 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging ASR Pretrained Conformers for Speaker Verification through Transfer Learning and Knowledge Distillation
Paper and Code
Sep 06, 2023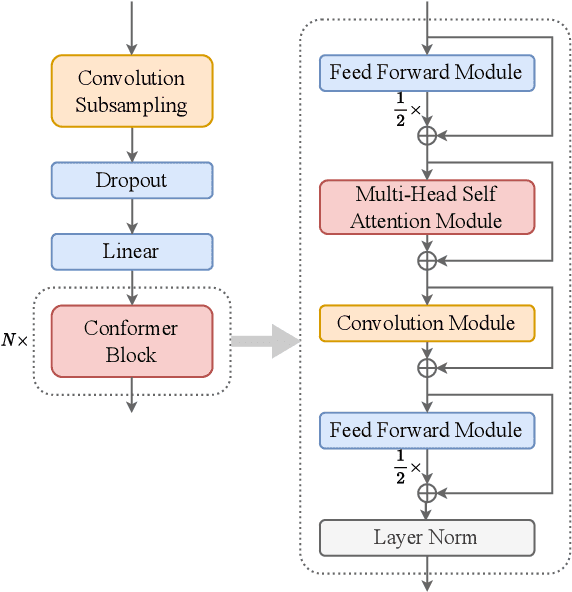
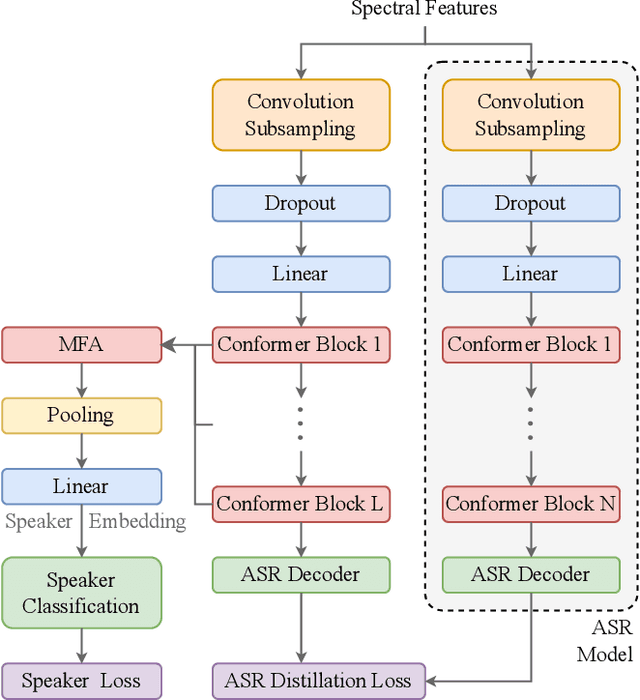
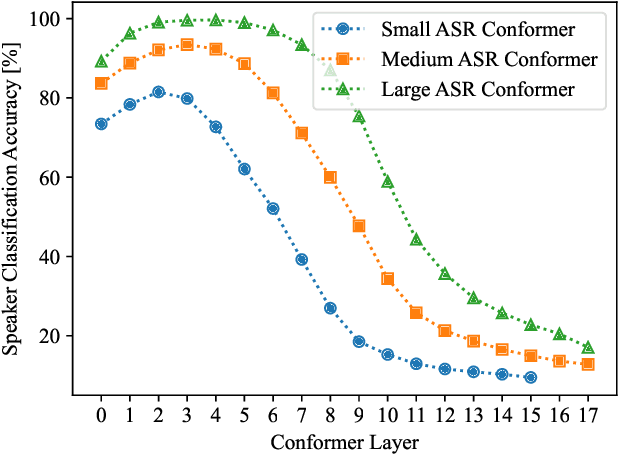
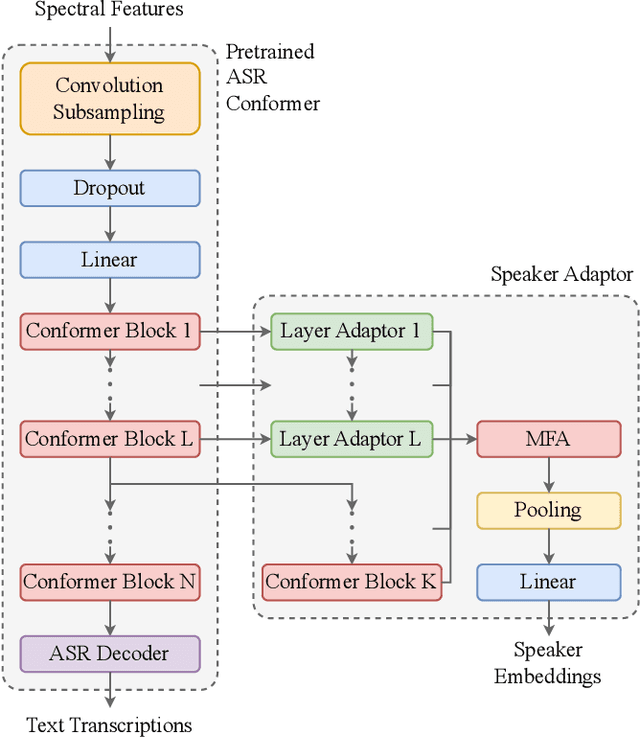
This paper explores the use of ASR-pretrained Conformers for speaker verification, leveraging their strengths in modeling speech signals. We introduce three strategies: (1) Transfer learning to initialize the speaker embedding network, improving generalization and reducing overfitting. (2) Knowledge distillation to train a more flexible speaker verification model, incorporating frame-level ASR loss as an auxiliary task. (3) A lightweight speaker adaptor for efficient feature conversion without altering the original ASR Conformer, allowing parallel ASR and speaker verification. Experiments on VoxCeleb show significant improvements: transfer learning yields a 0.48% EER, knowledge distillation results in a 0.43% EER, and the speaker adaptor approach, with just an added 4.92M parameters to a 130.94M-parameter model, achieves a 0.57% EER. Overall, our methods effectively transfer ASR capabilities to speaker verification tasks.