 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScenePilot-Bench: A Large-Scale Dataset and Benchmark for Evaluation of Vision-Language Models in Autonomous Driving
Jan 27, 2026In this paper, we introduce ScenePilot-Bench, a large-scale first-person driving benchmark designed to evaluate vision-language models (VLMs) in autonomous driving scenarios. ScenePilot-Bench is built upon ScenePilot-4K, a diverse dataset comprising 3,847 hours of driving videos, annotated with multi-granularity information including scene descriptions, risk assessments, key participant identification, ego trajectories, and camera parameters. The benchmark features a four-axis evaluation suite that assesses VLM capabilities in scene understanding, spatial perception, motion planning, and GPT-Score, with safety-aware metrics and cross-region generalization settings. We benchmark representative VLMs on ScenePilot-Bench, providing empirical analyses that clarify current performance boundaries and identify gaps for driving-oriented reasoning. ScenePilot-Bench offers a comprehensive framework for evaluating and advancing VLMs in safety-critical autonomous driving contexts.
A Reference-Based 3D Semantic-Aware Framework for Accurate Local Facial Attribute Editing
Jul 29, 2024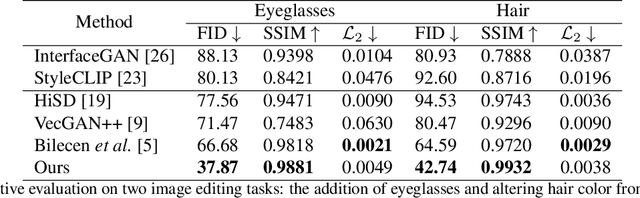
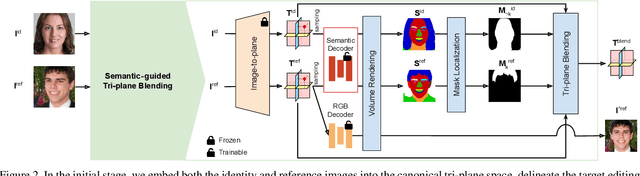

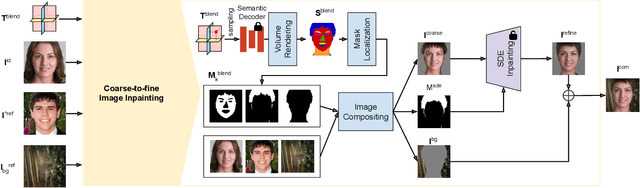
Facial attribute editing plays a crucial role in synthesizing realistic faces with specific characteristics while maintaining realistic appearances. Despite advancements, challenges persist in achieving precise, 3D-aware attribute modifications, which are crucial for consistent and accurate representations of faces from different angles. Current methods struggle with semantic entanglement and lack effective guidance for incorporating attributes while maintaining image integrity. To address these issues, we introduce a novel framework that merges the strengths of latent-based and reference-based editing methods. Our approach employs a 3D GAN inversion technique to embed attributes from the reference image into a tri-plane space, ensuring 3D consistency and realistic viewing from multiple perspectives. We utilize blending techniques and predicted semantic masks to locate precise edit regions, merging them with the contextual guidance from the reference image. A coarse-to-fine inpainting strategy is then applied to preserve the integrity of untargeted areas, significantly enhancing realism. Our evaluations demonstrate superior performance across diverse editing tasks, validating our framework's effectiveness in realistic and applicable facial attribute editing.
Detecting subtle macroscopic changes in a finite temperature classical scalar field with machine learning
Nov 21, 2023The ability to detect macroscopic changes is important for probing the behaviors of experimental many-body systems from the classical to the quantum realm. Although abrupt changes near phase boundaries can easily be detected, subtle macroscopic changes are much more difficult to detect as the changes can be obscured by noise. In this study, as a toy model for detecting subtle macroscopic changes in many-body systems, we try to differentiate scalar field samples at varying temperatures. We compare different methods for making such differentiations, from physics method, statistics method, to AI method. Our finding suggests that the AI method outperforms both the statistical method and the physics method in its sensitivity. Our result provides a proof-of-concept that AI can potentially detect macroscopic changes in many-body systems that elude physical measures.
