 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Unified Deep Speaker Embedding Framework for Mixed-Bandwidth Speech Data
Dec 01, 2020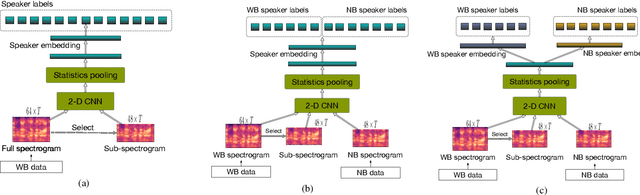
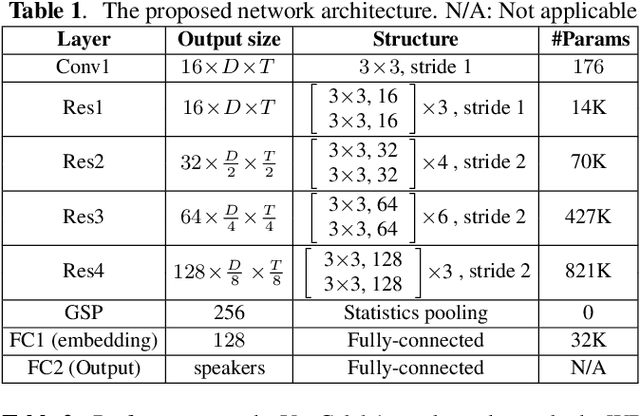
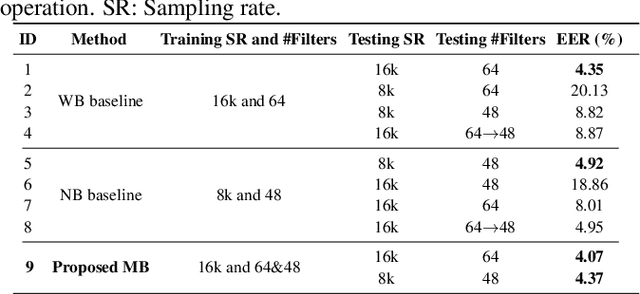
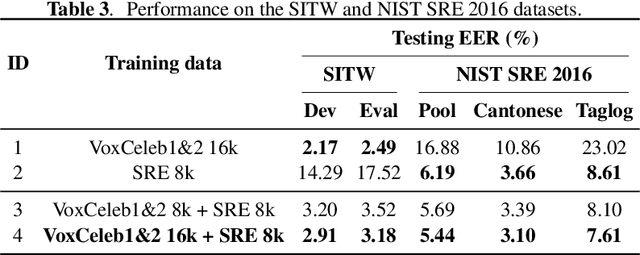
This paper proposes a unified deep speaker embedding framework for modeling speech data with different sampling rates. Considering the narrowband spectrogram as a sub-image of the wideband spectrogram, we tackle the joint modeling problem of the mixed-bandwidth data in an image classification manner. From this perspective, we elaborate several mixed-bandwidth joint training strategies under different training and test data scenarios. The proposed systems are able to flexibly handle the mixed-bandwidth speech data in a single speaker embedding model without any additional downsampling, upsampling, bandwidth extension, or padding operations. We conduct extensive experimental studies on the VoxCeleb1 dataset. Furthermore, the effectiveness of the proposed approach is validated by the SITW and NIST SRE 2016 datasets.
