 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiPLY: A Multisensory Object-Centric Embodied Large Language Model in 3D World
Jan 16, 2024
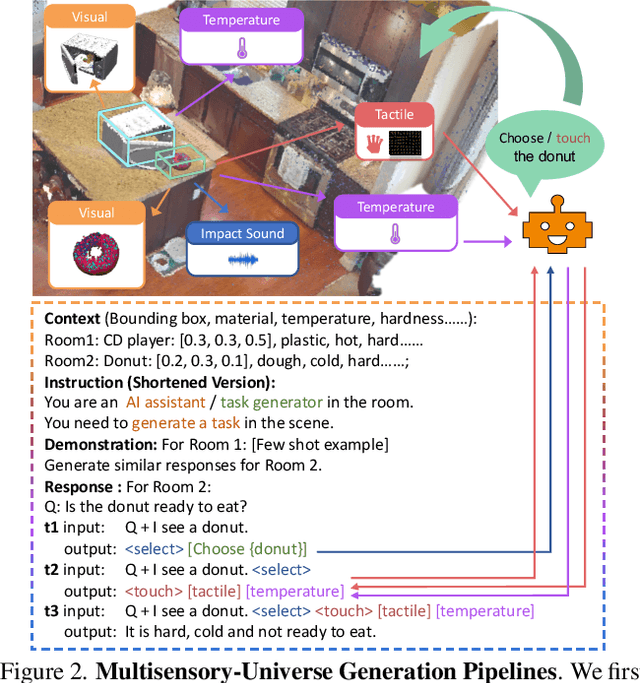


Human beings possess the capability to multiply a melange of multisensory cues while actively exploring and interacting with the 3D world. Current multi-modal large language models, however, passively absorb sensory data as inputs, lacking the capacity to actively interact with the objects in the 3D environment and dynamically collect their multisensory information. To usher in the study of this area, we propose MultiPLY, a multisensory embodied large language model that could incorporate multisensory interactive data, including visual, audio, tactile, and thermal information into large language models, thereby establishing the correlation among words, actions, and percepts. To this end, we first collect Multisensory Universe, a large-scale multisensory interaction dataset comprising 500k data by deploying an LLM-powered embodied agent to engage with the 3D environment. To perform instruction tuning with pre-trained LLM on such generated data, we first encode the 3D scene as abstracted object-centric representations and then introduce action tokens denoting that the embodied agent takes certain actions within the environment, as well as state tokens that represent the multisensory state observations of the agent at each time step. In the inference time, MultiPLY could generate action tokens, instructing the agent to take the action in the environment and obtain the next multisensory state observation. The observation is then appended back to the LLM via state tokens to generate subsequent text or action tokens. We demonstrate that MultiPLY outperforms baselines by a large margin through a diverse set of embodied tasks involving object retrieval, tool use, multisensory captioning, and task decomposition.
Disentangling Orthogonal Planes for Indoor Panoramic Room Layout Estimation with Cross-Scale Distortion Awareness
Mar 04, 2023Based on the Manhattan World assumption, most existing indoor layout estimation schemes focus on recovering layouts from vertically compressed 1D sequences. However, the compression procedure confuses the semantics of different planes, yielding inferior performance with ambiguous interpretability. To address this issue, we propose to disentangle this 1D representation by pre-segmenting orthogonal (vertical and horizontal) planes from a complex scene, explicitly capturing the geometric cues for indoor layout estimation. Considering the symmetry between the floor boundary and ceiling boundary, we also design a soft-flipping fusion strategy to assist the pre-segmentation. Besides, we present a feature assembling mechanism to effectively integrate shallow and deep features with distortion distribution awareness. To compensate for the potential errors in pre-segmentation, we further leverage triple attention to reconstruct the disentangled sequences for better performance. Experiments on four popular benchmarks demonstrate our superiority over existing SoTA solutions, especially on the 3DIoU metric. The code is available at \url{https://github.com/zhijieshen-bjtu/DOPNet}.