Powering Finetuning in Few-shot Learning: Domain-Agnostic Feature Adaptation with Rectified Class Prototypes
Apr 07, 2022


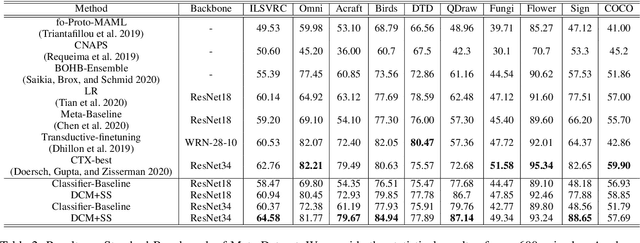
In recent works, utilizing a deep network trained on meta-training set serves as a strong baseline in few-shot learning. In this paper, we move forward to refine novel-class features by finetuning a trained deep network. Finetuning is designed to focus on reducing biases in novel-class feature distributions, which we define as two aspects: class-agnostic and class-specific biases. Class-agnostic bias is defined as the distribution shifting introduced by domain difference, which we propose Distribution Calibration Module(DCM) to reduce. DCM owes good property of eliminating domain difference and fast feature adaptation during optimization. Class-specific bias is defined as the biased estimation using a few samples in novel classes, which we propose Selected Sampling(SS) to reduce. Without inferring the actual class distribution, SS is designed by running sampling using proposal distributions around support-set samples. By powering finetuning with DCM and SS, we achieve state-of-the-art results on Meta-Dataset with consistent performance boosts over ten datasets from different domains. We believe our simple yet effective method demonstrates its possibility to be applied on practical few-shot applications.
Unsupervised Disentanglement of Linear-Encoded Facial Semantics
Mar 30, 2021
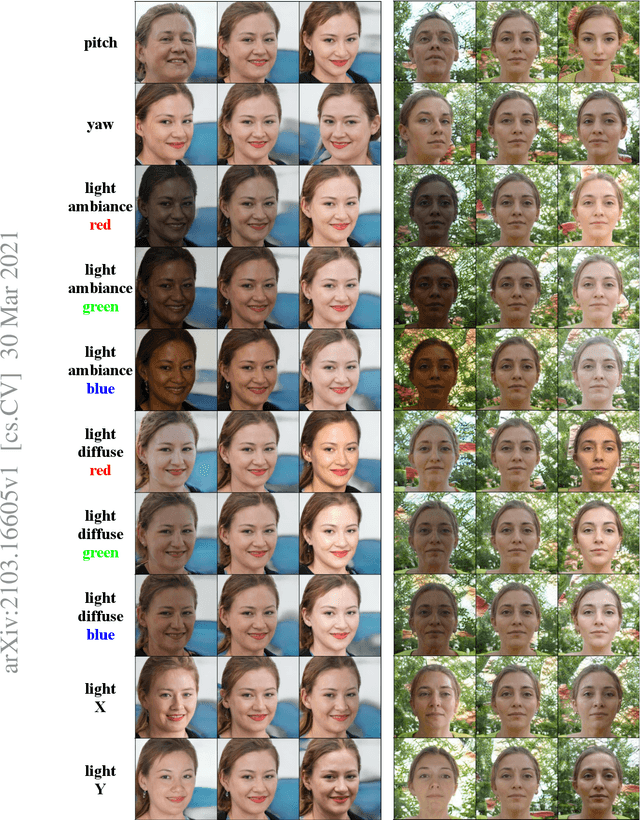


We propose a method to disentangle linear-encoded facial semantics from StyleGAN without external supervision. The method derives from linear regression and sparse representation learning concepts to make the disentangled latent representations easily interpreted as well. We start by coupling StyleGAN with a stabilized 3D deformable facial reconstruction method to decompose single-view GAN generations into multiple semantics. Latent representations are then extracted to capture interpretable facial semantics. In this work, we make it possible to get rid of labels for disentangling meaningful facial semantics. Also, we demonstrate that the guided extrapolation along the disentangled representations can help with data augmentation, which sheds light on handling unbalanced data. Finally, we provide an analysis of our learned localized facial representations and illustrate that the semantic information is encoded, which surprisingly complies with human intuition. The overall unsupervised design brings more flexibility to representation learning in the wild.
