 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStepAudio 2.5 Technical Report
May 22, 2026Unified audio-language modeling has emerged as a prominent trend in modern speech systems, promising to bring the reasoning capabilities of large language models to auditory tasks. However, existing unified foundations often struggle to match the depth of specialized systems across automatic speech recognition (ASR), text-to-speech synthesis (TTS), and realtime spoken interaction. Bridging this gap remains an open challenge. This report presents StepAudio 2.5, a unified audio-language foundation model that matches or exceeds specialized systems across all three capabilities. Rather than treating these tasks as architecturally distinct, we operate on the premise that once text and audio share a multimodal representational space, task specialization becomes a matter of operational regimes: data construction, optimization targets, and decoding constraints. Guided by this insight, we advance the post-training paradigm from standard supervised learning to task-tailored Reinforcement Learning from Human Feedback (RLHF), using it as the primary mechanism to define complex optimization targets. We leverage this RLHF-centric alignment, alongside specialized decoding, to shape a shared backbone into three distinct operational modes. Concretely, the ASR branch advances transcription efficiency via verifiable multi-token decoding; the TTS branch achieves controllable, expressive synthesis through preference-based RLHF and context-rich supervision; and the Realtime branch realizes low-latency, persona-consistent dialogue via generative reward modeling within an RLHF framework. On standard benchmarks, StepAudio 2.5 achieves state-of-the-art results across ASR, TTS, and Realtime, demonstrating that a singular audio-language foundation can successfully internalize the distinct deployment objectives of speech understanding, generation, and live interaction.
DuplexSLA: A Full-Duplex Spoken Language Model with Synchronized Speech, Language, and Action
May 20, 2026Recent advances in spoken dialogue language models have shifted from turn-based to full-duplex designs, where the model continuously listens to the user while generating responses. However, existing duplex backbones still lack a native channel for in-conversation planning and tool calling, leaving real-time agentic behaviour either tied to turn boundaries or relegated to an external cascade. We propose DuplexSLA, a native full-duplex Speech-Language-Action foundation model that decodes assistant audio together with a structured action stream on a shared 160 ms chunk timeline. DuplexSLA is built on a dual-stream three-channel formulation: a continuous user audio channel, a discrete assistant audio channel, and a rate-limited textual action channel, all decoded jointly by a single backbone, so that listening, speaking, planning, and tool calling unfold on one shared clock. Two capabilities define the model: (1) semantic-driven turn-taking control, where interruption, pause, and backchannel are handled inside the same backbone instead of by an external semantic VAD; and (2) in-conversation planning and tool calling, where planning text and structured tool calls are emitted on the action channel without halting assistant audio, so that multi-action and backchannel-triggered tool use are interleaved with ongoing speech. To evaluate these capabilities together, we further construct DuplexSLA-Bench, a duplex benchmark covering pause, interrupt, and backchannel turn-taking together with three styles of in-conversation tool calling. Our project page, interactive demos, and the DuplexSLA-Bench evaluation suite are publicly available at https://github.com/hyzhang24/DuplexSLA.
Step-Audio-R1.5 Technical Report
Apr 28, 2026Recent advancements in large audio language models have extended Chain-of-Thought (CoT) reasoning into the auditory domain, enabling models to tackle increasingly complex acoustic and spoken tasks. To elicit and sustain these extended reasoning chains, the prevailing paradigm -- driven by the success of text-based reasoning models -- overwhelmingly relies on Reinforcement Learning with Verified Rewards (RLVR). However, as models are strictly optimized to distill rich, continuous auditory contexts into isolated, verifiable text labels, a fundamental question arises: are we fostering true audio intelligence, or merely reducing a continuous sensory medium into a discrete puzzle? We identify this as the "verifiable reward trap." While RLVR yields remarkable scores on standardized objective benchmarks, it systematically degrades the real-world conversational feel of audio models. By prioritizing isolated correctness over acoustic nuance, RLVR reduces dynamic interactions to mechanical "answering machines," severely compromising prosodic naturalness, emotional continuity, and user immersion, particularly in long-turn dialogues. To bridge the gap between mechanical objective verification and genuine sensory empathy, we introduce Step-Audio-R1.5, marking a paradigm shift toward Reinforcement Learning from Human Feedback (RLHF) in audio reasoning. Comprehensive evaluations demonstrate that Step-Audio-R1.5 not only maintains robust analytical reasoning but profoundly transforms the interactive experience, redefining the boundaries of deeply immersive long-turn spoken dialogue.
