 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkill Availability and Presentation Granularity in Large-Language-Model Agents: A Controlled SkillsBench Study
May 29, 2026Skill documents provide procedural knowledge to large-language-model agents at inference time. This article studies whether the presentation granularity of controlled skill knowledge changes downstream task success. The experiment uses a pinned SkillsBench version, a 30-task domain-balanced subset validated by official oracle runs, two reasoning-enabled model configurations, six skill conditions, and five trials per task-condition-model cell. Skill availability is the clearest empirical signal. Relative to no skill, skill conditions increase task-mean pass rate by 26.7 to 36.0 percentage points for GPT-5.5 and by 18.0 to 26.0 percentage points for DeepSeek V4-Flash. The final data contain 1,800 rows, with 900 rows for each model. The task is the inference unit. Five trials are aggregated within each task-condition-model cell before paired contrasts are estimated over 30 tasks. The primary presentation contrasts are smaller and uncertain. Low-abstraction guidance differs from high-abstraction guidance by +0.7 percentage points for GPT-5.5 and -6.7 percentage points for DeepSeek V4-Flash, with both 95% bootstrap confidence intervals crossing zero. Adding one worked example to medium-abstraction guidance differs from the no-example variant by +0.7 and +1.3 percentage points. Mean-reward robustness checks preserve the same substantive conclusion. In this controlled subset, skill availability is associated with higher success than no skill, while the tested presentation-granularity changes yield small, uncertain, and model-dependent effects.
Optimizing Contrail Detection: A Deep Learning Approach with EfficientNet-b4 Encoding
Apr 20, 2024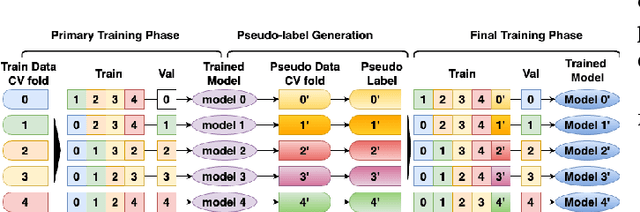
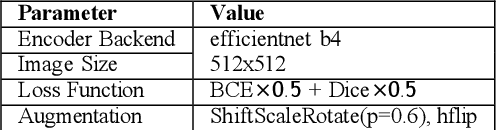
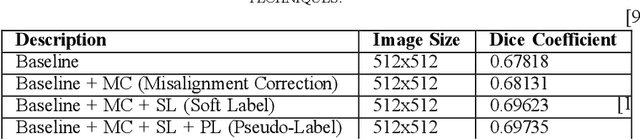
In the pursuit of environmental sustainability, the aviation industry faces the challenge of minimizing its ecological footprint. Among the key solutions is contrail avoidance, targeting the linear ice-crystal clouds produced by aircraft exhaust. These contrails exacerbate global warming by trapping atmospheric heat, necessitating precise segmentation and comprehensive analysis of contrail images to gauge their environmental impact. However, this segmentation task is complex due to the varying appearances of contrails under different atmospheric conditions and potential misalignment issues in predictive modeling. This paper presents an innovative deep-learning approach utilizing the efficient net-b4 encoder for feature extraction, seamlessly integrating misalignment correction, soft labeling, and pseudo-labeling techniques to enhance the accuracy and efficiency of contrail detection in satellite imagery. The proposed methodology aims to redefine contrail image analysis and contribute to the objectives of sustainable aviation by providing a robust framework for precise contrail detection and analysis in satellite imagery, thus aiding in the mitigation of aviation's environmental impact.
Emerging Synergies Between Large Language Models and Machine Learning in Ecommerce Recommendations
Mar 12, 2024



With the boom of e-commerce and web applications, recommender systems have become an important part of our daily lives, providing personalized recommendations based on the user's preferences. Although deep neural networks (DNNs) have made significant progress in improving recommendation systems by simulating the interaction between users and items and incorporating their textual information, these DNN-based approaches still have some limitations, such as the difficulty of effectively understanding users' interests and capturing textual information. It is not possible to generalize to different seen/unseen recommendation scenarios and reason about their predictions. At the same time, the emergence of large language models (LLMs), represented by ChatGPT and GPT-4, has revolutionized the fields of natural language processing (NLP) and artificial intelligence (AI) due to their superior capabilities in the basic tasks of language understanding and generation, and their impressive generalization and reasoning capabilities. As a result, recent research has sought to harness the power of LLM to improve recommendation systems. Given the rapid development of this research direction in the field of recommendation systems, there is an urgent need for a systematic review of existing LLM-driven recommendation systems for researchers and practitioners in related fields to gain insight into. More specifically, we first introduced a representative approach to learning user and item representations using LLM as a feature encoder. We then reviewed the latest advances in LLMs techniques for collaborative filtering enhanced recommendation systems from the three paradigms of pre-training, fine-tuning, and prompting. Finally, we had a comprehensive discussion on the future direction of this emerging field.
Comprehensive Implementation of TextCNN for Enhanced Collaboration between Natural Language Processing and System Recommendation
Mar 12, 2024