DIHARD II is Still Hard: Experimental Results and Discussions from the DKU-LENOVO Team
Feb 23, 2020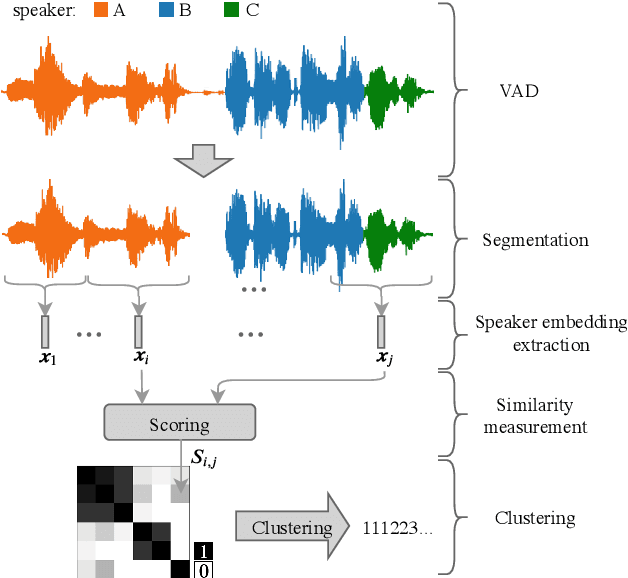
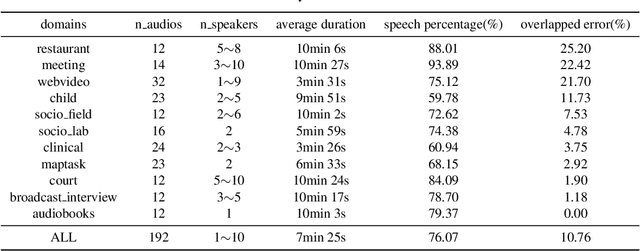
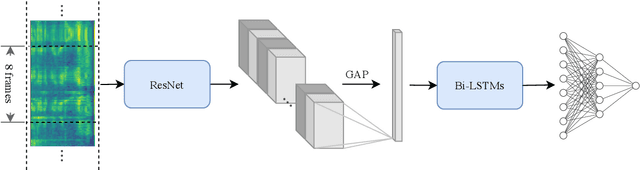
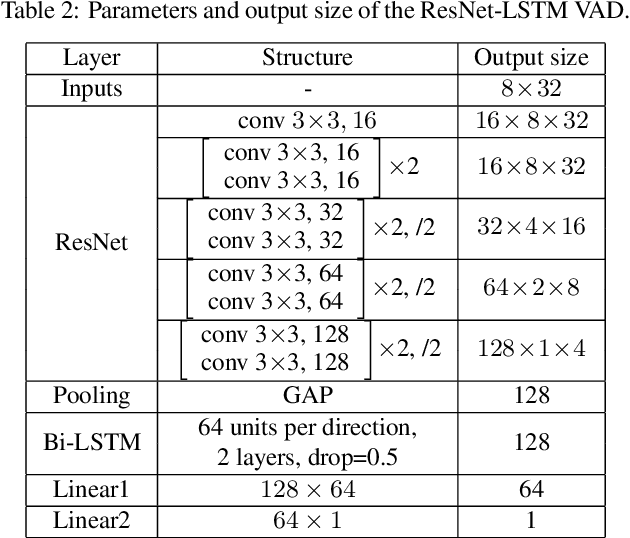
In this paper, we present the submitted system for the second DIHARD Speech Diarization Challenge from the DKULENOVO team. Our diarization system includes multiple modules, namely voice activity detection (VAD), segmentation, speaker embedding extraction, similarity scoring, clustering, resegmentation and overlap detection. For each module, we explore different techniques to enhance performance. Our final submission employs the ResNet-LSTM based VAD, the Deep ResNet based speaker embedding, the LSTM based similarity scoring and spectral clustering. Variational Bayes (VB) diarization is applied in the resegmentation stage and overlap detection also brings slight improvement. Our proposed system achieves 18.84% DER in Track1 and 27.90% DER in Track2. Although our systems have reduced the DERs by 27.5% and 31.7% relatively against the official baselines, we believe that the diarization task is still very difficult.
The DKU Replay Detection System for the ASVspoof 2019 Challenge: On Data Augmentation, Feature Representation, Classification, and Fusion
Jul 05, 2019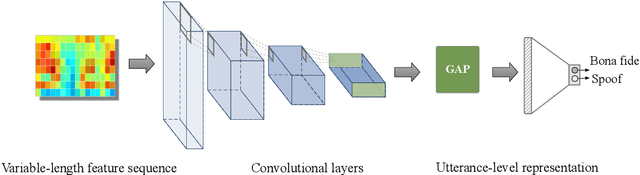
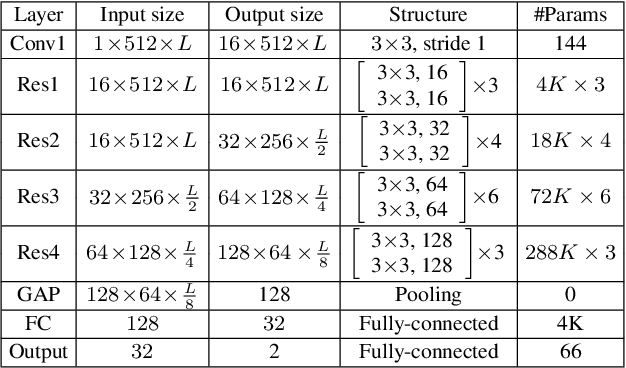
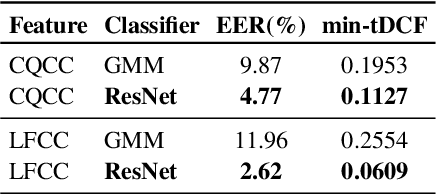
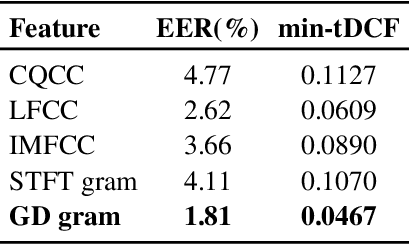
This paper describes our DKU replay detection system for the ASVspoof 2019 challenge. The goal is to develop spoofing countermeasure for automatic speaker recognition in physical access scenario. We leverage the countermeasure system pipeline from four aspects, including the data augmentation, feature representation, classification, and fusion. First, we introduce an utterance-level deep learning framework for anti-spoofing. It receives the variable-length feature sequence and outputs the utterance-level scores directly. Based on the framework, we try out