Online Target Speaker Voice Activity Detection for Speaker Diarization
Jul 13, 2022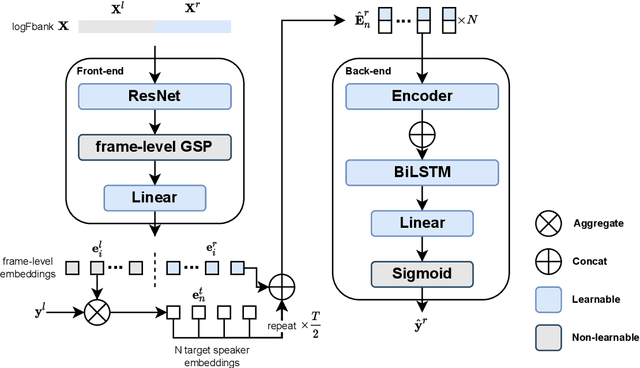
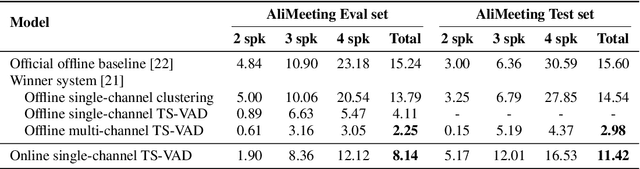
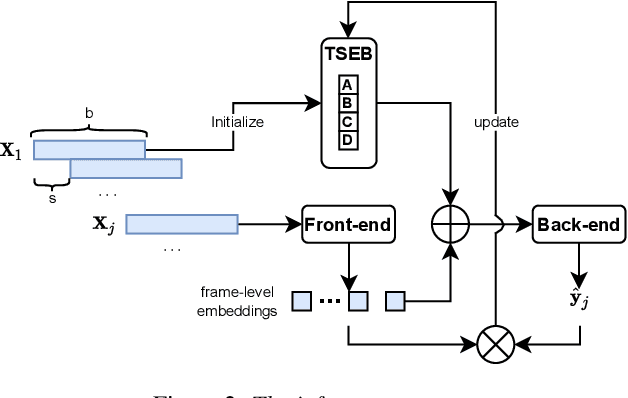
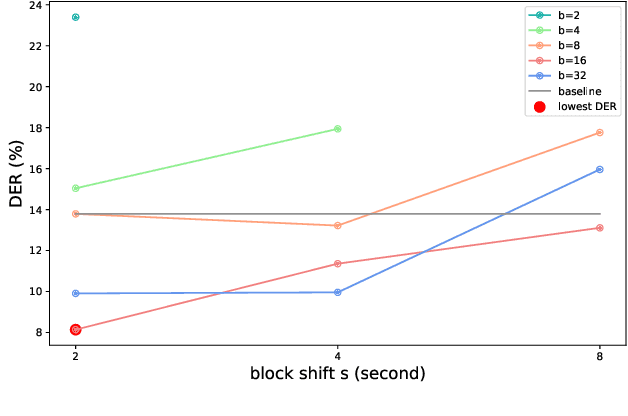
This paper proposes an online target speaker voice activity detection system for speaker diarization tasks, which does not require a priori knowledge from the clustering-based diarization system to obtain the target speaker embeddings. First, we employ a ResNet-based front-end model to extract the frame-level speaker embeddings for each coming block of a signal. Next, we predict the detection state of each speaker based on these frame-level speaker embeddings and the previously estimated target speaker embedding. Then, the target speaker embeddings are updated by aggregating these frame-level speaker embeddings according to the predictions in the current block. We iteratively extract the results for each block and update the target speaker embedding until reaching the end of the signal. Experimental results show that the proposed method is better than the offline clustering-based diarization system on the AliMeeting dataset.