Adversarial-Based Knowledge Distillation for Multi-Model Ensemble and Noisy Data Refinement
Aug 22, 2019



Generic Image recognition is a fundamental and fairly important visual problem in computer vision. One of the major challenges of this task lies in the fact that single image usually has multiple objects inside while the labels are still one-hot, another one is noisy and sometimes missing labels when annotated by humans. In this paper, we focus on tackling these challenges accompanying with two different image recognition problems: multi-model ensemble and noisy data recognition with a unified framework. As is well-known, usually the best performing deep neural models are ensembles of multiple base-level networks, as it can mitigate the variation or noise containing in the dataset. Unfortunately, the space required to store these many networks, and the time required to execute them at runtime, prohibit their use in applications where test sets are large (e.g., ImageNet). In this paper, we present a method for compressing large, complex trained ensembles into a single network, where the knowledge from a variety of trained deep neural networks (DNNs) is distilled and transferred to a single DNN. In order to distill diverse knowledge from different trained (teacher) models, we propose to use adversarial-based learning strategy where we define a block-wise training loss to guide and optimize the predefined student network to recover the knowledge in teacher models, and to promote the discriminator network to distinguish teacher vs. student features simultaneously. Extensive experiments on CIFAR-10/100, SVHN, ImageNet and iMaterialist Challenge Dataset demonstrate the effectiveness of our MEAL method. On ImageNet, our ResNet-50 based MEAL achieves top-1/5 21.79%/5.99% val error, which outperforms the original model by 2.06%/1.14%. On iMaterialist Challenge Dataset, our MEAL obtains a remarkable improvement of top-3 1.15% (official evaluation metric) on a strong baseline model of ResNet-101.
Ring loss: Convex Feature Normalization for Face Recognition
Feb 28, 2018
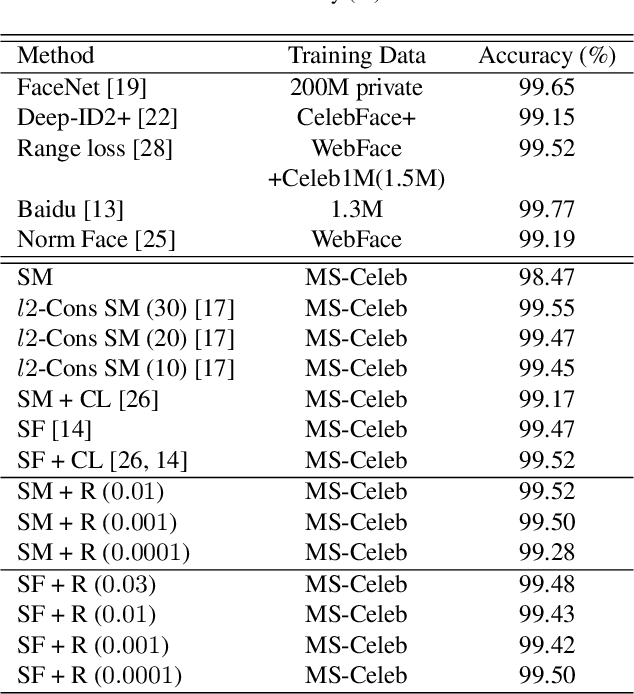
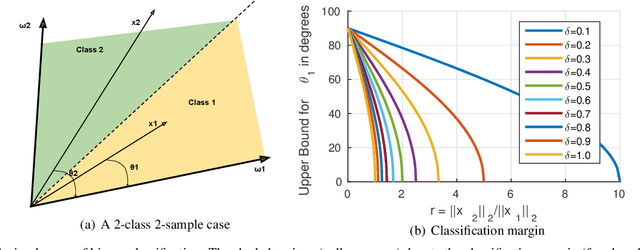
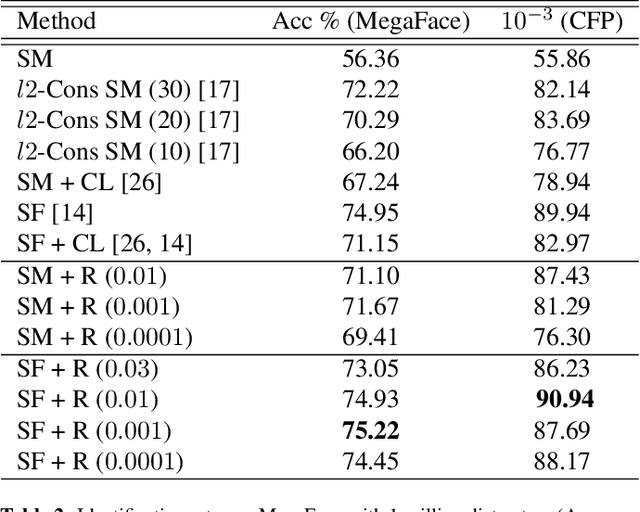
