 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting the open-world objects with the help of the Brain
Paper and Code
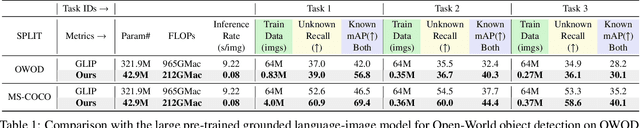
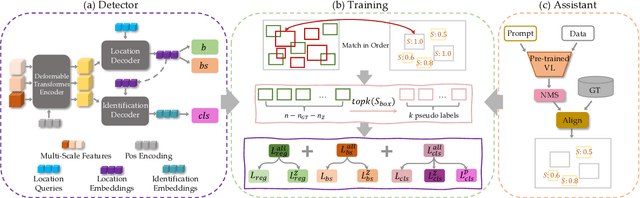
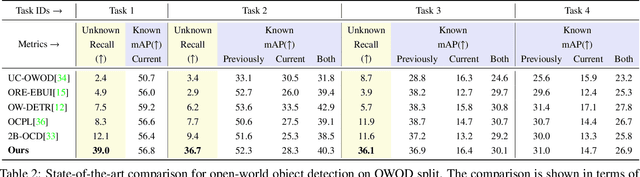
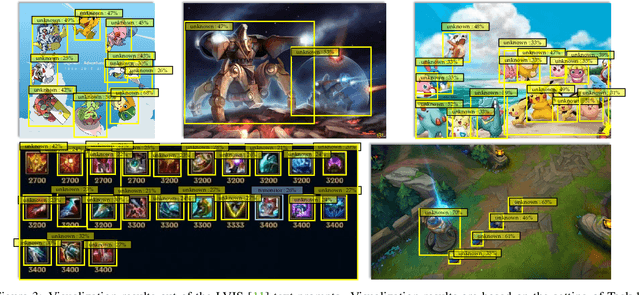
Open World Object Detection (OWOD) is a novel computer vision task with a considerable challenge, bridging the gap between classic object detection (OD) benchmarks and real-world object detection. In addition to detecting and classifying seen/known objects, OWOD algorithms are expected to detect unseen/unknown objects and incrementally learn them. The natural instinct of humans to identify unknown objects in their environments mainly depends on their brains' knowledge base. It is difficult for a model to do this only by learning from the annotation of several tiny datasets. The large pre-trained grounded language-image models - VL (\ie GLIP) have rich knowledge about the open world but are limited to the text prompt. We propose leveraging the VL as the ``Brain'' of the open-world detector by simply generating unknown labels. Leveraging it is non-trivial because the unknown labels impair the model's learning of known objects. In this paper, we alleviate these problems by proposing the down-weight loss function and decoupled detection structure. Moreover, our detector leverages the ``Brain'' to learn novel objects beyond VL through our pseudo-labeling scheme.