Towards Lightweight Applications: Asymmetric Enroll-Verify Structure for Speaker Verification
Oct 09, 2021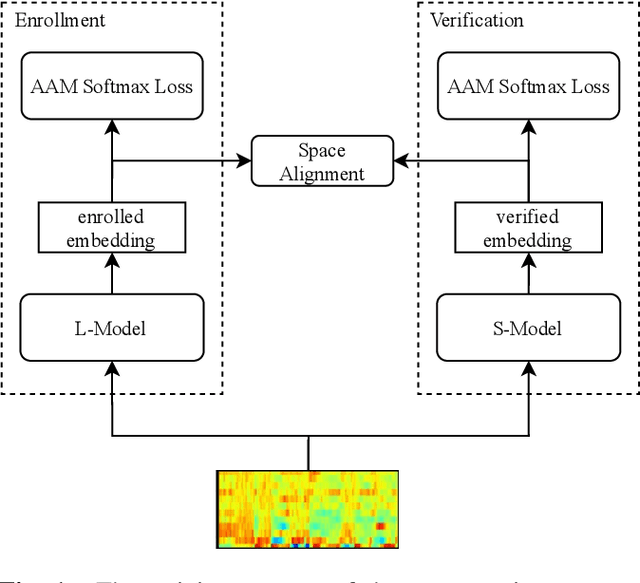
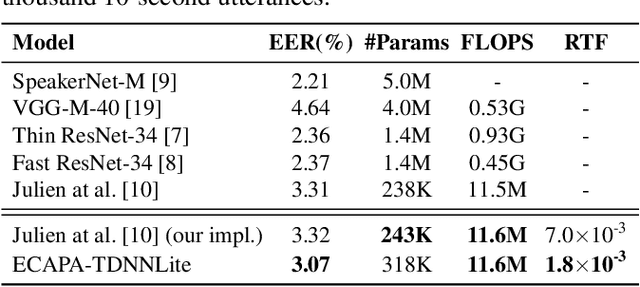
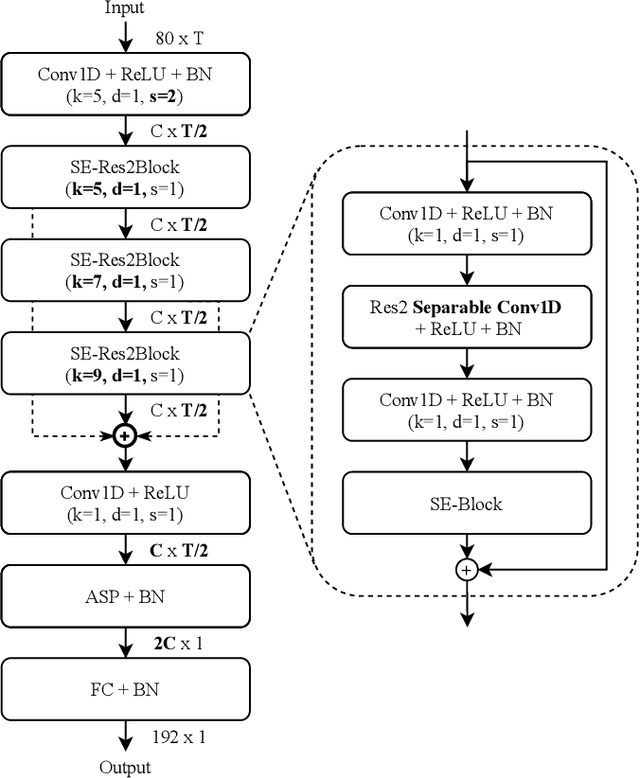

With the development of deep learning, automatic speaker verification has made considerable progress over the past few years. However, to design a lightweight and robust system with limited computational resources is still a challenging problem. Traditionally, a speaker verification system is symmetrical, indicating that the same embedding extraction model is applied for both enrollment and verification in inference. In this paper, we come up with an innovative asymmetric structure, which takes the large-scale ECAPA-TDNN model for enrollment and the small-scale ECAPA-TDNNLite model for verification. As a symmetrical system, our proposed ECAPA-TDNNLite model achieves an EER of 3.07% on the Voxceleb1 original test set with only 11.6M FLOPS. Moreover, the asymmetric structure further reduces the EER to 2.31%, without increasing any computational costs during verification.
