 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoDo: Contrastive Learning with Downstream Background Invariance for Detection
Paper and Code
May 10, 2022
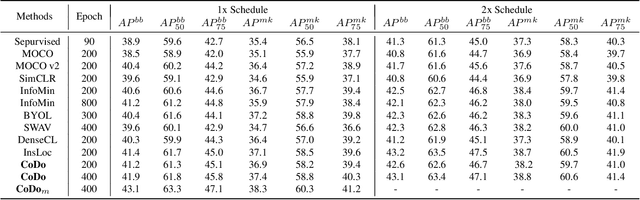


The prior self-supervised learning researches mainly select image-level instance discrimination as pretext task. It achieves a fantastic classification performance that is comparable to supervised learning methods. However, with degraded transfer performance on downstream tasks such as object detection. To bridge the performance gap, we propose a novel object-level self-supervised learning method, called Contrastive learning with Downstream background invariance (CoDo). The pretext task is converted to focus on instance location modeling for various backgrounds, especially for downstream datasets. The ability of background invariance is considered vital for object detection. Firstly, a data augmentation strategy is proposed to paste the instances onto background images, and then jitter the bounding box to involve background information. Secondly, we implement architecture alignment between our pretraining network and the mainstream detection pipelines. Thirdly, hierarchical and multi views contrastive learning is designed to improve performance of visual representation learning. Experiments on MSCOCO demonstrate that the proposed CoDo with common backbones, ResNet50-FPN, yields strong transfer learning results for object detection.