 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffects of Generative AI Errors on User Reliance Across Task Difficulty
Apr 05, 2026The capabilities of artificial intelligence (AI) lie along a jagged frontier, where AI systems surprisingly fail on tasks that humans find easy and succeed on tasks that humans find hard. To investigate user reactions to this phenomenon, we developed an incentive-compatible experimental methodology based on diagram generation tasks, in which we induce errors in generative AI output and test effects on user reliance. We demonstrate the interface in a preregistered 3x2 experiment (N = 577) with error rates of 10%, 30%, or 50% on easier or harder diagram generation tasks. We confirmed that observing more errors reduces use, but we unexpectedly found that easy-task errors did not significantly reduce use more than hard-task errors, suggesting that people are not averse to jaggedness in this experimental setting. We encourage future work that varies task difficulty at the same time as other features of AI errors, such as whether the jagged error patterns are easily learned.
ShapeCraft: Body-Aware and Semantics-Aware 3D Object Design
Dec 05, 2024



For designing a wide range of everyday objects, the design process should be aware of both the human body and the underlying semantics of the design specification. However, these two objectives present significant challenges to the current AI-based designing tools. In this work, we present a method to synthesize body-aware 3D objects from a base mesh given an input body geometry and either text or image as guidance. The generated objects can be simulated on virtual characters, or fabricated for real-world use. We propose to use a mesh deformation procedure that optimizes for both semantic alignment as well as contact and penetration losses. Using our method, users can generate both virtual or real-world objects from text, image, or sketch, without the need for manual artist intervention. We present both qualitative and quantitative results on various object categories, demonstrating the effectiveness of our approach.
MARPLE: A Benchmark for Long-Horizon Inference
Oct 02, 2024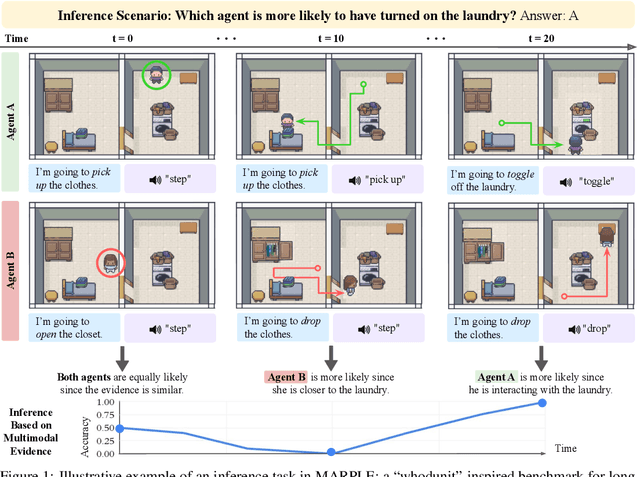

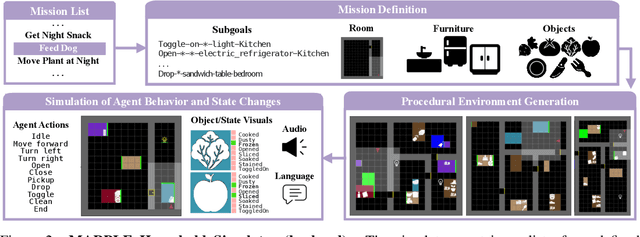

Reconstructing past events requires reasoning across long time horizons. To figure out what happened, we need to use our prior knowledge about the world and human behavior and draw inferences from various sources of evidence including visual, language, and auditory cues. We introduce MARPLE, a benchmark for evaluating long-horizon inference capabilities using multi-modal evidence. Our benchmark features agents interacting with simulated households, supporting vision, language, and auditory stimuli, as well as procedurally generated environments and agent behaviors. Inspired by classic ``whodunit'' stories, we ask AI models and human participants to infer which agent caused a change in the environment based on a step-by-step replay of what actually happened. The goal is to correctly identify the culprit as early as possible. Our findings show that human participants outperform both traditional Monte Carlo simulation methods and an LLM baseline (GPT-4) on this task. Compared to humans, traditional inference models are less robust and performant, while GPT-4 has difficulty comprehending environmental changes. We analyze what factors influence inference performance and ablate different modes of evidence, finding that all modes are valuable for performance. Overall, our experiments demonstrate that the long-horizon, multimodal inference tasks in our benchmark present a challenge to current models.