We motivate and present Ring loss, a simple and elegant feature normalization approach for deep networks designed to augment standard loss functions such as Softmax. We argue that deep feature normalization is an important aspect of supervised classification problems where we require the model to represent each class in a multi-class problem equally well. The direct approach to feature normalization through the hard normalization operation results in a non-convex formulation. Instead, Ring loss applies soft normalization, where it gradually learns to constrain the norm to the scaled unit circle while preserving convexity leading to more robust features. We apply Ring loss to large-scale face recognition problems and present results on LFW, the challenging protocols of IJB-A Janus, Janus CS3 (a superset of IJB-A Janus), Celebrity Frontal-Profile (CFP) and MegaFace with 1 million distractors. Ring loss outperforms strong baselines, matches state-of-the-art performance on IJB-A Janus and outperforms all other results on the challenging Janus CS3 thereby achieving state-of-the-art. We also outperform strong baselines in handling extremely low resolution face matching.
Towards a Deep Learning Framework for Unconstrained Face Detection
Jan 02, 2017
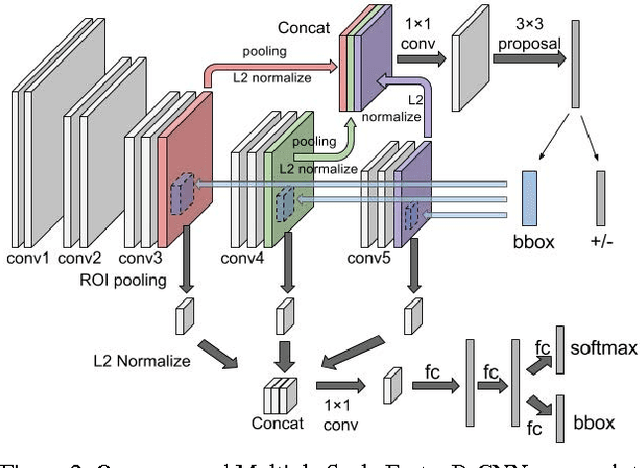
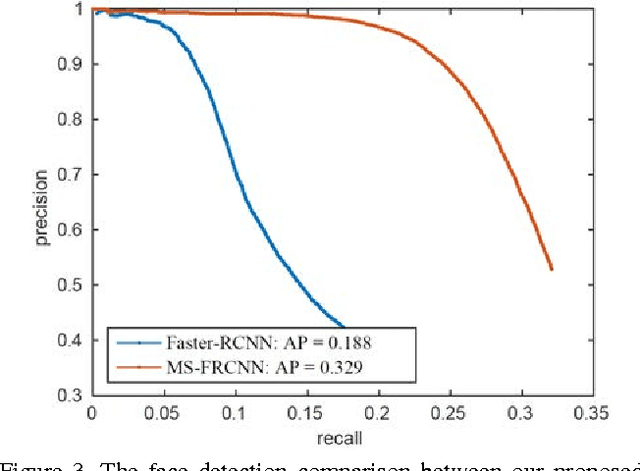
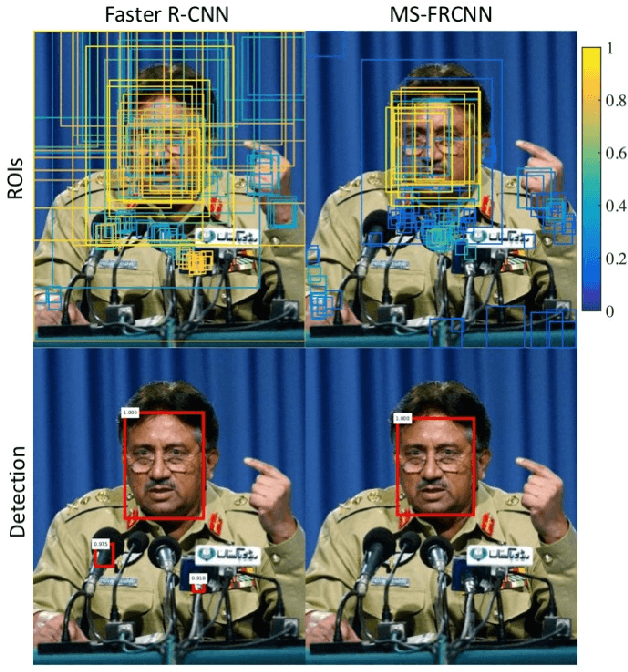
Robust face detection is one of the most important pre-processing steps to support facial expression analysis, facial landmarking, face recognition, pose estimation, building of 3D facial models, etc. Although this topic has been intensely studied for decades, it is still challenging due to numerous variants of face images in real-world scenarios. In this paper, we present a novel approach named Multiple Scale Faster Region-based Convolutional Neural Network (MS-FRCNN) to robustly detect human facial regions from images collected under various challenging conditions, e.g. large occlusions, extremely low resolutions, facial expressions, strong illumination variations, etc. The proposed approach is benchmarked on two challenging face detection databases, i.e. the Wider Face database and the Face Detection Dataset and Benchmark (FDDB), and compared against recent other face detection methods, e.g. Two-stage CNN, Multi-scale Cascade CNN, Faceness, Aggregate Chanel Features, HeadHunter, Multi-view Face Detection, Cascade CNN, etc. The experimental results show that our proposed approach consistently achieves highly competitive results with the state-of-the-art performance against other recent face detection methods.