various kinds of input feature representations extracted from either the magnitude spectrum or phase spectrum. Besides, we also perform the data augmentation strategy by applying the speed perturbation on the raw waveform. Our best single system employs a residual neural network trained by the speed-perturbed group delay gram. It achieves EER of 1.04% on the development set, as well as EER of 1.08% on the evaluation set. Finally, using the simple average score from several single systems can further improve the performance. EER of 0.24% on the development set and 0.66% on the evaluation set is obtained for our primary system.
Utterance-level end-to-end language identification using attention-based CNN-BLSTM
Feb 20, 2019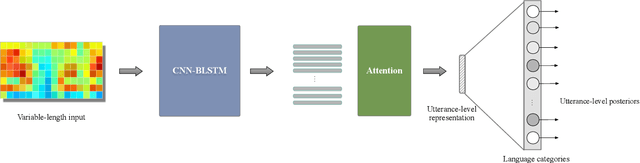


In this paper, we present an end-to-end language identification framework, the attention-based Convolutional Neural Network-Bidirectional Long-short Term Memory (CNN-BLSTM). The model is performed on the utterance level, which means the utterance-level decision can be directly obtained from the output of the neural network. To handle speech utterances with entire arbitrary and potentially long duration, we combine CNN-BLSTM model with a self-attentive pooling layer together. The front-end CNN-BLSTM module plays a role as local pattern extractor for the variable-length inputs, and the following self-attentive pooling layer is built on top to get the fixed-dimensional utterance-level representation. We conducted experiments on NIST LRE07 closed-set task, and the results reveal that the proposed attention-based CNN-BLSTM model achieves comparable error reduction with other state-of-the-art utterance-level neural network approaches for all 3 seconds, 10 seconds, 30 seconds duration tasks.
End-to-end Language Identification using NetFV and NetVLAD
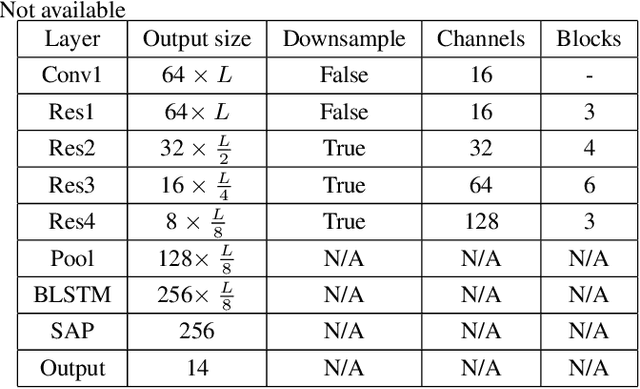
Sep 09, 2018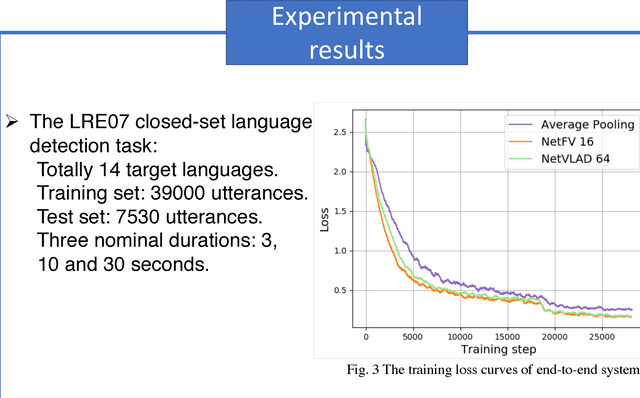
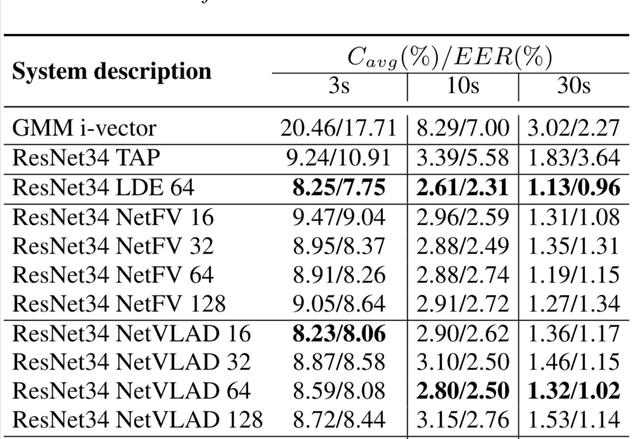
