 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised Reflective Learning through Self-distillation and Online Clustering for Speaker Representation Learning
Jan 03, 2024


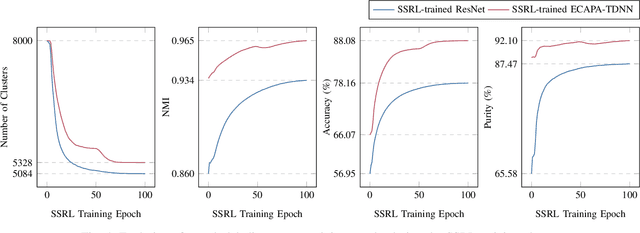
Speaker representation learning is critical for modern voice recognition systems. While supervised learning techniques require extensive labeled data, unsupervised methodologies can leverage vast unlabeled corpora, offering a scalable solution. This paper introduces self-supervised reflective learning (SSRL), a novel paradigm that streamlines existing iterative unsupervised frameworks. SSRL integrates self-supervised knowledge distillation with online clustering to refine pseudo labels and train the model without iterative bottlenecks. Specifically, a teacher model continually refines pseudo labels through online clustering, providing dynamic supervision signals to train the student model. The student model undergoes noisy student training with input and model noise to boost its modeling capacity. The teacher model is updated via an exponential moving average of the student, acting as an ensemble of past iterations. Further, a pseudo label queue retains historical labels for consistency, and noisy label modeling directs learning towards clean samples. Experiments on VoxCeleb show SSRL's superiority over current iterative approaches, surpassing the performance of a 5-round method in just a single training round. Ablation studies validate the contributions of key components like noisy label modeling and pseudo