 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEscaping the Context Bottleneck: Active Context Curation for LLM Agents via Reinforcement Learning
Apr 13, 2026Large Language Models (LLMs) struggle with long-horizon tasks due to the "context bottleneck" and the "lost-in-the-middle" phenomenon, where accumulated noise from verbose environments degrades reasoning over multi-turn interactions. To address this issue, we introduce a symbiotic framework that decouples context management from task execution. Our architecture pairs a lightweight, specialized policy model, ContextCurator, with a powerful frozen foundation model, TaskExecutor. Trained via reinforcement learning, ContextCurator actively reduces information entropy in the working memory. It aggressively prunes environmental noise while preserving reasoning anchors, that is, sparse data points that are critical for future deductions. On WebArena, our framework improves the success rate of Gemini-3.0-flash from 36.4% to 41.2% while reducing token consumption by 8.8% (from 47.4K to 43.3K). On DeepSearch, it achieves a 57.1% success rate, compared with 53.9%, while reducing token consumption by a factor of 8. Remarkably, a 7B ContextCurator matches the context management performance of GPT-4o, providing a scalable and computationally efficient paradigm for autonomous long-horizon agents.
COINBench: Moving Beyond Individual Perspectives to Collective Intent Understanding
Mar 22, 2026Understanding human intent is a high-level cognitive challenge for Large Language Models (LLMs), requiring sophisticated reasoning over noisy, conflicting, and non-linear discourse. While LLMs excel at following individual instructions, their ability to distill Collective Intent - the process of extracting consensus, resolving contradictions, and inferring latent trends from multi-source public discussions - remains largely unexplored. To bridge this gap, we introduce COIN-BENCH, a dynamic, real-world, live-updating benchmark specifically designed to evaluate LLMs on collective intent understanding within the consumer domain. Unlike traditional benchmarks that focus on transactional outcomes, COIN-BENCH operationalizes intent as a hierarchical cognitive structure, ranging from explicit scenarios to deep causal reasoning. We implement a robust evaluation pipeline that combines a rule-based method with an LLM-as-the-Judge approach. This framework incorporates COIN-TREE for hierarchical cognitive structuring and retrieval-augmented verification (COIN-RAG) to ensure expert-level precision in analyzing raw, collective human discussions. An extensive evaluation of 20 state-of-the-art LLMs across four dimensions - depth, breadth, informativeness, and correctness - reveals that while current models can handle surface-level aggregation, they still struggle with the analytical depth required for complex intent synthesis. COIN-BENCH establishes a new standard for advancing LLMs from passive instruction followers to expert-level analytical agents capable of deciphering the collective voice of the real world. See our project page on COIN-BENCH.
Fine-tuning Small Language Models as Efficient Enterprise Search Relevance Labelers
Jan 06, 2026In enterprise search, building high-quality datasets at scale remains a central challenge due to the difficulty of acquiring labeled data. To resolve this challenge, we propose an efficient approach to fine-tune small language models (SLMs) for accurate relevance labeling, enabling high-throughput, domain-specific labeling comparable or even better in quality to that of state-of-the-art large language models (LLMs). To overcome the lack of high-quality and accessible datasets in the enterprise domain, our method leverages on synthetic data generation. Specifically, we employ an LLM to synthesize realistic enterprise queries from a seed document, apply BM25 to retrieve hard negatives, and use a teacher LLM to assign relevance scores. The resulting dataset is then distilled into an SLM, producing a compact relevance labeler. We evaluate our approach on a high-quality benchmark consisting of 923 enterprise query-document pairs annotated by trained human annotators, and show that the distilled SLM achieves agreement with human judgments on par with or better than the teacher LLM. Furthermore, our fine-tuned labeler substantially improves throughput, achieving 17 times increase while also being 19 times more cost-effective. This approach enables scalable and cost-effective relevance labeling for enterprise-scale retrieval applications, supporting rapid offline evaluation and iteration in real-world settings.
Learning ECG Representations via Poly-Window Contrastive Learning
Aug 21, 2025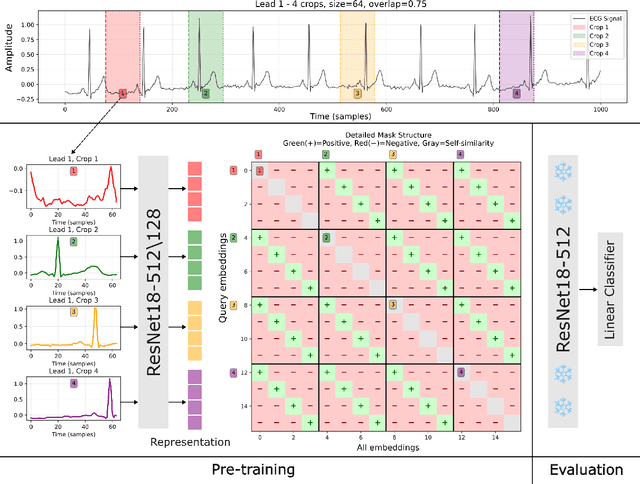
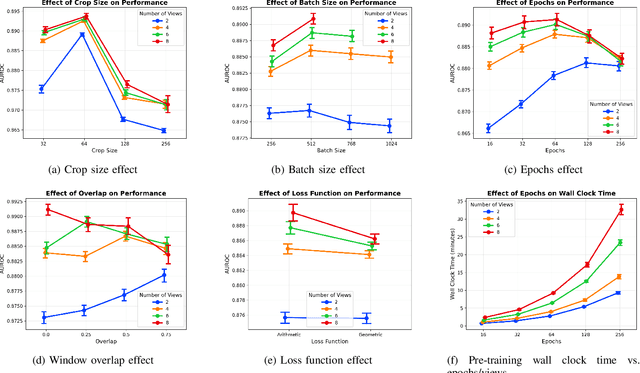