The DKU-DukeECE-Lenovo System for the Diarization Task of the 2021 VoxCeleb Speaker Recognition Challenge
Sep 07, 2021
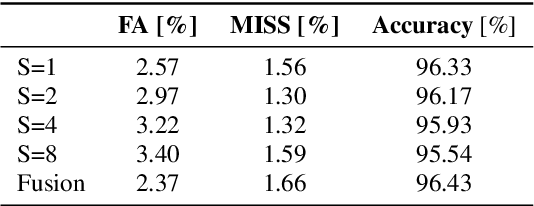


This report describes the submission of the DKU-DukeECE-Lenovo team to the VoxCeleb Speaker Recognition Challenge (VoxSRC) 2021 track 4. Our system including a voice activity detection (VAD) model, a speaker embedding model, two clustering-based speaker diarization systems with different similarity measurements, two different overlapped speech detection (OSD) models, and a target-speaker voice activity detection (TS-VAD) model. Our final submission, consisting of 5 independent systems, achieves a DER of 5.07% on the challenge test set.
Sparsely Overlapped Speech Training in the Time Domain: Joint Learning of Target Speech Separation and Personal VAD Benefits
Jun 28, 2021
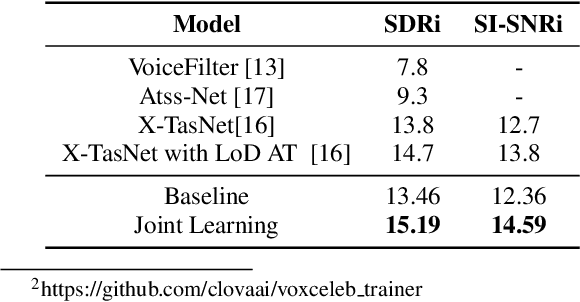
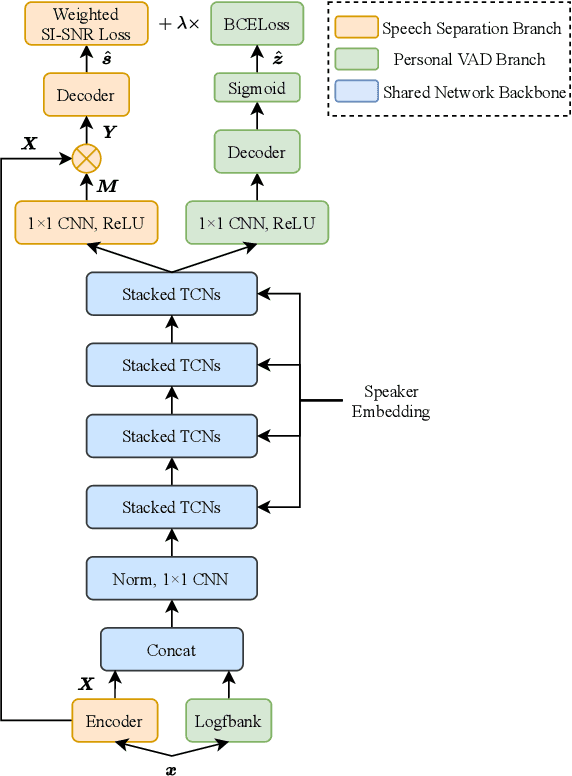
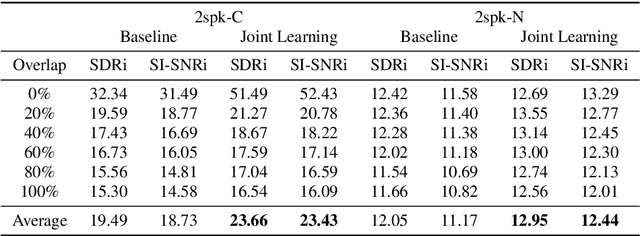
Target speech separation is the process of filtering a certain speaker's voice out of speech mixtures according to the additional speaker identity information provided. Recent works have made considerable improvement by processing signals in the time domain directly. The majority of them take fully overlapped speech mixtures for training. However, since most real-life conversations occur randomly and are sparsely overlapped, we argue that training with different overlap ratio data benefits. To do so, an unavoidable problem is that the popularly used SI-SNR loss has no definition for silent sources. This paper proposes the weighted SI-SNR loss, together with the joint learning of target speech separation and personal VAD. The weighted SI-SNR loss imposes a weight factor that is proportional to the target speaker's duration and returns zero when the target speaker is absent. Meanwhile, the personal VAD generates masks and sets non-target speech to silence. Experiments show that our proposed method outperforms the baseline by 1.73 dB in terms of SDR on fully overlapped speech, as well as by 4.17 dB and 0.9 dB on sparsely overlapped speech of clean and noisy conditions. Besides, with slight degradation in performance, our model could reduce the time costs in inference.