label queues. Moreover, consistent improvements in pseudo labeling and the convergence of cluster counts demonstrate SSRL's effectiveness in deciphering unlabeled data. This work marks an important advancement in efficient and accurate speaker representation learning through the novel reflective learning paradigm.
Leveraging ASR Pretrained Conformers for Speaker Verification through Transfer Learning and Knowledge Distillation
Sep 06, 2023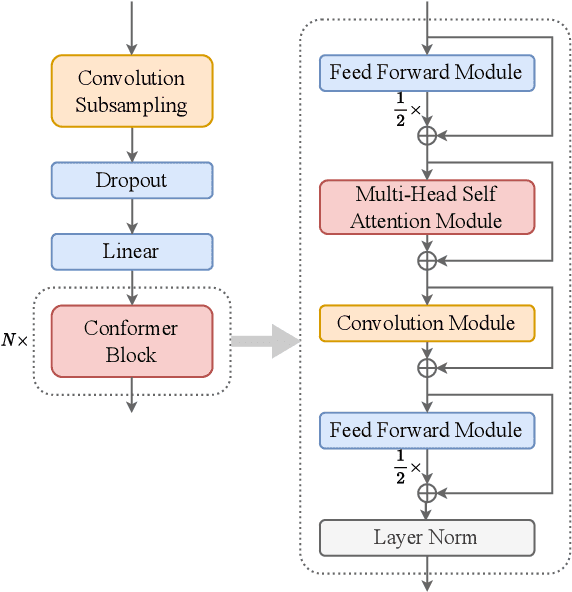
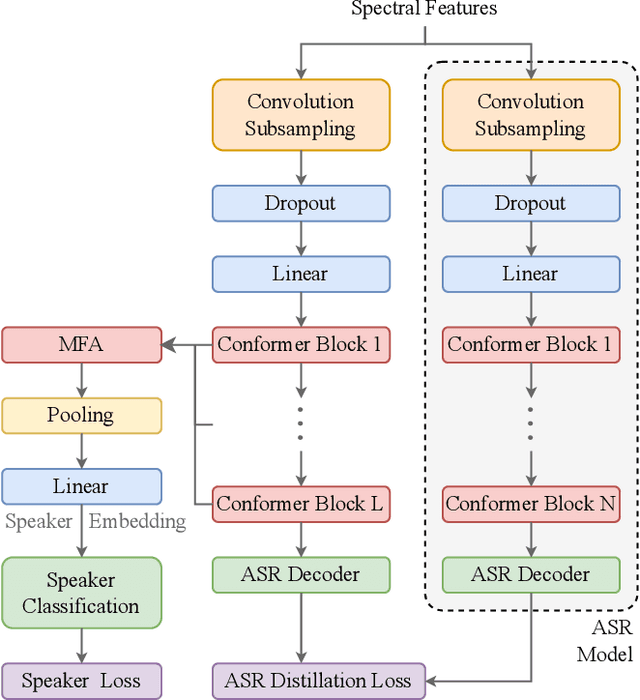
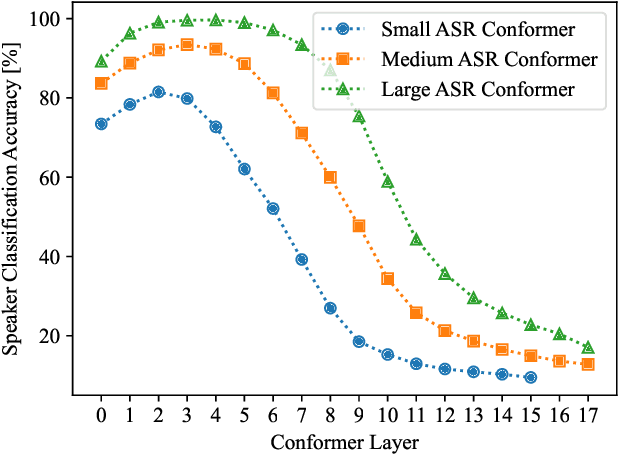
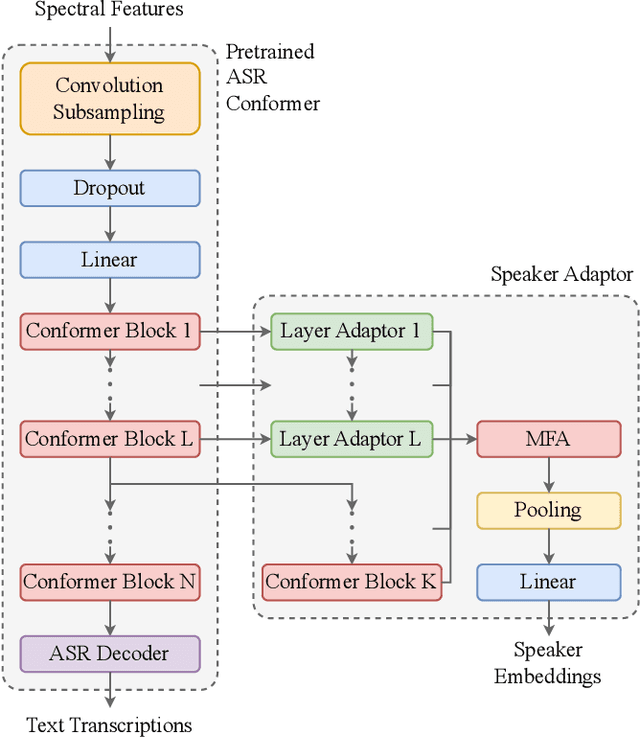
This paper explores the use of ASR-pretrained Conformers for speaker verification, leveraging their strengths in modeling speech signals. We introduce three strategies: (1) Transfer learning to initialize the speaker embedding network, improving generalization and reducing overfitting. (2) Knowledge distillation to train a more flexible speaker verification model, incorporating frame-level ASR loss as an auxiliary task. (3) A lightweight speaker adaptor for efficient feature conversion without altering the original ASR Conformer, allowing parallel ASR and speaker verification. Experiments on VoxCeleb show significant improvements: transfer learning yields a 0.48% EER, knowledge distillation results in a 0.43% EER, and the speaker adaptor approach, with just an added 4.92M parameters to a 130.94M-parameter model, achieves a 0.57% EER. Overall, our methods effectively transfer ASR capabilities to speaker verification tasks.
