 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Lightweight Applications: Asymmetric Enroll-Verify Structure for Speaker Verification
Paper and Code
Oct 09, 2021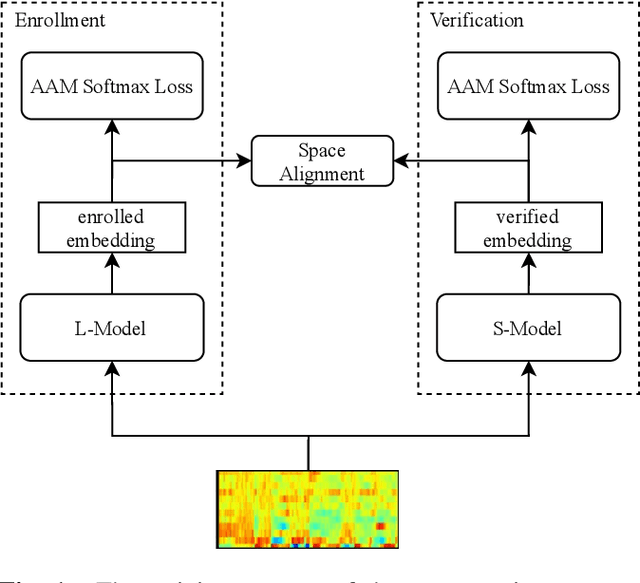
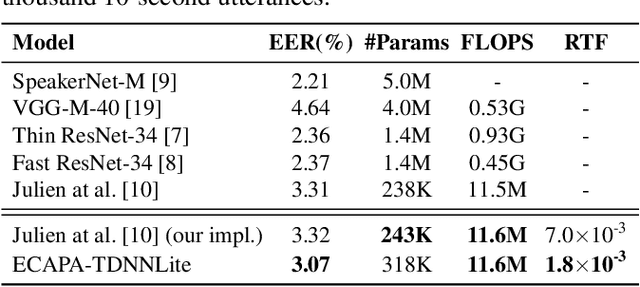
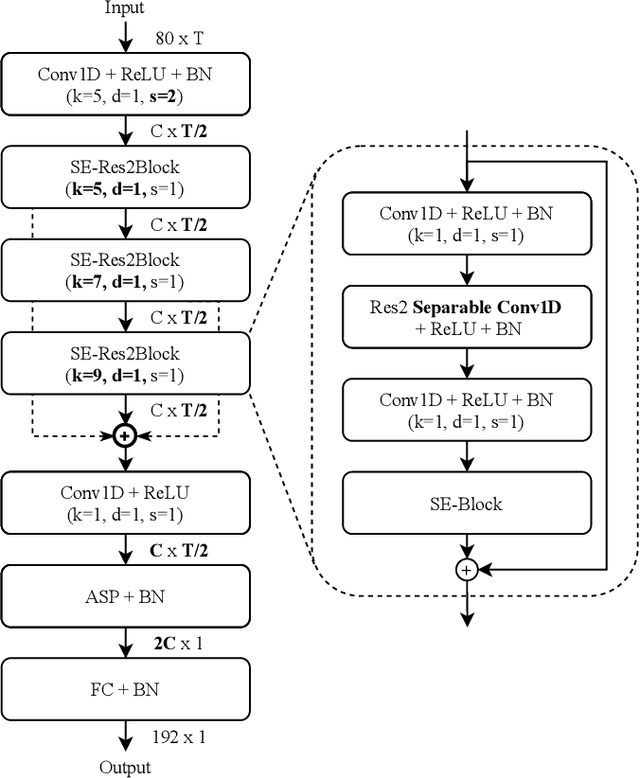

With the development of deep learning, automatic speaker verification has made considerable progress over the past few years. However, to design a lightweight and robust system with limited computational resources is still a challenging problem. Traditionally, a speaker verification system is symmetrical, indicating that the same embedding extraction model is applied for both enrollment and verification in inference. In this paper, we come up with an innovative asymmetric structure, which takes the large-scale ECAPA-TDNN model for enrollment and the small-scale ECAPA-TDNNLite model for verification. As a symmetrical system, our proposed ECAPA-TDNNLite model achieves an EER of 3.07% on the Voxceleb1 original test set with only 11.6M FLOPS. Moreover, the asymmetric structure further reduces the EER to 2.31%, without increasing any computational costs during verification.