 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaster Than Real-time Facial Alignment: A 3D Spatial Transformer Network Approach in Unconstrained Poses
Sep 08, 2017


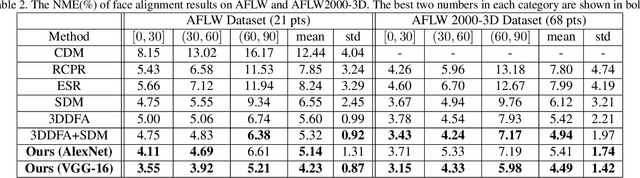
Facial alignment involves finding a set of landmark points on an image with a known semantic meaning. However, this semantic meaning of landmark points is often lost in 2D approaches where landmarks are either moved to visible boundaries or ignored as the pose of the face changes. In order to extract consistent alignment points across large poses, the 3D structure of the face must be considered in the alignment step. However, extracting a 3D structure from a single 2D image usually requires alignment in the first place. We present our novel approach to simultaneously extract the 3D shape of the face and the semantically consistent 2D alignment through a 3D Spatial Transformer Network (3DSTN) to model both the camera projection matrix and the warping parameters of a 3D model. By utilizing a generic 3D model and a Thin Plate Spline (TPS) warping function, we are able to generate subject specific 3D shapes without the need for a large 3D shape basis. In addition, our proposed network can be trained in an end-to-end framework on entirely synthetic data from the 300W-LP dataset. Unlike other 3D methods, our approach only requires one pass through the network resulting in a faster than real-time alignment. Evaluations of our model on the Annotated Facial Landmarks in the Wild (AFLW) and AFLW2000-3D datasets show our method achieves state-of-the-art performance over other 3D approaches to alignment.
Towards a Deep Learning Framework for Unconstrained Face Detection
Jan 02, 2017
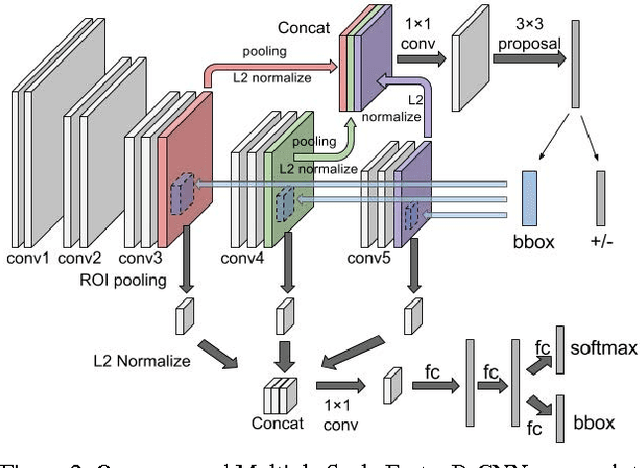
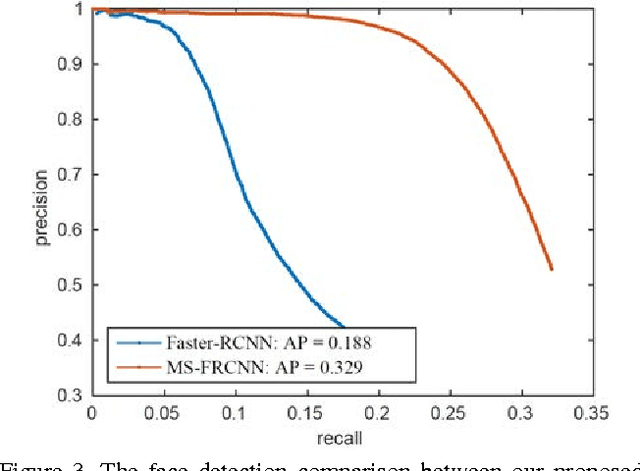
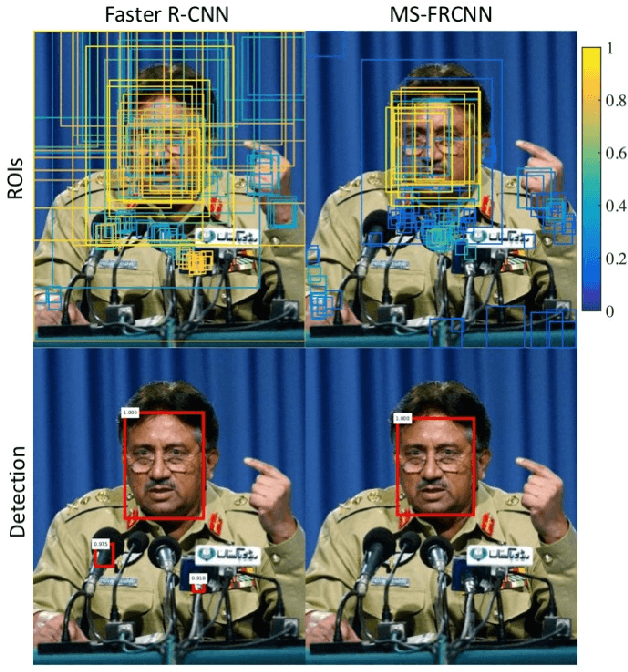
Robust face detection is one of the most important pre-processing steps to support facial expression analysis, facial landmarking, face recognition, pose estimation, building of 3D facial models, etc. Although this topic has been intensely studied for decades, it is still challenging due to numerous variants of face images in real-world scenarios. In this paper, we present a novel approach named Multiple Scale Faster Region-based Convolutional Neural Network (MS-FRCNN) to robustly detect human facial regions from images collected under various challenging conditions, e.g. large occlusions, extremely low resolutions, facial expressions, strong illumination variations, etc. The proposed approach is benchmarked on two challenging face detection databases, i.e. the Wider Face database and the Face Detection Dataset and Benchmark (FDDB), and compared against recent other face detection methods, e.g. Two-stage CNN, Multi-scale Cascade CNN, Faceness, Aggregate Chanel Features, HeadHunter, Multi-view Face Detection, Cascade CNN, etc. The experimental results show that our proposed approach consistently achieves highly competitive results with the state-of-the-art performance against other recent face detection methods.