Identifying Source Speakers for Voice Conversion based Spoofing Attacks on Speaker Verification Systems
Jun 18, 2022
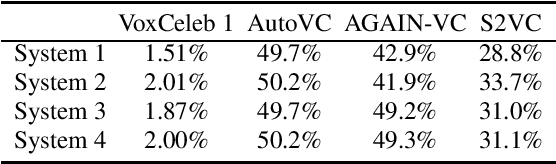


An automatic speaker verification system aims to verify the speaker identity of a speech signal. However, a voice conversion system manipulates the original person's speech signal to make it sound like the target speaker's voice and deceive the speaker verification system. Most countermeasures for voice conversion-based spoofing attacks are designed to discriminate bona fide speech from spoofed speech for speaker verification systems. In this paper, we investigate the problem of source speaker identification -- inferring the identity of the source speaker given the voice converted speech. To perform source speaker identification, we simply add voice-converted speech data with the label of source speaker identity to the genuine speech dataset during speaker embedding network training. Experimental results show the feasibility of source speaker identification when training and testing with converted speeches from the same voice conversion model(s). When testing on converted speeches from an unseen voice conversion algorithm, the performance of source speaker identification improves when more voice conversion models are used during training.
The DKU-DukeECE System for the Self-Supervision Speaker Verification Task of the 2021 VoxCeleb Speaker Recognition Challenge
Sep 07, 2021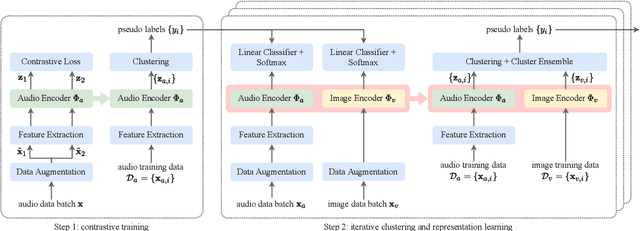
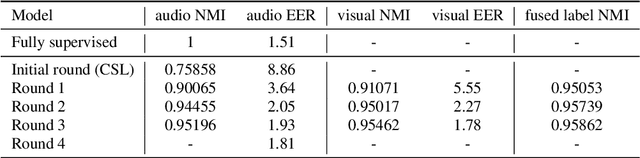

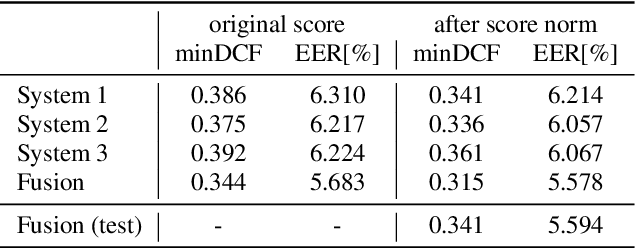
This report describes the submission of the DKU-DukeECE team to the self-supervision speaker verification task of the 2021 VoxCeleb Speaker Recognition Challenge (VoxSRC). Our method employs an iterative labeling framework to learn self-supervised speaker representation based on a deep neural network (DNN). The framework starts with training a self-supervision speaker embedding network by maximizing agreement between different segments within an utterance via a contrastive loss. Taking advantage of DNN's ability to learn from data with label noise, we propose to cluster the speaker embedding obtained from the previous speaker network and use the subsequent class assignments as pseudo labels to train a new DNN. Moreover, we iteratively train the speaker network with pseudo labels generated from the previous step to bootstrap the discriminative power of a DNN. Also, visual modal data is incorporated in this self-labeling framework. The visual pseudo label and the audio pseudo label are fused with a cluster ensemble algorithm to generate a robust supervisory signal for representation learning. Our submission achieves an equal error rate (EER) of 5.58% and 5.59% on the challenge development and test set, respectively.