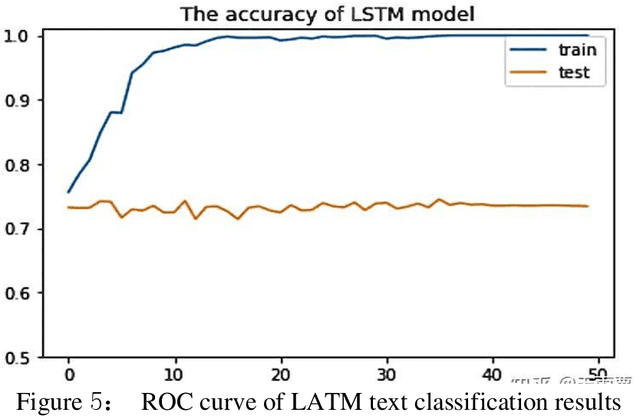
Natural Language Processing (NLP) is an important branch of artificial intelligence that studies how to enable computers to understand, process, and generate human language. Text classification is a fundamental task in NLP, which aims to classify text into different predefined categories. Text classification is the most basic and classic task in natural language processing, and most of the tasks in natural language processing can be regarded as classification tasks. In recent years, deep learning has achieved great success in many research fields, and today, it has also become a standard technology in the field of NLP, which is widely integrated into text classification tasks. Unlike numbers and images, text processing emphasizes fine-grained processing ability. Traditional text classification methods generally require preprocessing the input model's text data. Additionally, they also need to obtain good sample features through manual annotation and then use classical machine learning algorithms for classification. Therefore, this paper analyzes the application status of deep learning in the three core tasks of NLP (including text representation, word order modeling, and knowledge representation). This content explores the improvement and synergy achieved through natural language processing in the context of text classification, while also taking into account the challenges posed by adversarial techniques in text generation, text classification, and semantic parsing. An empirical study on text classification tasks demonstrates the effectiveness of interactive integration training, particularly in conjunction with TextCNN, highlighting the significance of these advancements in text classification augmentation and enhancement.
Curriculum Recommendations Using Transformer Base Model with InfoNCE Loss And Language Switching Method
Jan 18, 2024The Curriculum Recommendations paradigm is dedicated to fostering learning equality within the ever-evolving realms of educational technology and curriculum development. In acknowledging the inherent obstacles posed by existing methodologies, such as content conflicts and disruptions from language translation, this paradigm aims to confront and overcome these challenges. Notably, it addresses content conflicts and disruptions introduced by language translation, hindrances that can impede the creation of an all-encompassing and personalized learning experience. The paradigm's objective is to cultivate an educational environment that not only embraces diversity but also customizes learning experiences to suit the distinct needs of each learner. To overcome these challenges, our approach builds upon notable contributions in curriculum development and personalized learning, introducing three key innovations. These include the integration of Transformer Base Model to enhance computational efficiency, the implementation of InfoNCE Loss for accurate content-topic matching, and the adoption of a language switching strategy to alleviate translation-related ambiguities. Together, these innovations aim to collectively tackle inherent challenges and contribute to forging a more equitable and effective learning journey for a diverse range of learners. Competitive cross-validation scores underscore the efficacy of sentence-transformers/LaBSE, achieving 0.66314, showcasing our methodology's effectiveness in diverse linguistic nuances for content alignment prediction. Index Terms-Curriculum Recommendation, Transformer model with InfoNCE Loss, Language Switching.
Digital Twin of a Network and Operating Environment Using Augmented Reality
Mar 23, 2023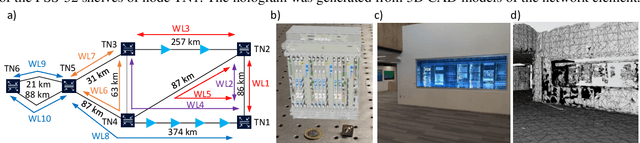


We demonstrate the digital twin of a network, network elements, and operating environment using machine learning. We achieve network card failure localization and remote collaboration over 86 km of fiber using augmented reality.