 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformer Inertial Poser: Attention-based Real-time Human Motion Reconstruction from Sparse IMUs
Paper and Code
Mar 29, 2022
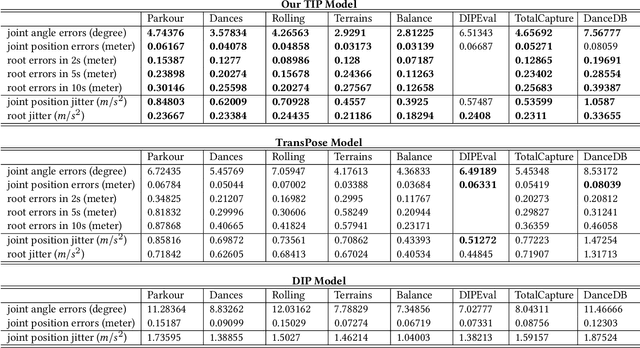
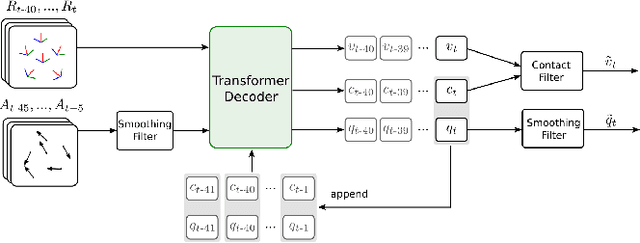
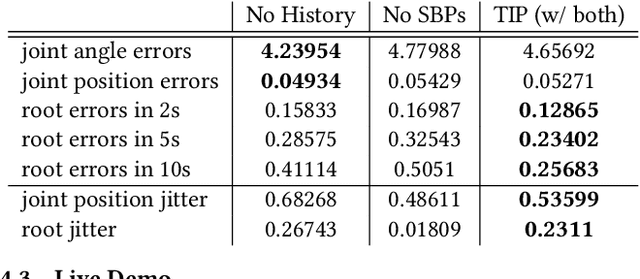
Real-time human motion reconstruction from a sparse set of wearable IMUs provides an non-intrusive and economic approach to motion capture. Without the ability to acquire absolute position information using IMUs, many prior works took data-driven approaches that utilize large human motion datasets to tackle the under-determined nature of the problem. Still, challenges such as temporal consistency, global translation estimation, and diverse coverage of motion or terrain types remain. Inspired by recent success of Transformer models in sequence modeling, we propose an attention-based deep learning method to reconstruct full-body motion from six IMU sensors in real-time. Together with a physics-based learning objective to predict "stationary body points", our method achieves new state-of-the-art results both quantitatively and qualitatively, while being simple to implement and smaller in size. We evaluate our method extensively on synthesized and real IMU data, and with real-time live demos.