The DKU-Duke-Lenovo System Description for the Third DIHARD Speech Diarization Challenge
Feb 06, 2021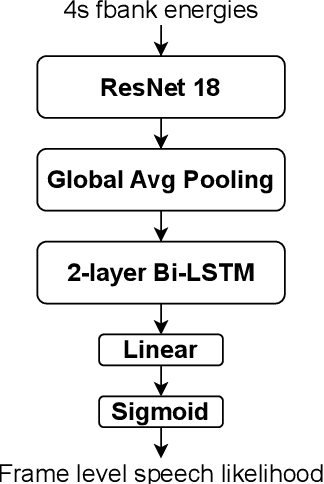
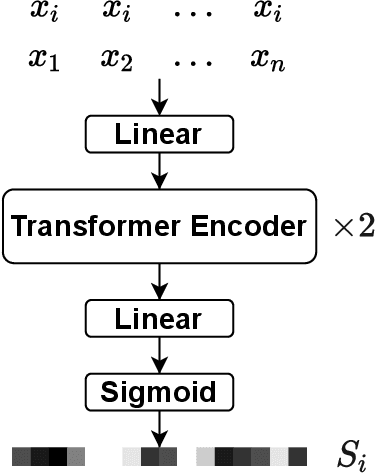
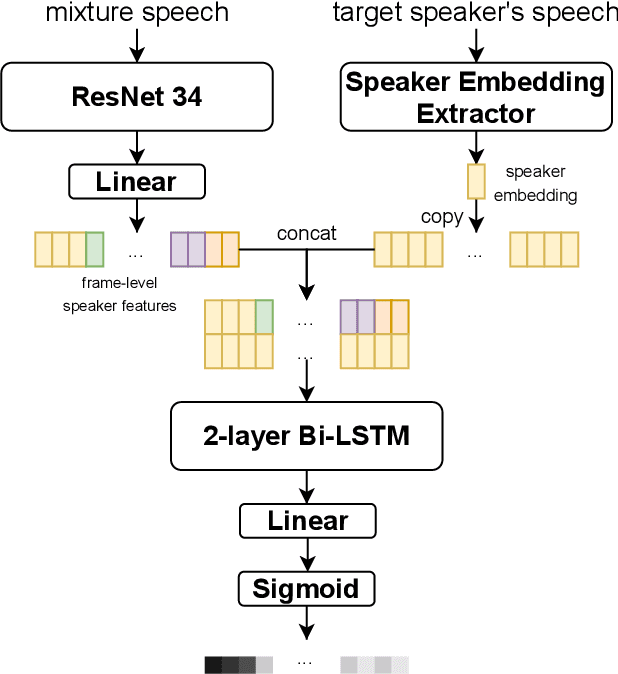

In this paper, we present the submitted system for the third DIHARD Speech Diarization Challenge from the DKU-Duke-Lenovo team. Our system consists of several modules: voice activity detection (VAD), segmentation, speaker embedding extraction, attentive similarity scoring, agglomerative hierarchical clustering. In addition, the target speaker VAD (TSVAD) is used for the phone call data to further improve the performance. Our final submitted system achieves a DER of 15.43% for the core evaluation set and 13.39% for the full evaluation set on task 1, and we also get a DER of 21.63% for core evaluation set and 18.90% for full evaluation set on task 2.