In this paper, we apply the NetFV and NetVLAD layers for the end-to-end language identification task. NetFV and NetVLAD layers are the differentiable implementations of the standard Fisher Vector and Vector of Locally Aggregated Descriptors (VLAD) methods, respectively. Both of them can encode a sequence of feature vectors into a fixed dimensional vector which is very important to process those variable-length utterances. We first present the relevances and differences between the classical i-vector and the aforementioned encoding schemes. Then, we construct a flexible end-to-end framework including a convolutional neural network (CNN) architecture and an encoding layer (NetFV or NetVLAD) for the language identification task. Experimental results on the NIST LRE 2007 close-set task show that the proposed system achieves significant EER reductions against the conventional i-vector baseline and the CNN temporal average pooling system, respectively.
Exploring the Encoding Layer and Loss Function in End-to-End Speaker and Language Recognition System
Apr 14, 2018


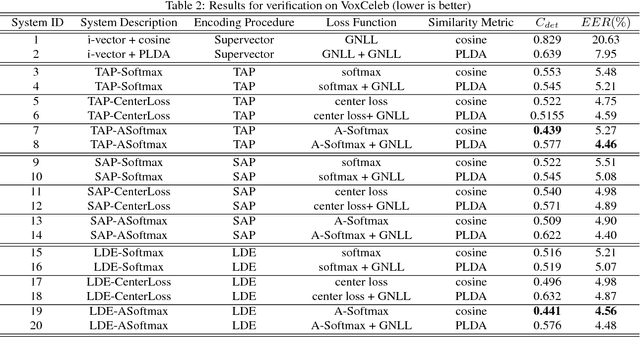
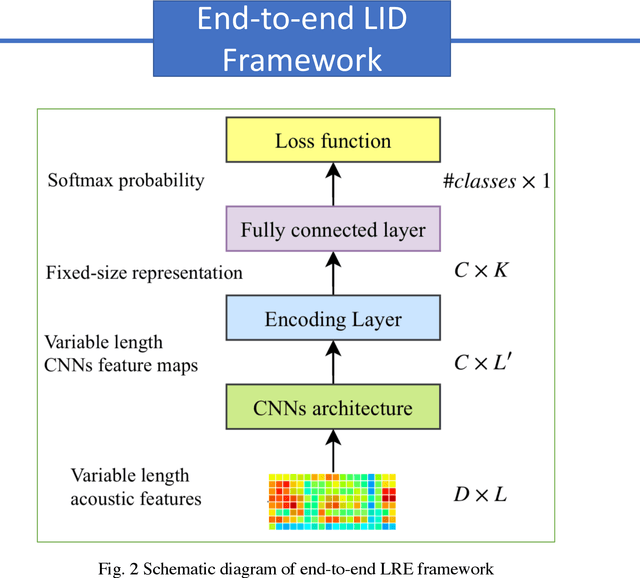
In this paper, we explore the encoding/pooling layer and loss function in the end-to-end speaker and language recognition system. First, a unified and interpretable end-to-end system for both speaker and language recognition is developed. It accepts variable-length input and produces an utterance level result. In the end-to-end system, the encoding layer plays a role in aggregating the variable-length input sequence into an utterance level representation. Besides the basic temporal average pooling, we introduce a self-attentive pooling layer and a learnable dictionary encoding layer to get the utterance level representation. In terms of loss function for open-set speaker verification, to get more discriminative speaker embedding, center loss and angular softmax loss is introduced in the end-to-end system. Experimental results on Voxceleb and NIST LRE 07 datasets show that the performance of end-to-end learning system could be significantly improved by the proposed encoding layer and loss function.
