 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSidelink Positioning: Standardization Advancements, Challenges and Opportunities
Dec 31, 2025With the integration of cellular networks in vertical industries that demand precise location information, such as vehicle-to-everything (V2X), public safety, and Industrial Internet of Things (IIoT), positioning has become an imperative component for future wireless networks. By exploiting a wider spectrum, multiple antennas and flexible architectures, cellular positioning achieves ever-increasing positioning accuracy. Still, it faces fundamental performance degradation when the distance between user equipment (UE) and the base station (BS) is large or in non-line-of-sight (NLoS) scenarios. To this end, the 3rd generation partnership project (3GPP) Rel-18 proposes to standardize sidelink (SL) positioning, which provides unique opportunities to extend the positioning coverage via direct positioning signaling between UEs. Despite the standardization advancements, the capability of SL positioning is controversial, especially how much spectrum is required to achieve the positioning accuracy defined in 3GPP. To this end, this article summarizes the latest standardization advancements of 3GPP on SL positioning comprehensively, covering a) network architecture; b) positioning types; and c) performance requirements. The capability of SL positioning using various positioning methods under different imperfect factors is evaluated and discussed in-depth. Finally, according to the evolution of SL in 3GPP Rel-19, we discuss the possible research directions and challenges of SL positioning.
Maximizing User Experience with LLMOps-Driven Personalized Recommendation Systems
Apr 01, 2024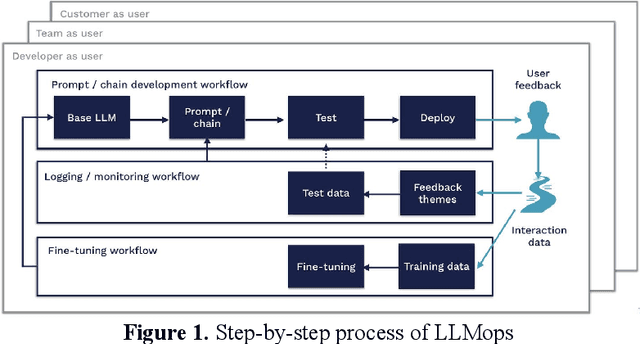
The integration of LLMOps into personalized recommendation systems marks a significant advancement in managing LLM-driven applications. This innovation presents both opportunities and challenges for enterprises, requiring specialized teams to navigate the complexity of engineering technology while prioritizing data security and model interpretability. By leveraging LLMOps, enterprises can enhance the efficiency and reliability of large-scale machine learning models, driving personalized recommendations aligned with user preferences. Despite ethical considerations, LLMOps is poised for widespread adoption, promising more efficient and secure machine learning services that elevate user experience and shape the future of personalized recommendation systems.
Research on the Application of Deep Learning-based BERT Model in Sentiment Analysis
Mar 13, 2024



This paper explores the application of deep learning techniques, particularly focusing on BERT models, in sentiment analysis. It begins by introducing the fundamental concept of sentiment analysis and how deep learning methods are utilized in this domain. Subsequently, it delves into the architecture and characteristics of BERT models. Through detailed explanation, it elucidates the application effects and optimization strategies of BERT models in sentiment analysis, supported by experimental validation. The experimental findings indicate that BERT models exhibit robust performance in sentiment analysis tasks, with notable enhancements post fine-tuning. Lastly, the paper concludes by summarizing the potential applications of BERT models in sentiment analysis and suggests directions for future research and practical implementations.
Comprehensive Implementation of TextCNN for Enhanced Collaboration between Natural Language Processing and System Recommendation
Mar 12, 2024

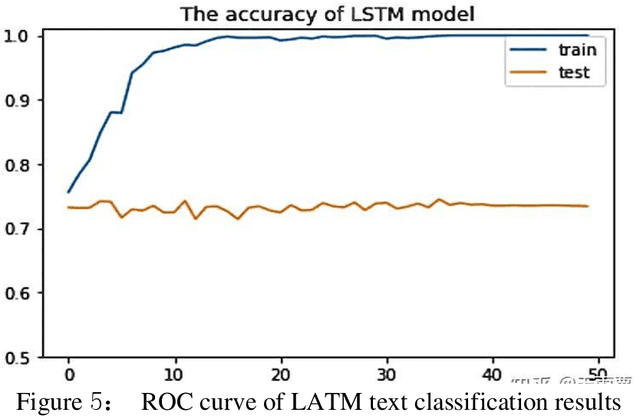
Natural Language Processing (NLP) is an important branch of artificial intelligence that studies how to enable computers to understand, process, and generate human language. Text classification is a fundamental task in NLP, which aims to classify text into different predefined categories. Text classification is the most basic and classic task in natural language processing, and most of the tasks in natural language processing can be regarded as classification tasks. In recent years, deep learning has achieved great success in many research fields, and today, it has also become a standard technology in the field of NLP, which is widely integrated into text classification tasks. Unlike numbers and images, text processing emphasizes fine-grained processing ability. Traditional text classification methods generally require preprocessing the input model's text data. Additionally, they also need to obtain good sample features through manual annotation and then use classical machine learning algorithms for classification. Therefore, this paper analyzes the application status of deep learning in the three core tasks of NLP (including text representation, word order modeling, and knowledge representation). This content explores the improvement and synergy achieved through natural language processing in the context of text classification, while also taking into account the challenges posed by adversarial techniques in text generation, text classification, and semantic parsing. An empirical study on text classification tasks demonstrates the effectiveness of interactive integration training, particularly in conjunction with TextCNN, highlighting the significance of these advancements in text classification augmentation and enhancement.