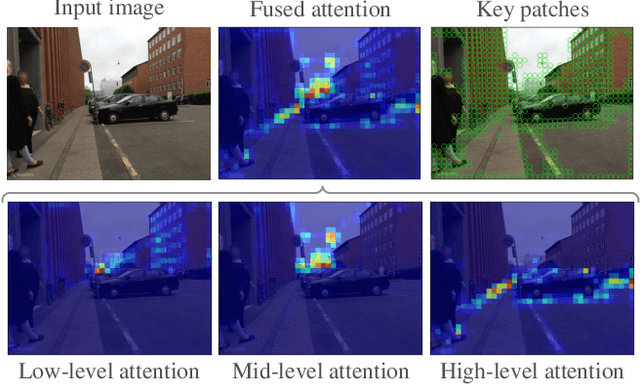

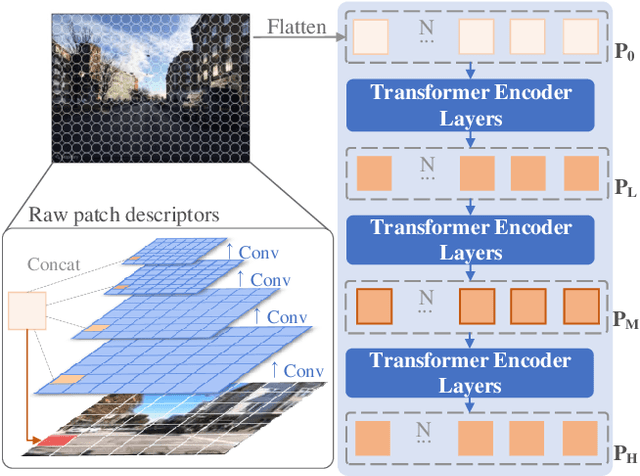
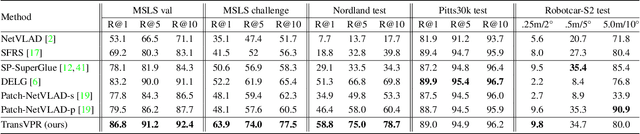
Visual place recognition is a challenging task for applications such as autonomous driving navigation and mobile robot localization. Distracting elements presenting in complex scenes often lead to deviations in the perception of visual place. To address this problem, it is crucial to integrate information from only task-relevant regions into image representations. In this paper, we introduce a novel holistic place recognition model, TransVPR, based on vision Transformers. It benefits from the desirable property of the self-attention operation in Transformers which can naturally aggregate task-relevant features. Attentions from multiple levels of the Transformer, which focus on different regions of interest, are further combined to generate a global image representation. In addition, the output tokens from Transformer layers filtered by the fused attention mask are considered as key-patch descriptors, which are used to perform spatial matching to re-rank the candidates retrieved by the global image features. The whole model allows end-to-end training with a single objective and image-level supervision. TransVPR achieves state-of-the-art performance on several real-world benchmarks while maintaining low computational time and storage requirements.