 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Speed Submission to DIHARD II: Contributions & Lessons Learned
Nov 06, 2019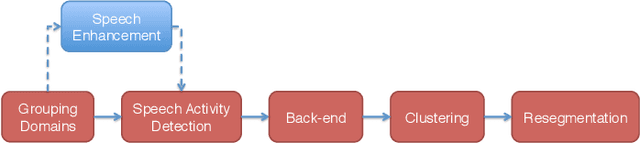
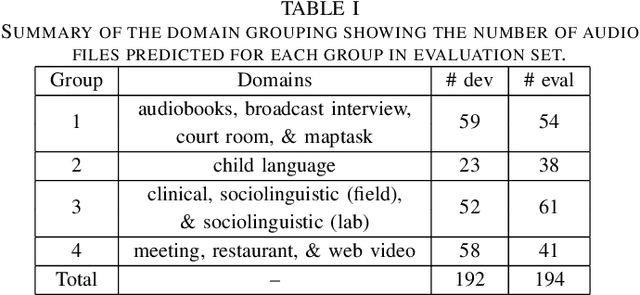


This paper describes the speaker diarization systems developed for the Second DIHARD Speech Diarization Challenge (DIHARD II) by the Speed team. Besides describing the system, which considerably outperformed the challenge baselines, we also focus on the lessons learned from numerous approaches that we tried for single and multi-channel systems. We present several components of our diarization system, including categorization of domains, speech enhancement, speech activity detection, speaker embeddings, clustering methods, resegmentation, and system fusion. We analyze and discuss the effect of each such component on the overall diarization performance within the realistic settings of the challenge.
LSTM based Similarity Measurement with Spectral Clustering for Speaker Diarization
Jul 23, 2019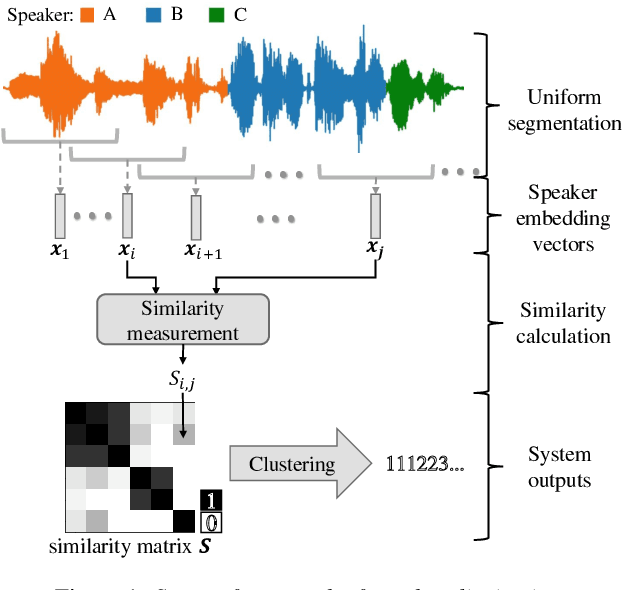
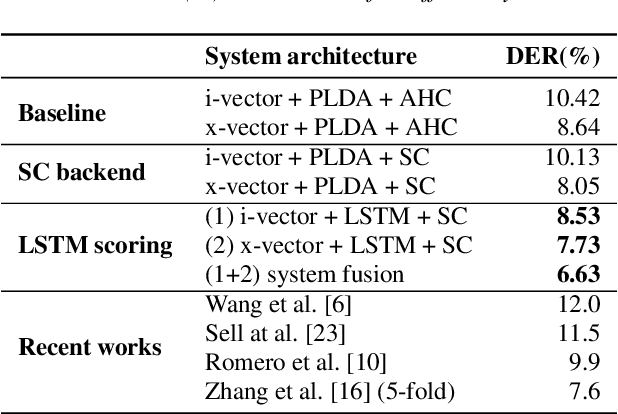
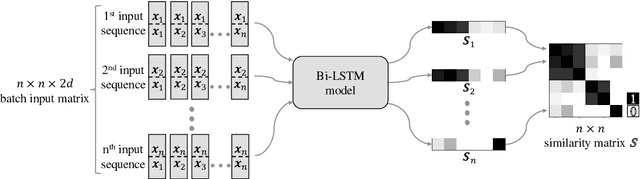
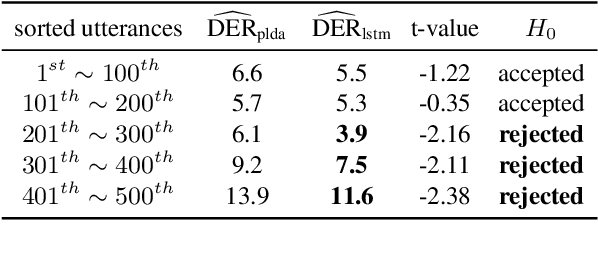
More and more neural network approaches have achieved considerable improvement upon submodules of speaker diarization system, including speaker change detection and segment-wise speaker embedding extraction. Still, in the clustering stage, traditional algorithms like probabilistic linear discriminant analysis (PLDA) are widely used for scoring the similarity between two speech segments. In this paper, we propose a supervised method to measure the similarity matrix between all segments of an audio recording with sequential bidirectional long short-term memory networks (Bi-LSTM). Spectral clustering is applied on top of the similarity matrix to further improve the performance. Experimental results show that our system significantly outperforms the state-of-the-art methods and achieves a diarization error rate of 6.63% on the NIST SRE 2000 CALLHOME database.