Electrocardiogram (ECG) analysis is foundational for cardiovascular disease diagnosis, yet the performance of deep learning models is often constrained by limited access to annotated data. Self-supervised contrastive learning has emerged as a powerful approach for learning robust ECG representations from unlabeled signals. However, most existing methods generate only pairwise augmented views and fail to leverage the rich temporal structure of ECG recordings. In this work, we present a poly-window contrastive learning framework. We extract multiple temporal windows from each ECG instance to construct positive pairs and maximize their agreement via statistics. Inspired by the principle of slow feature analysis, our approach explicitly encourages the model to learn temporally invariant and physiologically meaningful features that persist across time. We validate our approach through extensive experiments and ablation studies on the PTB-XL dataset. Our results demonstrate that poly-window contrastive learning consistently outperforms conventional two-view methods in multi-label superclass classification, achieving higher AUROC (0.891 vs. 0.888) and F1 scores (0.680 vs. 0.679) while requiring up to four times fewer pre-training epochs (32 vs. 128) and 14.8% in total wall clock pre-training time reduction. Despite processing multiple windows per sample, we achieve a significant reduction in the number of training epochs and total computation time, making our method practical for training foundational models. Through extensive ablations, we identify optimal design choices and demonstrate robustness across various hyperparameters. These findings establish poly-window contrastive learning as a highly efficient and scalable paradigm for automated ECG analysis and provide a promising general framework for self-supervised representation learning in biomedical time-series data.
MARPLE: A Benchmark for Long-Horizon Inference
Oct 02, 2024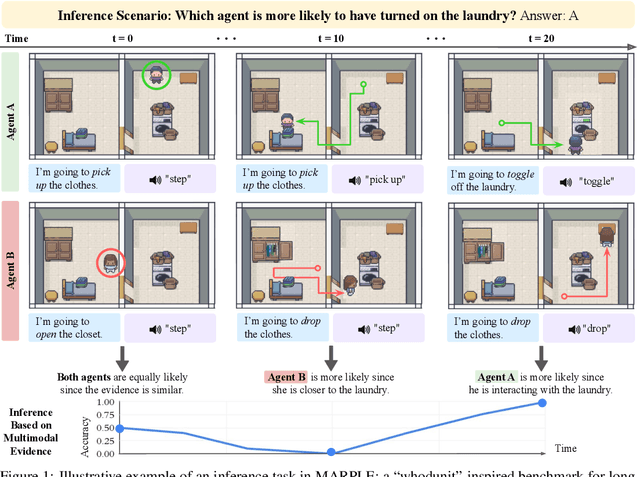


Reconstructing past events requires reasoning across long time horizons. To figure out what happened, we need to use our prior knowledge about the world and human behavior and draw inferences from various sources of evidence including visual, language, and auditory cues. We introduce MARPLE, a benchmark for evaluating long-horizon inference capabilities using multi-modal evidence. Our benchmark features agents interacting with simulated households, supporting vision, language, and auditory stimuli, as well as procedurally generated environments and agent behaviors. Inspired by classic ``whodunit'' stories, we ask AI models and human participants to infer which agent caused a change in the environment based on a step-by-step replay of what actually happened. The goal is to correctly identify the culprit as early as possible. Our findings show that human participants outperform both traditional Monte Carlo simulation methods and an LLM baseline (GPT-4) on this task. Compared to humans, traditional inference models are less robust and performant, while GPT-4 has difficulty comprehending environmental changes. We analyze what factors influence inference performance and ablate different modes of evidence, finding that all modes are valuable for performance. Overall, our experiments demonstrate that the long-horizon, multimodal inference tasks in our benchmark present a challenge to current models.
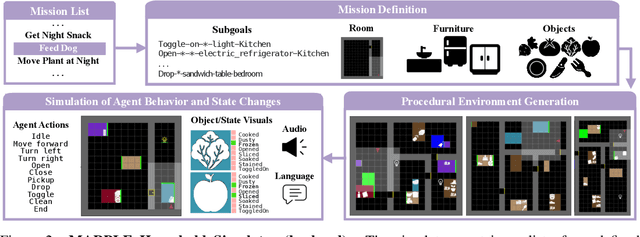
Mini-BEHAVIOR: A Procedurally Generated Benchmark for Long-horizon Decision-Making in Embodied AI
Oct 03, 2023



We present Mini-BEHAVIOR, a novel benchmark for embodied AI that challenges agents to use reasoning and decision-making skills to solve complex activities that resemble everyday human challenges. The Mini-BEHAVIOR environment is a fast, realistic Gridworld environment that offers the benefits of rapid prototyping and ease of use while preserving a symbolic level of physical realism and complexity found in complex embodied AI benchmarks. We introduce key features such as procedural generation, to enable the creation of countless task variations and support open-ended learning. Mini-BEHAVIOR provides implementations of various household tasks from the original BEHAVIOR benchmark, along with starter code for data collection and reinforcement learning agent training. In essence, Mini-BEHAVIOR offers a fast, open-ended benchmark for evaluating decision-making and planning solutions in embodied AI. It serves as a user-friendly entry point for research and facilitates the evaluation and development of solutions, simplifying their assessment and development while advancing the field of embodied AI. Code is publicly available at https://github.com/StanfordVL/mini_behavior.