 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCSN: Component-Supervised Network for Few-Shot Classification
Mar 15, 2022
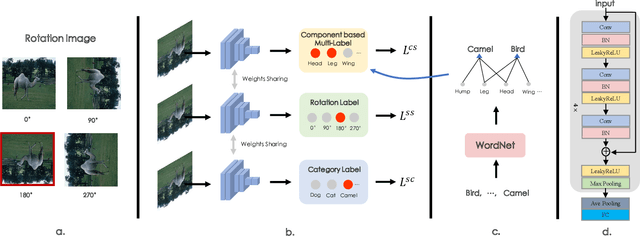

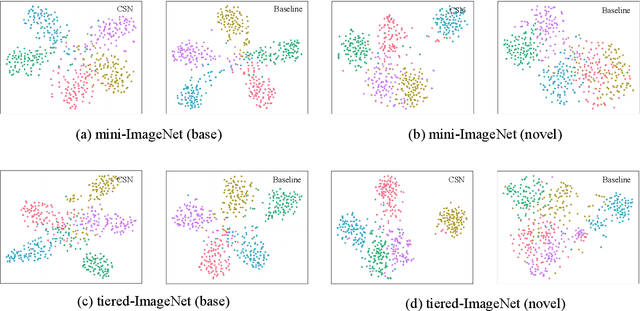
The few-shot classification (FSC) task has been a hot research topic in recent years. It aims to address the classification problem with insufficient labeled data on a cross-category basis. Typically, researchers pre-train a feature extractor with base data, then use it to extract the features of novel data and recognize them. Notably, the novel set only has a few annotated samples and has entirely different categories from the base set, which leads to that the pre-trained feature extractor can not adapt to the novel data flawlessly. We dub this problem as Feature-Extractor-Maladaptive (FEM) problem. Starting from the root cause of this problem, this paper presents a new scheme, Component-Supervised Network (CSN), to improve the performance of FSC. We believe that although the categories of base and novel sets are different, the composition of the sample's components is similar. For example, both cat and dog contain leg and head components. Actually, such entity components are intra-class stable. They have fine cross-category versatility and new category generalization. Therefore, we refer to WordNet, a dictionary commonly used in natural language processing, to collect component information of samples and construct a component-based auxiliary task to improve the adaptability of the feature extractor. We conduct experiments on two benchmark datasets (mini-ImageNet and tiered-ImageNet), the improvements of $0.9\%$-$5.8\%$ compared with state-of-the-arts have evaluated the efficiency of our CSN.
SSDL: Self-Supervised Dictionary Learning
Dec 03, 2021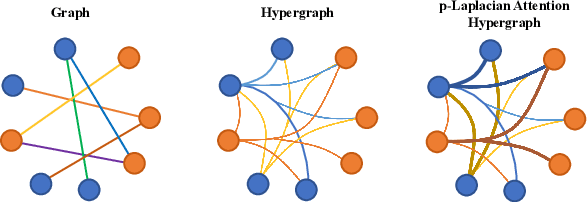
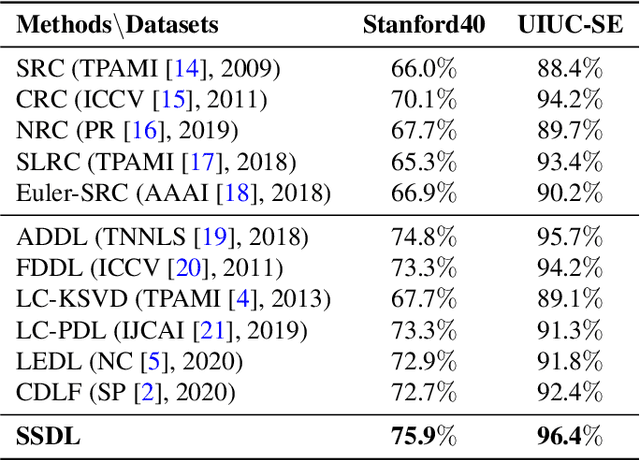
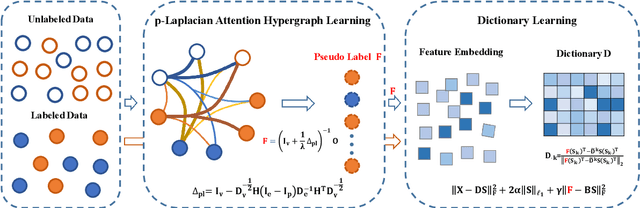
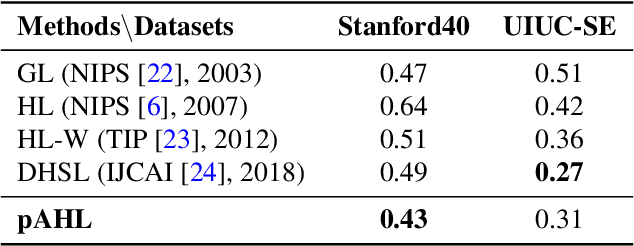
The label-embedded dictionary learning (DL) algorithms generate influential dictionaries by introducing discriminative information. However, there exists a limitation: All the label-embedded DL methods rely on the labels due that this way merely achieves ideal performances in supervised learning. While in semi-supervised and unsupervised learning, it is no longer sufficient to be effective. Inspired by the concept of self-supervised learning (e.g., setting the pretext task to generate a universal model for the downstream task), we propose a Self-Supervised Dictionary Learning (SSDL) framework to address this challenge. Specifically, we first design a $p$-Laplacian Attention Hypergraph Learning (pAHL) block as the pretext task to generate pseudo soft labels for DL. Then, we adopt the pseudo labels to train a dictionary from a primary label-embedded DL method. We evaluate our SSDL on two human activity recognition datasets. The comparison results with other state-of-the-art methods have demonstrated the efficiency of SSDL.
