 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForensics-Bench: A Comprehensive Forgery Detection Benchmark Suite for Large Vision Language Models
Mar 19, 2025



Recently, the rapid development of AIGC has significantly boosted the diversities of fake media spread in the Internet, posing unprecedented threats to social security, politics, law, and etc. To detect the ever-increasingly diverse malicious fake media in the new era of AIGC, recent studies have proposed to exploit Large Vision Language Models (LVLMs) to design robust forgery detectors due to their impressive performance on a wide range of multimodal tasks. However, it still lacks a comprehensive benchmark designed to comprehensively assess LVLMs' discerning capabilities on forgery media. To fill this gap, we present Forensics-Bench, a new forgery detection evaluation benchmark suite to assess LVLMs across massive forgery detection tasks, requiring comprehensive recognition, location and reasoning capabilities on diverse forgeries. Forensics-Bench comprises 63,292 meticulously curated multi-choice visual questions, covering 112 unique forgery detection types from 5 perspectives: forgery semantics, forgery modalities, forgery tasks, forgery types and forgery models. We conduct thorough evaluations on 22 open-sourced LVLMs and 3 proprietary models GPT-4o, Gemini 1.5 Pro, and Claude 3.5 Sonnet, highlighting the significant challenges of comprehensive forgery detection posed by Forensics-Bench. We anticipate that Forensics-Bench will motivate the community to advance the frontier of LVLMs, striving for all-around forgery detectors in the era of AIGC. The deliverables will be updated at https://Forensics-Bench.github.io/.
MegActor-$Σ$: Unlocking Flexible Mixed-Modal Control in Portrait Animation with Diffusion Transformer
Aug 27, 2024


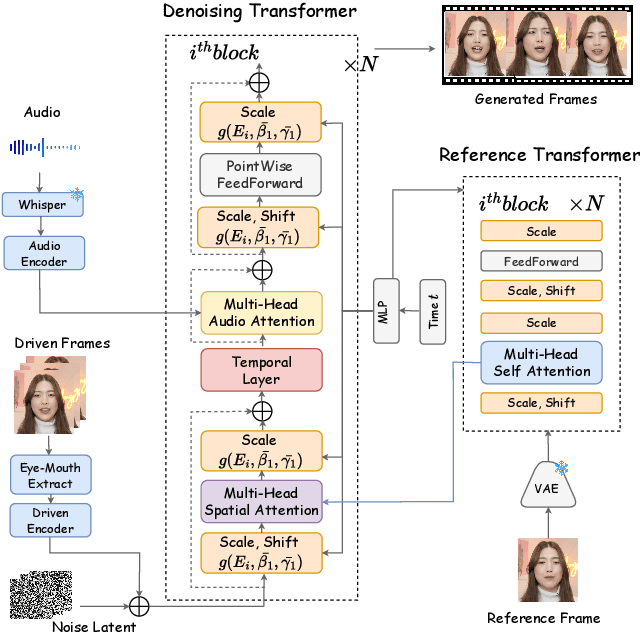
Diffusion models have demonstrated superior performance in the field of portrait animation. However, current approaches relied on either visual or audio modality to control character movements, failing to exploit the potential of mixed-modal control. This challenge arises from the difficulty in balancing the weak control strength of audio modality and the strong control strength of visual modality. To address this issue, we introduce MegActor-$\Sigma$: a mixed-modal conditional diffusion transformer (DiT), which can flexibly inject audio and visual modality control signals into portrait animation. Specifically, we make substantial advancements over its predecessor, MegActor, by leveraging the promising model structure of DiT and integrating audio and visual conditions through advanced modules within the DiT framework. To further achieve flexible combinations of mixed-modal control signals, we propose a ``Modality Decoupling Control" training strategy to balance the control strength between visual and audio modalities, along with the ``Amplitude Adjustment" inference strategy to freely regulate the motion amplitude of each modality. Finally, to facilitate extensive studies in this field, we design several dataset evaluation metrics to filter out public datasets and solely use this filtered dataset to train MegActor-$\Sigma$. Extensive experiments demonstrate the superiority of our approach in generating vivid portrait animations, outperforming previous methods trained on private dataset.
MegActor: Harness the Power of Raw Video for Vivid Portrait Animation
May 31, 2024
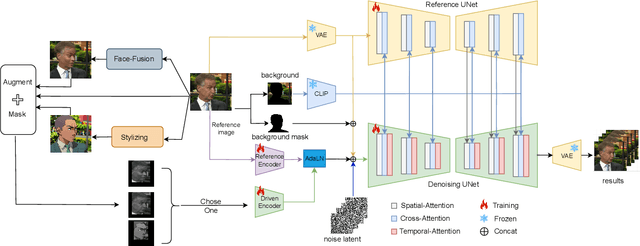


Despite raw driving videos contain richer information on facial expressions than intermediate representations such as landmarks in the field of portrait animation, they are seldom the subject of research. This is due to two challenges inherent in portrait animation driven with raw videos: 1) significant identity leakage; 2) Irrelevant background and facial details such as wrinkles degrade performance. To harnesses the power of the raw videos for vivid portrait animation, we proposed a pioneering conditional diffusion model named as MegActor. First, we introduced a synthetic data generation framework for creating videos with consistent motion and expressions but inconsistent IDs to mitigate the issue of ID leakage. Second, we segmented the foreground and background of the reference image and employed CLIP to encode the background details. This encoded information is then integrated into the network via a text embedding module, thereby ensuring the stability of the background. Finally, we further style transfer the appearance of the reference image to the driving video to eliminate the influence of facial details in the driving videos. Our final model was trained solely on public datasets, achieving results comparable to commercial models. We hope this will help the open-source community.The code is available at https://github.com/megvii-research/MegFaceAnimate.
Towards RGB-NIR Cross-modality Image Registration and Beyond
May 30, 2024