A Novel Learnable Dictionary Encoding Layer for End-to-End Language Identification
Apr 02, 2018
A novel learnable dictionary encoding layer is proposed in this paper for end-to-end language identification. It is inline with the conventional GMM i-vector approach both theoretically and practically. We imitate the mechanism of traditional GMM training and Supervector encoding procedure on the top of CNN. The proposed layer can accumulate high-order statistics from variable-length input sequence and generate an utterance level fixed-dimensional vector representation. Unlike the conventional methods, our new approach provides an end-to-end learning framework, where the inherent dictionary are learned directly from the loss function. The dictionaries and the encoding representation for the classifier are learned jointly. The representation is orderless and therefore appropriate for language identification. We conducted a preliminary experiment on NIST LRE07 closed-set task, and the results reveal that our proposed dictionary encoding layer achieves significant error reduction comparing with the simple average pooling.
Insights into End-to-End Learning Scheme for Language Identification
Apr 02, 2018
A novel interpretable end-to-end learning scheme for language identification is proposed. It is in line with the classical GMM i-vector methods both theoretically and practically. In the end-to-end pipeline, a general encoding layer is employed on top of the front-end CNN, so that it can encode the variable-length input sequence into an utterance level vector automatically. After comparing with the state-of-the-art GMM i-vector methods, we give insights into CNN, and reveal its role and effect in the whole pipeline. We further introduce a general encoding layer, illustrating the reason why they might be appropriate for language identification. We elaborate on several typical encoding layers, including a temporal average pooling layer, a recurrent encoding layer and a novel learnable dictionary encoding layer. We conducted experiment on NIST LRE07 closed-set task, and the results show that our proposed end-to-end systems achieve state-of-the-art performance.
The SYSU System for the Interspeech 2015 Automatic Speaker Verification Spoofing and Countermeasures Challenge
Jul 29, 2015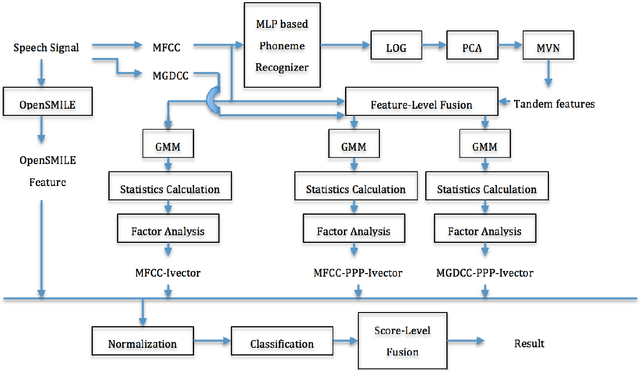
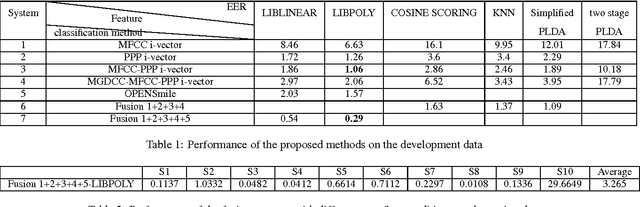


Many existing speaker verification systems are reported to be vulnerable against different spoofing attacks, for example speaker-adapted speech synthesis, voice conversion, play back, etc. In order to detect these spoofed speech signals as a countermeasure, we propose a score level fusion approach with several different i-vector subsystems. We show that the acoustic level Mel-frequency cepstral coefficients (MFCC) features, the phase level modified group delay cepstral coefficients (MGDCC) and the phonetic level phoneme posterior probability (PPP) tandem features are effective for the countermeasure. Furthermore, feature level fusion of these features before i-vector modeling also enhance the performance. A polynomial kernel support vector machine is adopted as the supervised classifier. In order to enhance the generalizability of the countermeasure, we also adopted the cosine similarity and PLDA scoring as one-class classifications methods. By combining the proposed i-vector subsystems with the OpenSMILE baseline which covers the acoustic and prosodic information further improves the final performance. The proposed fusion system achieves 0.29% and 3.26% EER on the development and test set of the database provided by the INTERSPEECH 2015 automatic speaker verification spoofing and countermeasures challenge.