 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe DKU Replay Detection System for the ASVspoof 2019 Challenge: On Data Augmentation, Feature Representation, Classification, and Fusion
Paper and Code
Jul 05, 2019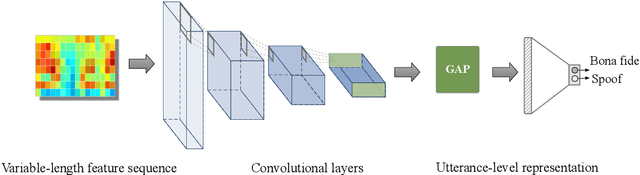
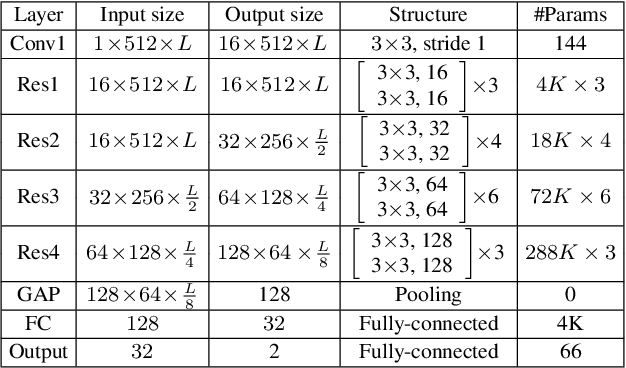
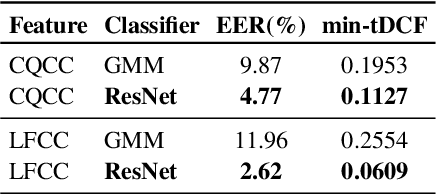
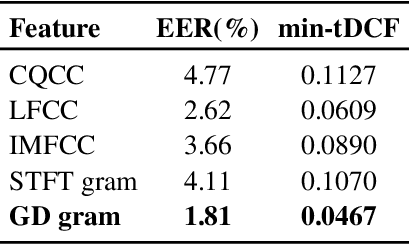
This paper describes our DKU replay detection system for the ASVspoof 2019 challenge. The goal is to develop spoofing countermeasure for automatic speaker recognition in physical access scenario. We leverage the countermeasure system pipeline from four aspects, including the data augmentation, feature representation, classification, and fusion. First, we introduce an utterance-level deep learning framework for anti-spoofing. It receives the variable-length feature sequence and outputs the utterance-level scores directly. Based on the framework, we try out various kinds of input feature representations extracted from either the magnitude spectrum or phase spectrum. Besides, we also perform the data augmentation strategy by applying the speed perturbation on the raw waveform. Our best single system employs a residual neural network trained by the speed-perturbed group delay gram. It achieves EER of 1.04% on the development set, as well as EER of 1.08% on the evaluation set. Finally, using the simple average score from several single systems can further improve the performance. EER of 0.24% on the development set and 0.66% on the evaluation set is obtained for our primary system.