Dictionary learning based image enhancement for rarity detection
Sep 13, 2016
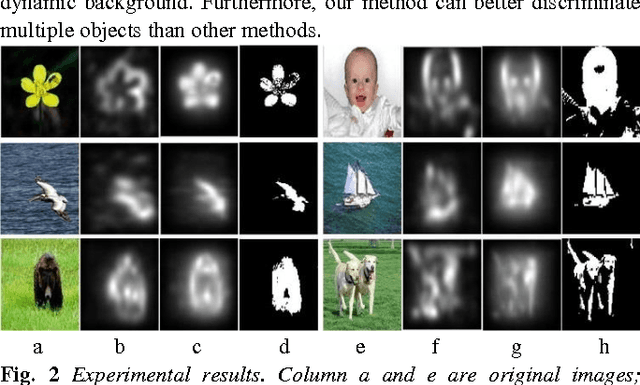
Image enhancement is an important image processing technique that processes images suitably for a specific application e.g. image editing. The conventional solutions of image enhancement are grouped into two categories which are spatial domain processing method and transform domain processing method such as contrast manipulation, histogram equalization, homomorphic filtering. This paper proposes a new image enhance method based on dictionary learning. Particularly, the proposed method adjusts the image by manipulating the rarity of dictionary atoms. Firstly, learn the dictionary through sparse coding algorithms on divided sub-image blocks. Secondly, compute the rarity of dictionary atoms on statistics of the corresponding sparse coefficients. Thirdly, adjust the rarity according to specific application and form a new dictionary. Finally, reconstruct the image using the updated dictionary and sparse coefficients. Compared with the traditional techniques, the proposed method enhances image based on the image content not on distribution of pixel grey value or frequency. The advantages of the proposed method lie in that it is in better correspondence with the response of the human visual system and more suitable for salient objects extraction. The experimental results demonstrate the effectiveness of the proposed image enhance method.
Multi-view Face Analysis Based on Gabor Features
Mar 06, 2014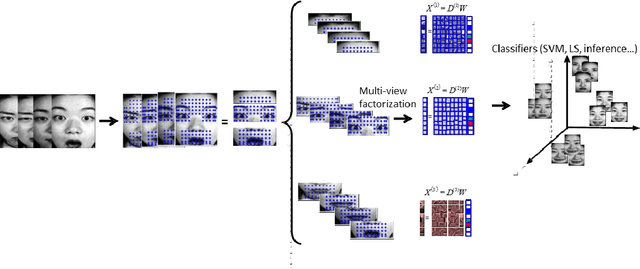
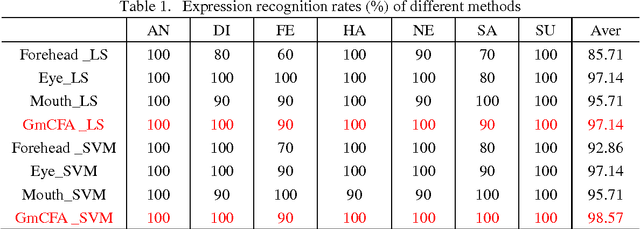


Facial analysis has attracted much attention in the technology for human-machine interface. Different methods of classification based on sparse representation and Gabor kernels have been widely applied in the fields of facial analysis. However, most of these methods treat face from a whole view standpoint. In terms of the importance of different facial views, in this paper, we present multi-view face analysis based on sparse representation and Gabor wavelet coefficients. To evaluate the performance, we conduct face analysis experiments including face recognition (FR) and face expression recognition (FER) on JAFFE database. Experiments are conducted from two parts: (1) Face images are divided into three facial parts which are forehead, eye and mouth. (2) Face images are divided into 8 parts by the orientation of Gabor kernels. Experimental results demonstrate that the proposed methods can significantly boost the performance and perform better than the other methods.
* 8 pages, 3 figures, Journal of Information and Computational Science