This paper focuses on the area of RGB(visible)-NIR(near-infrared) cross-modality image registration, which is crucial for many downstream vision tasks to fully leverage the complementary information present in visible and infrared images. In this field, researchers face two primary challenges - the absence of a correctly-annotated benchmark with viewpoint variations for evaluating RGB-NIR cross-modality registration methods and the problem of inconsistent local features caused by the appearance discrepancy between RGB-NIR cross-modality images. To address these challenges, we first present the RGB-NIR Image Registration (RGB-NIR-IRegis) benchmark, which, for the first time, enables fair and comprehensive evaluations for the task of RGB-NIR cross-modality image registration. Evaluations of previous methods highlight the significant challenges posed by our RGB-NIR-IRegis benchmark, especially on RGB-NIR image pairs with viewpoint variations. To analyze the causes of the unsatisfying performance, we then design several metrics to reveal the toxic impact of inconsistent local features between visible and infrared images on the model performance. This further motivates us to develop a baseline method named Semantic Guidance Transformer (SGFormer), which utilizes high-level semantic guidance to mitigate the negative impact of local inconsistent features. Despite the simplicity of our motivation, extensive experimental results show the effectiveness of our method.
Sparse Beats Dense: Rethinking Supervision in Radar-Camera Depth Completion
Dec 08, 2023
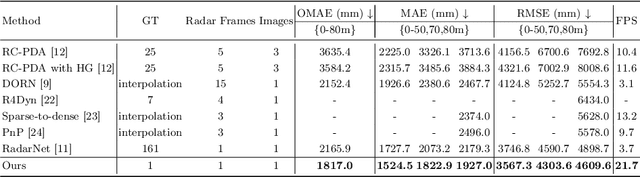


It is widely believed that the dense supervision is better than the sparse supervision in the field of depth completion, but the underlying reasons for this are rarely discussed. In this paper, we find that the challenge of using sparse supervision for training Radar-Camera depth prediction models is the Projection Transformation Collapse (PTC). The PTC implies that sparse supervision leads the model to learn unexpected collapsed projection transformations between Image/Radar/LiDAR spaces. Building on this insight, we propose a novel ``Disruption-Compensation" framework to handle the PTC, thereby relighting the use of sparse supervision in depth completion tasks. The disruption part deliberately discards position correspondences among Image/Radar/LiDAR, while the compensation part leverages 3D spatial and 2D semantic information to compensate for the discarded beneficial position correspondence. Extensive experimental results demonstrate that our framework (sparse supervision) outperforms the state-of-the-art (dense supervision) with 11.6$\%$ improvement in mean absolute error and $1.6 \times$ speedup. The code is available at ...
Discriminative-Region Attention and Orthogonal-View Generation Model for Vehicle Re-Identification
Apr 28, 2022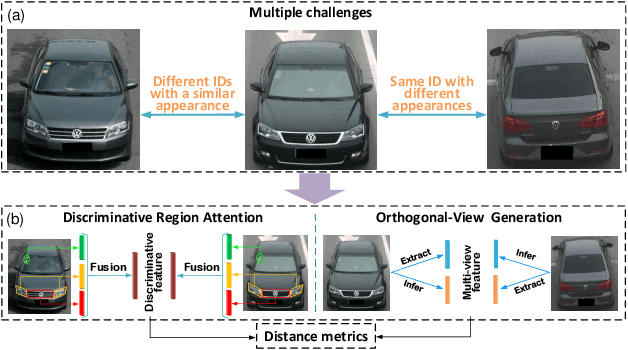

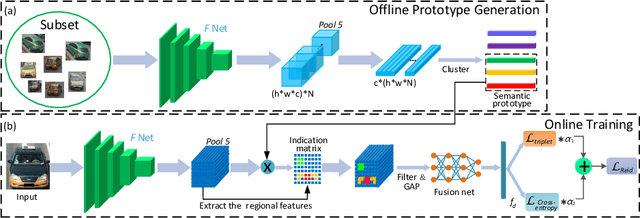

Vehicle re-identification (Re-ID) is urgently demanded to alleviate thepressure caused by the increasingly onerous task of urban traffic management. Multiple challenges hamper the applications of vision-based vehicle Re-ID methods: (1) The appearances of different vehicles of the same brand/model are often similar; However, (2) the appearances of the same vehicle differ significantly from different viewpoints. Previous methods mainly use manually annotated multi-attribute datasets to assist the network in getting detailed cues and in inferencing multi-view to improve the vehicle Re-ID performance. However, finely labeled vehicle datasets are usually unattainable in real application scenarios. Hence, we propose a Discriminative-Region Attention and Orthogonal-View Generation (DRA-OVG) model, which only requires identity (ID) labels to conquer the multiple challenges of vehicle Re-ID.The proposed DRA model can automatically extract the discriminative region features, which can distinguish similar vehicles. And the OVG model can generate multi-view features based on the input view features to reduce the impact of viewpoint mismatches. Finally, the distance between vehicle appearances is presented by the discriminative region features and multi-view features together. Therefore, the significance of pairwise distance measure between vehicles is enhanced in acomplete feature space. Extensive experiments substantiate the effectiveness of each proposed ingredient, and experimental results indicate that our approach achieves remarkable improvements over the state- of-the-art vehicle Re-ID methods on VehicleID and VeRi-776 datasets.