The DKU-DukeECE-Lenovo System for the Diarization Task of the 2021 VoxCeleb Speaker Recognition Challenge
Sep 07, 2021
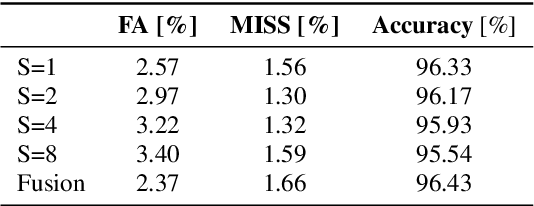


This report describes the submission of the DKU-DukeECE-Lenovo team to the VoxCeleb Speaker Recognition Challenge (VoxSRC) 2021 track 4. Our system including a voice activity detection (VAD) model, a speaker embedding model, two clustering-based speaker diarization systems with different similarity measurements, two different overlapped speech detection (OSD) models, and a target-speaker voice activity detection (TS-VAD) model. Our final submission, consisting of 5 independent systems, achieves a DER of 5.07% on the challenge test set.
The DKU-Duke-Lenovo System Description for the Third DIHARD Speech Diarization Challenge
Feb 06, 2021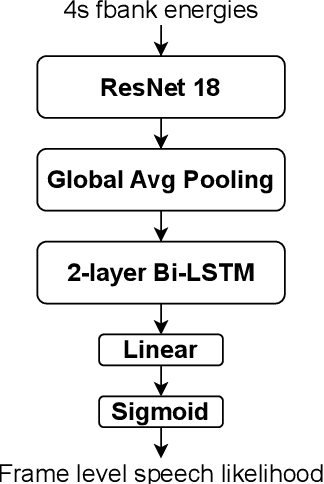
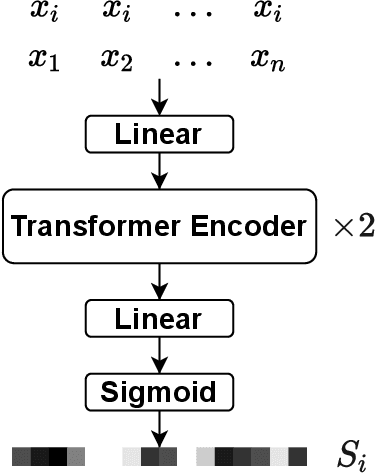

In this paper, we present the submitted system for the third DIHARD Speech Diarization Challenge from the DKU-Duke-Lenovo team. Our system consists of several modules: voice activity detection (VAD), segmentation, speaker embedding extraction, attentive similarity scoring, agglomerative hierarchical clustering. In addition, the target speaker VAD (TSVAD) is used for the phone call data to further improve the performance. Our final submitted system achieves a DER of 15.43% for the core evaluation set and 13.39% for the full evaluation set on task 1, and we also get a DER of 21.63% for core evaluation set and 18.90% for full evaluation set on task 2.