DIHARD II is Still Hard: Experimental Results and Discussions from the DKU-LENOVO Team
Feb 23, 2020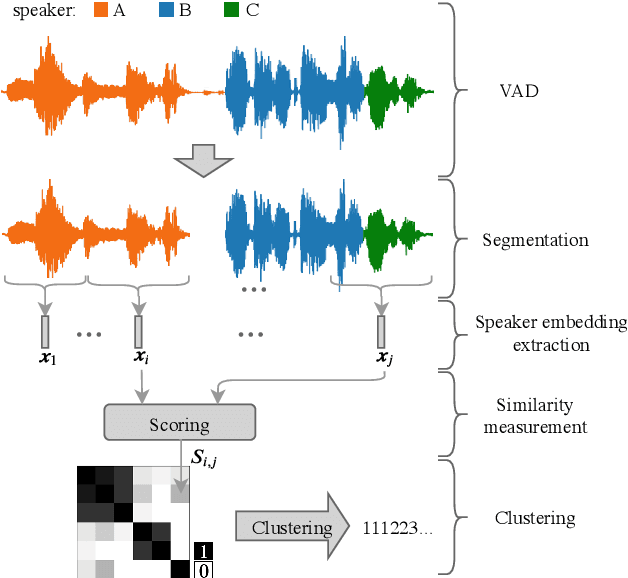
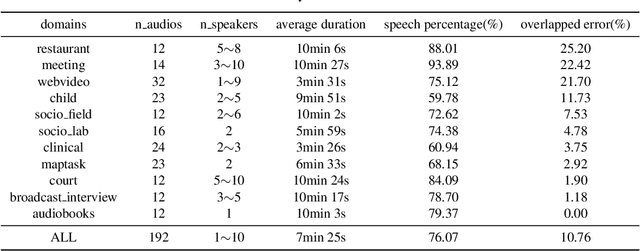
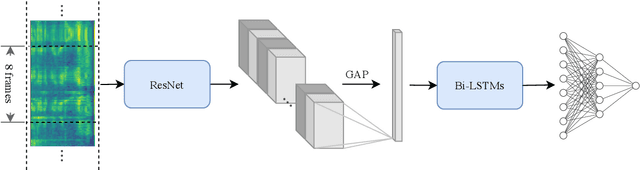
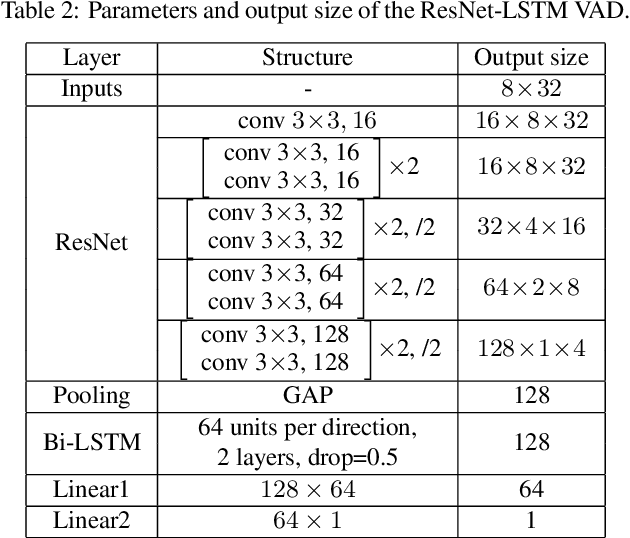
In this paper, we present the submitted system for the second DIHARD Speech Diarization Challenge from the DKULENOVO team. Our diarization system includes multiple modules, namely voice activity detection (VAD), segmentation, speaker embedding extraction, similarity scoring, clustering, resegmentation and overlap detection. For each module, we explore different techniques to enhance performance. Our final submission employs the ResNet-LSTM based VAD, the Deep ResNet based speaker embedding, the LSTM based similarity scoring and spectral clustering. Variational Bayes (VB) diarization is applied in the resegmentation stage and overlap detection also brings slight improvement. Our proposed system achieves 18.84% DER in Track1 and 27.90% DER in Track2. Although our systems have reduced the DERs by 27.5% and 31.7% relatively against the official baselines, we believe that the diarization task is still very difficult.
