 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Unified Deep Speaker Embedding Framework for Mixed-Bandwidth Speech Data
Paper and Code
Dec 01, 2020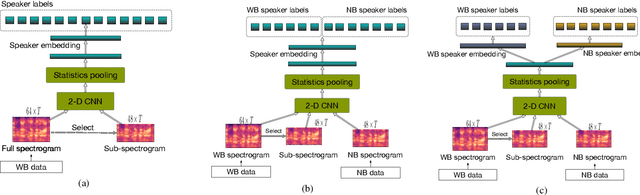
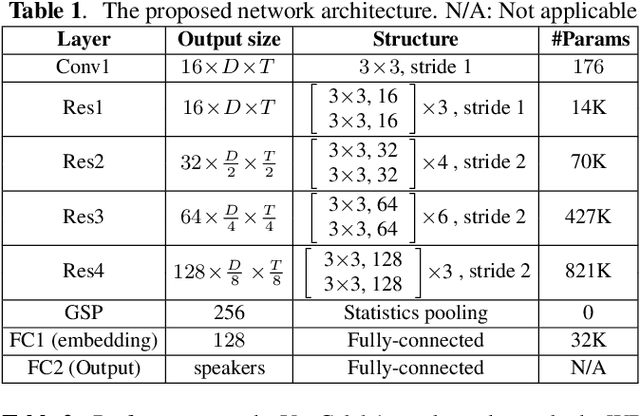
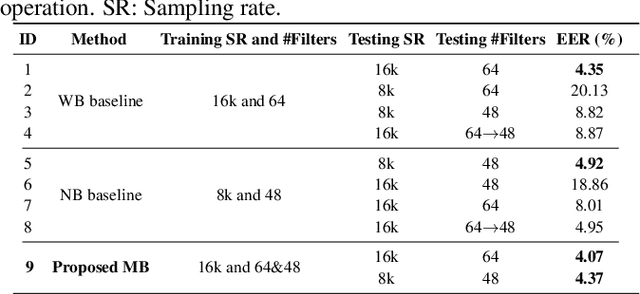
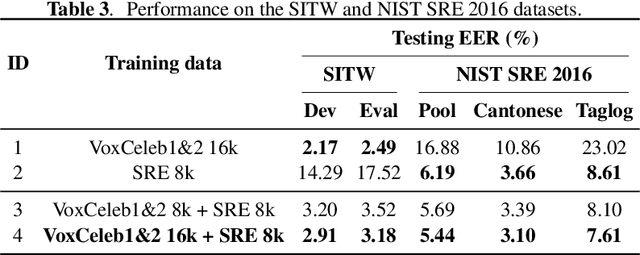
This paper proposes a unified deep speaker embedding framework for modeling speech data with different sampling rates. Considering the narrowband spectrogram as a sub-image of the wideband spectrogram, we tackle the joint modeling problem of the mixed-bandwidth data in an image classification manner. From this perspective, we elaborate several mixed-bandwidth joint training strategies under different training and test data scenarios. The proposed systems are able to flexibly handle the mixed-bandwidth speech data in a single speaker embedding model without any additional downsampling, upsampling, bandwidth extension, or padding operations. We conduct extensive experimental studies on the VoxCeleb1 dataset. Furthermore, the effectiveness of the proposed approach is validated by the SITW and NIST SRE 2016 datasets.