The DKU Replay Detection System for the ASVspoof 2019 Challenge: On Data Augmentation, Feature Representation, Classification, and Fusion
Jul 05, 2019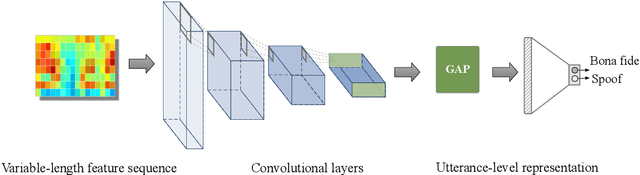
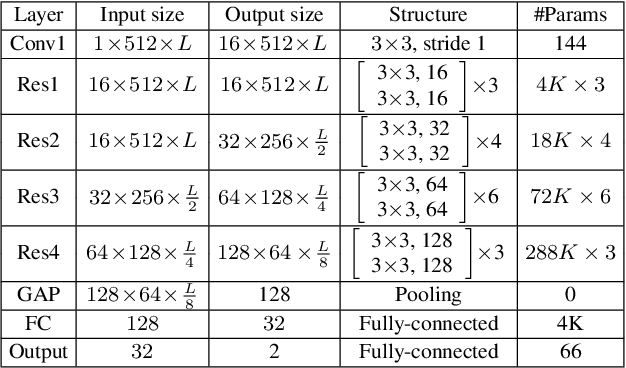
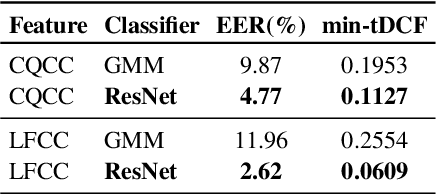
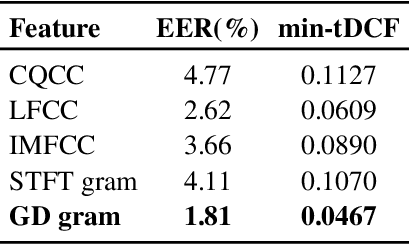
This paper describes our DKU replay detection system for the ASVspoof 2019 challenge. The goal is to develop spoofing countermeasure for automatic speaker recognition in physical access scenario. We leverage the countermeasure system pipeline from four aspects, including the data augmentation, feature representation, classification, and fusion. First, we introduce an utterance-level deep learning framework for anti-spoofing. It receives the variable-length feature sequence and outputs the utterance-level scores directly. Based on the framework, we try out various kinds of input feature representations extracted from either the magnitude spectrum or phase spectrum. Besides, we also perform the data augmentation strategy by applying the speed perturbation on the raw waveform. Our best single system employs a residual neural network trained by the speed-perturbed group delay gram. It achieves EER of 1.04% on the development set, as well as EER of 1.08% on the evaluation set. Finally, using the simple average score from several single systems can further improve the performance. EER of 0.24% on the development set and 0.66% on the evaluation set is obtained for our primary system.
Utterance-level end-to-end language identification using attention-based CNN-BLSTM
Feb 20, 2019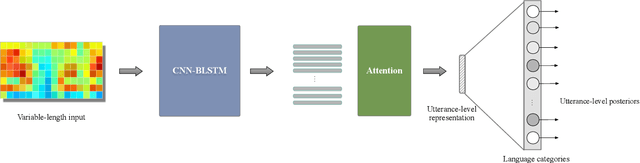


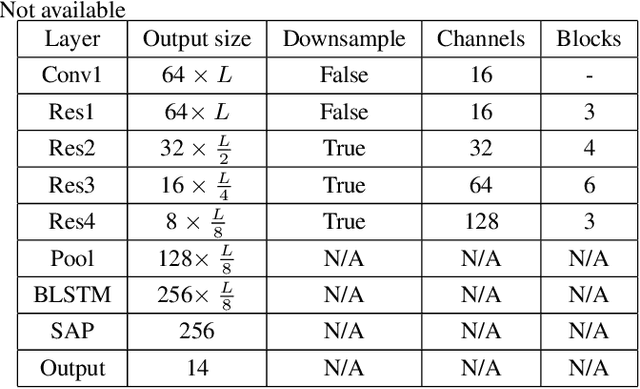
In this paper, we present an end-to-end language identification framework, the attention-based Convolutional Neural Network-Bidirectional Long-short Term Memory (CNN-BLSTM). The model is performed on the utterance level, which means the utterance-level decision can be directly obtained from the output of the neural network. To handle speech utterances with entire arbitrary and potentially long duration, we combine CNN-BLSTM model with a self-attentive pooling layer together. The front-end CNN-BLSTM module plays a role as local pattern extractor for the variable-length inputs, and the following self-attentive pooling layer is built on top to get the fixed-dimensional utterance-level representation. We conducted experiments on NIST LRE07 closed-set task, and the results reveal that the proposed attention-based CNN-BLSTM model achieves comparable error reduction with other state-of-the-art utterance-level neural network approaches for all 3 seconds, 10 seconds, 30 seconds duration tasks.
