 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDRFusion: Drift-Resilient Temporally Consistent Infrared-Visible Video Fusion
May 25, 2026Infrared and visible video fusion is essential for achieving comprehensive perception in dynamic scenes. However, maintaining temporal consistency remains a formidable challenge. Conventional methods relying on optical flow often suffer from geometric rigidity and ghosting artifacts. Moreover, standard diffusion-based fusion models typically operate in a frame-by-frame manner; when extended to autoregressive settings, they lack intrinsic temporal constraints and are prone to severe error accumulation and drifting, where minor artifacts amplify over time. To address these limitations, we propose a drift-resilient video fusion method that reformulates the task as history-conditioned motion generation. We introduce Stabilized History Guidance and Soft Temporal Anchoring to reframe temporal consistency as spectral filtering, implicitly aggregating motion dynamics without rigid alignment. Furthermore, our Decoupled Structure-Motion Adaptation strategy bridges pre-trained priors and structural constraints via two-stage training and latent refinement. Extensive experiments demonstrate that our method achieves state-of-the-art performance in both fusion quality and temporal stability.
CAPSUL: A Comprehensive Human Protein Benchmark for Subcellular Localization
Mar 19, 2026Subcellular localization is a crucial biological task for drug target identification and function annotation. Although it has been biologically realized that subcellular localization is closely associated with protein structure, no existing dataset offers comprehensive 3D structural information with detailed subcellular localization annotations, thus severely hindering the application of promising structure-based models on this task. To address this gap, we introduce a new benchmark called $\mathbf{CAPSUL}$, a $\mathbf{C}$omprehensive hum$\mathbf{A}$n $\mathbf{P}$rotein benchmark for $\mathbf{SU}$bcellular $\mathbf{L}$ocalization. It features a dataset that integrates diverse 3D structural representations with fine-grained subcellular localization annotations carefully curated by domain experts. We evaluate this benchmark using a variety of state-of-the-art sequence-based and structure-based models, showcasing the importance of involving structural features in this task. Furthermore, we explore reweighting and single-label classification strategies to facilitate future investigation on structure-based methods for this task. Lastly, we showcase the powerful interpretability of structure-based methods through a case study on the Golgi apparatus, where we discover a decisive localization pattern $α$-helix from attention mechanisms, demonstrating the potential for bridging the gap with intuitive biological interpretability and paving the way for data-driven discoveries in cell biology.
Application analysis of ai technology combined with spiral CT scanning in early lung cancer screening
Jan 26, 2024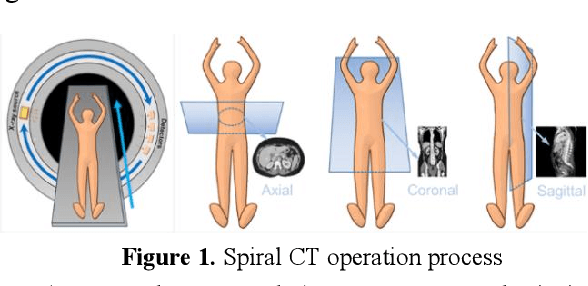
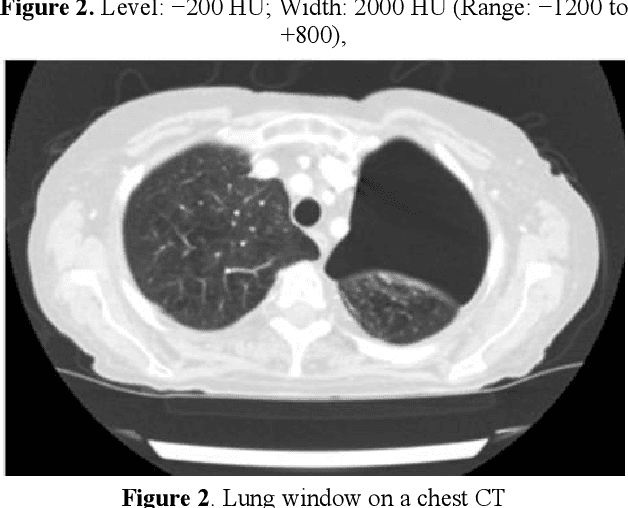
At present, the incidence and fatality rate of lung cancer in China rank first among all malignant tumors. Despite the continuous development and improvement of China's medical level, the overall 5-year survival rate of lung cancer patients is still lower than 20% and is staged. A number of studies have confirmed that early diagnosis and treatment of early stage lung cancer is of great significance to improve the prognosis of patients. In recent years, artificial intelligence technology has gradually begun to be applied in oncology. ai is used in cancer screening, clinical diagnosis, radiation therapy (image acquisition, at-risk organ segmentation, image calibration and delivery) and other aspects of rapid development. However, whether medical ai can be socialized depends on the public's attitude and acceptance to a certain extent. However, at present, there are few studies on the diagnosis of early lung cancer by AI technology combined with SCT scanning. In view of this, this study applied the combined method in early lung cancer screening, aiming to find a safe and efficient screening mode and provide a reference for clinical diagnosis and treatment.
Curriculum Recommendations Using Transformer Base Model with InfoNCE Loss And Language Switching Method
Jan 18, 2024The Curriculum Recommendations paradigm is dedicated to fostering learning equality within the ever-evolving realms of educational technology and curriculum development. In acknowledging the inherent obstacles posed by existing methodologies, such as content conflicts and disruptions from language translation, this paradigm aims to confront and overcome these challenges. Notably, it addresses content conflicts and disruptions introduced by language translation, hindrances that can impede the creation of an all-encompassing and personalized learning experience. The paradigm's objective is to cultivate an educational environment that not only embraces diversity but also customizes learning experiences to suit the distinct needs of each learner. To overcome these challenges, our approach builds upon notable contributions in curriculum development and personalized learning, introducing three key innovations. These include the integration of Transformer Base Model to enhance computational efficiency, the implementation of InfoNCE Loss for accurate content-topic matching, and the adoption of a language switching strategy to alleviate translation-related ambiguities. Together, these innovations aim to collectively tackle inherent challenges and contribute to forging a more equitable and effective learning journey for a diverse range of learners. Competitive cross-validation scores underscore the efficacy of sentence-transformers/LaBSE, achieving 0.66314, showcasing our methodology's effectiveness in diverse linguistic nuances for content alignment prediction. Index Terms-Curriculum Recommendation, Transformer model with InfoNCE Loss, Language Switching.
Automated Scoring of Clinical Patient Notes using Advanced NLP and Pseudo Labeling
Jan 18, 2024Clinical patient notes are critical for documenting patient interactions, diagnoses, and treatment plans in medical practice. Ensuring accurate evaluation of these notes is essential for medical education and certification. However, manual evaluation is complex and time-consuming, often resulting in variability and resource-intensive assessments. To tackle these challenges, this research introduces an approach leveraging state-of-the-art Natural Language Processing (NLP) techniques, specifically Masked Language Modeling (MLM) pretraining, and pseudo labeling. Our methodology enhances efficiency and effectiveness, significantly reducing training time without compromising performance. Experimental results showcase improved model performance, indicating a potential transformation in clinical note assessment.