 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePanoFormer: Panorama Transformer for Indoor 360° Depth Estimation
Paper and Code
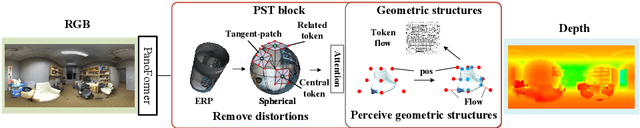
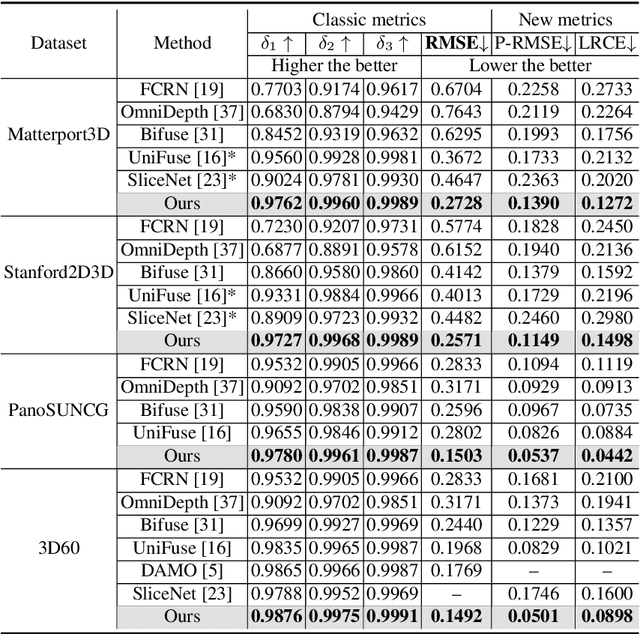
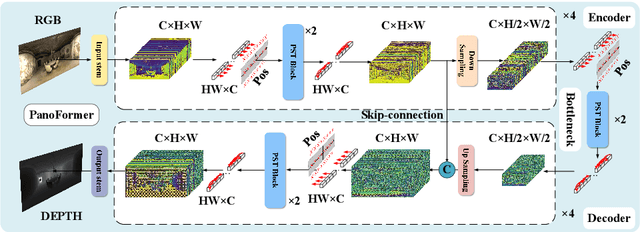

Existing panoramic depth estimation methods based on convolutional neural networks (CNNs) focus on removing panoramic distortions, failing to perceive panoramic structures efficiently due to the fixed receptive field in CNNs. This paper proposes the panorama transformer (named PanoFormer) to estimate the depth in panorama images, with tangent patches from spherical domain, learnable token flows, and panorama specific metrics. In particular, we divide patches on the spherical tangent domain into tokens to reduce the negative effect of panoramic distortions. Since the geometric structures are essential for depth estimation, a self-attention module is redesigned with an additional learnable token flow. In addition, considering the characteristic of the spherical domain, we present two panorama-specific metrics to comprehensively evaluate the panoramic depth estimation models' performance. Extensive experiments demonstrate that our approach significantly outperforms the state-of-the-art (SOTA) methods. Furthermore, the proposed method can be effectively extended to solve semantic panorama segmentation, a similar pixel2pixel task. Code will be available.