End-to-end Language Identification using NetFV and NetVLAD
Sep 09, 2018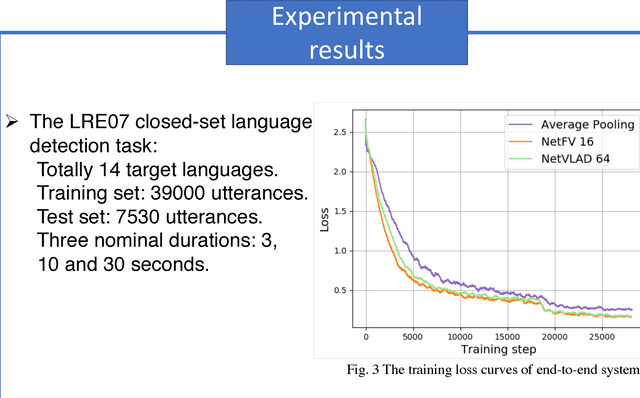
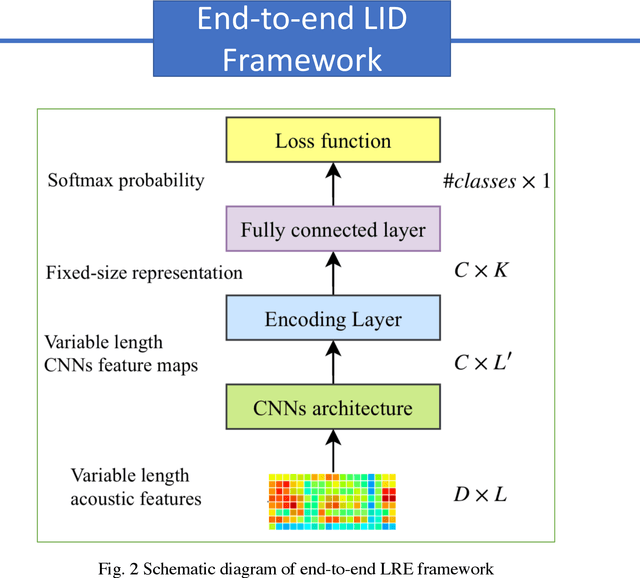
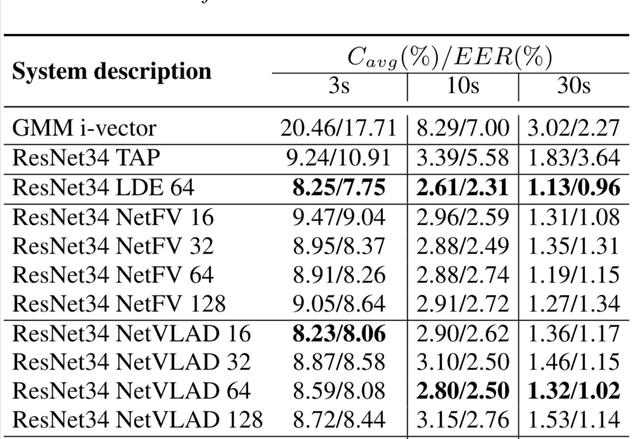
In this paper, we apply the NetFV and NetVLAD layers for the end-to-end language identification task. NetFV and NetVLAD layers are the differentiable implementations of the standard Fisher Vector and Vector of Locally Aggregated Descriptors (VLAD) methods, respectively. Both of them can encode a sequence of feature vectors into a fixed dimensional vector which is very important to process those variable-length utterances. We first present the relevances and differences between the classical i-vector and the aforementioned encoding schemes. Then, we construct a flexible end-to-end framework including a convolutional neural network (CNN) architecture and an encoding layer (NetFV or NetVLAD) for the language identification task. Experimental results on the NIST LRE 2007 close-set task show that the proposed system achieves significant EER reductions against the conventional i-vector baseline and the CNN temporal average pooling system, respectively.