CMS-RCNN: Contextual Multi-Scale Region-based CNN for Unconstrained Face Detection
Jun 17, 2016
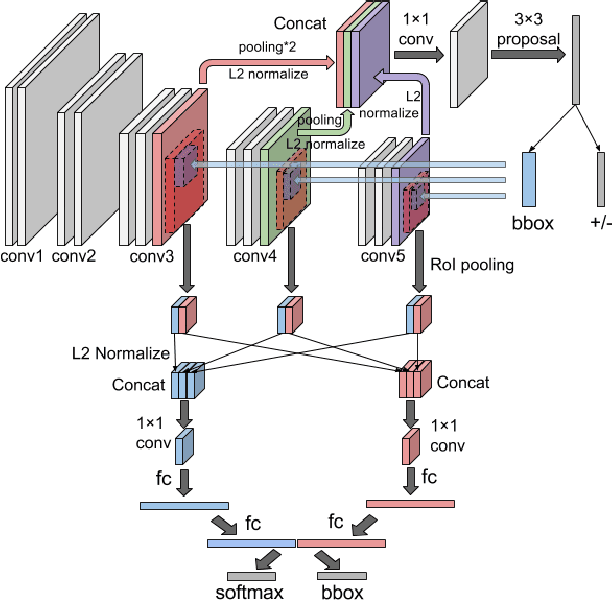


Robust face detection in the wild is one of the ultimate components to support various facial related problems, i.e. unconstrained face recognition, facial periocular recognition, facial landmarking and pose estimation, facial expression recognition, 3D facial model construction, etc. Although the face detection problem has been intensely studied for decades with various commercial applications, it still meets problems in some real-world scenarios due to numerous challenges, e.g. heavy facial occlusions, extremely low resolutions, strong illumination, exceptionally pose variations, image or video compression artifacts, etc. In this paper, we present a face detection approach named Contextual Multi-Scale Region-based Convolution Neural Network (CMS-RCNN) to robustly solve the problems mentioned above. Similar to the region-based CNNs, our proposed network consists of the region proposal component and the region-of-interest (RoI) detection component. However, far apart of that network, there are two main contributions in our proposed network that play a significant role to achieve the state-of-the-art performance in face detection. Firstly, the multi-scale information is grouped both in region proposal and RoI detection to deal with tiny face regions. Secondly, our proposed network allows explicit body contextual reasoning in the network inspired from the intuition of human vision system. The proposed approach is benchmarked on two recent challenging face detection databases, i.e. the WIDER FACE Dataset which contains high degree of variability, as well as the Face Detection Dataset and Benchmark (FDDB). The experimental results show that our proposed approach trained on WIDER FACE Dataset outperforms strong baselines on WIDER FACE Dataset by a large margin, and consistently achieves competitive results on FDDB against the recent state-of-the-art face detection methods.