LSTM based Similarity Measurement with Spectral Clustering for Speaker Diarization
Jul 23, 2019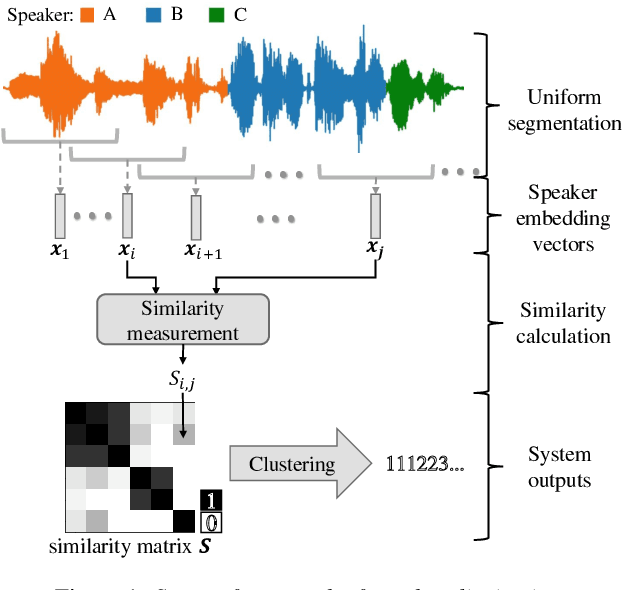
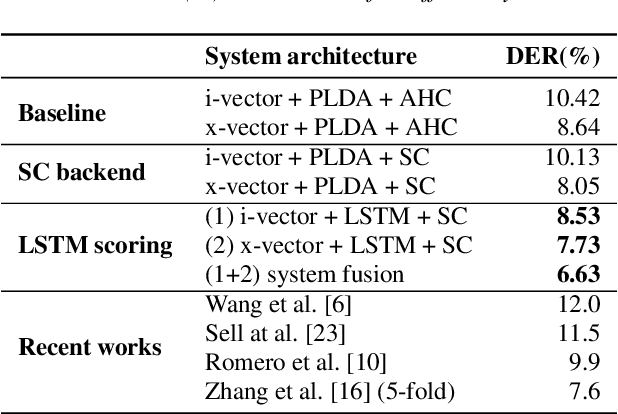
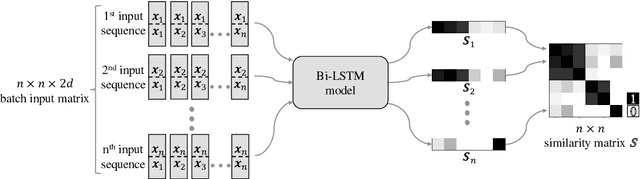
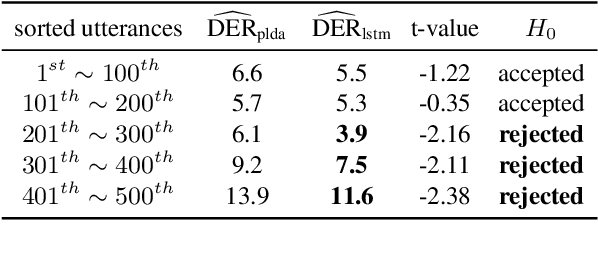
More and more neural network approaches have achieved considerable improvement upon submodules of speaker diarization system, including speaker change detection and segment-wise speaker embedding extraction. Still, in the clustering stage, traditional algorithms like probabilistic linear discriminant analysis (PLDA) are widely used for scoring the similarity between two speech segments. In this paper, we propose a supervised method to measure the similarity matrix between all segments of an audio recording with sequential bidirectional long short-term memory networks (Bi-LSTM). Spectral clustering is applied on top of the similarity matrix to further improve the performance. Experimental results show that our system significantly outperforms the state-of-the-art methods and achieves a diarization error rate of 6.63% on the NIST SRE 2000 CALLHOME database.