RecRecNet: Rectangling Rectified Wide-Angle Images by Thin-Plate Spline Model and DoF-based Curriculum Learning
Jan 04, 2023The wide-angle lens shows appealing applications in VR technologies, but it introduces severe radial distortion into its captured image. To recover the realistic scene, previous works devote to rectifying the content of the wide-angle image. However, such a rectification solution inevitably distorts the image boundary, which potentially changes related geometric distributions and misleads the current vision perception models. In this work, we explore constructing a win-win representation on both content and boundary by contributing a new learning model, i.e., Rectangling Rectification Network (RecRecNet). In particular, we propose a thin-plate spline (TPS) module to formulate the non-linear and non-rigid transformation for rectangling images. By learning the control points on the rectified image, our model can flexibly warp the source structure to the target domain and achieves an end-to-end unsupervised deformation. To relieve the complexity of structure approximation, we then inspire our RecRecNet to learn the gradual deformation rules with a DoF (Degree of Freedom)-based curriculum learning. By increasing the DoF in each curriculum stage, namely, from similarity transformation (4-DoF) to homography transformation (8-DoF), the network is capable of investigating more detailed deformations, offering fast convergence on the final rectangling task. Experiments show the superiority of our solution over the compared methods on both quantitative and qualitative evaluations. The code and dataset will be made available.
Complementary Bi-directional Feature Compression for Indoor 360° Semantic Segmentation with Self-distillation
Jul 06, 2022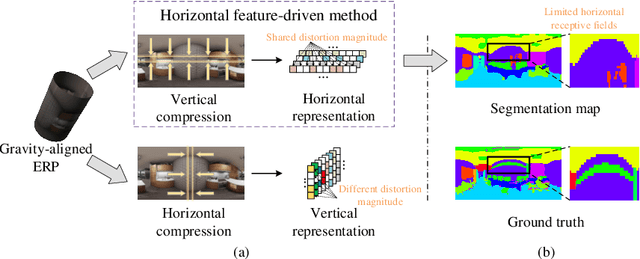
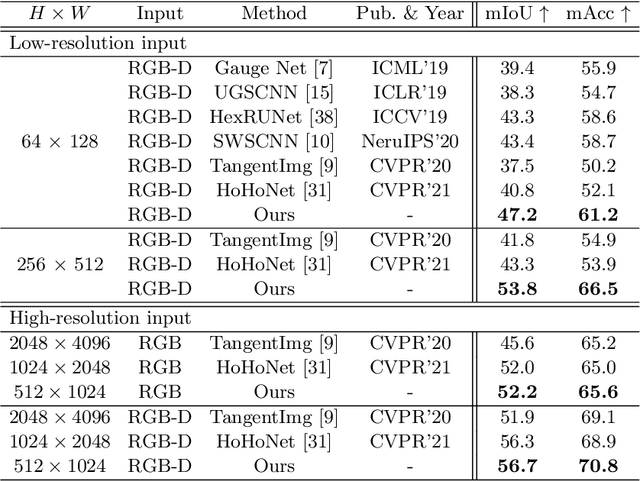

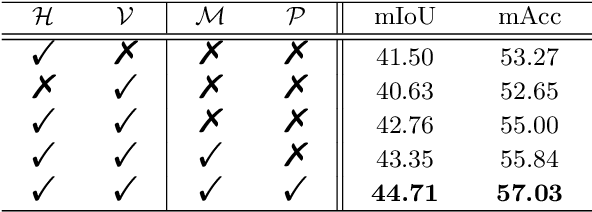
Recently, horizontal representation-based panoramic semantic segmentation approaches outperform projection-based solutions, because the distortions can be effectively removed by compressing the spherical data in the vertical direction. However, these methods ignore the distortion distribution prior and are limited to unbalanced receptive fields, e.g., the receptive fields are sufficient in the vertical direction and insufficient in the horizontal direction. Differently, a vertical representation compressed in another direction can offer implicit distortion prior and enlarge horizontal receptive fields. In this paper, we combine the two different representations and propose a novel 360{\deg} semantic segmentation solution from a complementary perspective. Our network comprises three modules: a feature extraction module, a bi-directional compression module, and an ensemble decoding module. First, we extract multi-scale features from a panorama. Then, a bi-directional compression module is designed to compress features into two complementary low-dimensional representations, which provide content perception and distortion prior. Furthermore, to facilitate the fusion of bi-directional features, we design a unique self distillation strategy in the ensemble decoding module to enhance the interaction of different features and further improve the performance. Experimental results show that our approach outperforms the state-of-the-art solutions with at least 10\% improvement on quantitative evaluations while displaying the best performance on visual appearance.
PanoFormer: Panorama Transformer for Indoor 360° Depth Estimation
Mar 17, 2022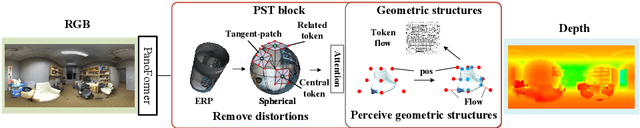
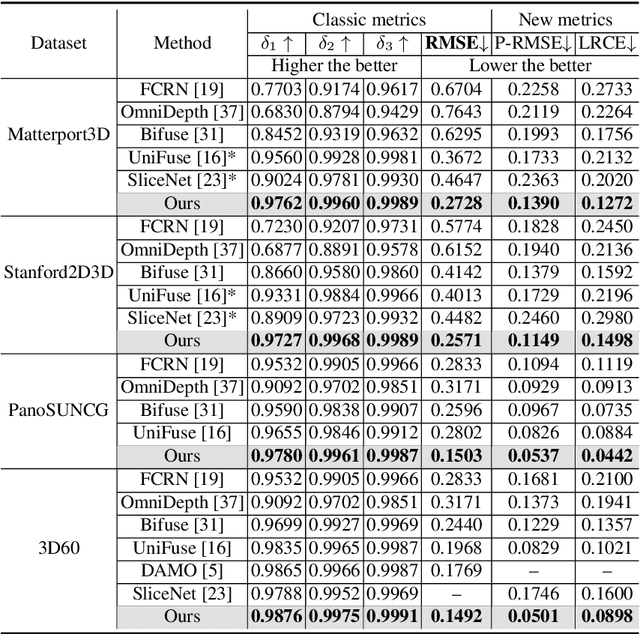
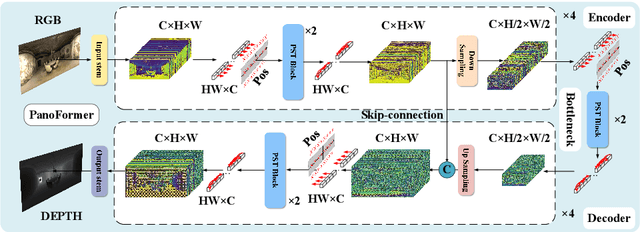

Existing panoramic depth estimation methods based on convolutional neural networks (CNNs) focus on removing panoramic distortions, failing to perceive panoramic structures efficiently due to the fixed receptive field in CNNs. This paper proposes the panorama transformer (named PanoFormer) to estimate the depth in panorama images, with tangent patches from spherical domain, learnable token flows, and panorama specific metrics. In particular, we divide patches on the spherical tangent domain into tokens to reduce the negative effect of panoramic distortions. Since the geometric structures are essential for depth estimation, a self-attention module is redesigned with an additional learnable token flow. In addition, considering the characteristic of the spherical domain, we present two panorama-specific metrics to comprehensively evaluate the panoramic depth estimation models' performance. Extensive experiments demonstrate that our approach significantly outperforms the state-of-the-art (SOTA) methods. Furthermore, the proposed method can be effectively extended to solve semantic panorama segmentation, a similar pixel2pixel task. Code will be available.