 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTWIST: Teleoperated Whole-Body Imitation System
May 05, 2025Teleoperating humanoid robots in a whole-body manner marks a fundamental step toward developing general-purpose robotic intelligence, with human motion providing an ideal interface for controlling all degrees of freedom. Yet, most current humanoid teleoperation systems fall short of enabling coordinated whole-body behavior, typically limiting themselves to isolated locomotion or manipulation tasks. We present the Teleoperated Whole-Body Imitation System (TWIST), a system for humanoid teleoperation through whole-body motion imitation. We first generate reference motion clips by retargeting human motion capture data to the humanoid robot. We then develop a robust, adaptive, and responsive whole-body controller using a combination of reinforcement learning and behavior cloning (RL+BC). Through systematic analysis, we demonstrate how incorporating privileged future motion frames and real-world motion capture (MoCap) data improves tracking accuracy. TWIST enables real-world humanoid robots to achieve unprecedented, versatile, and coordinated whole-body motor skills--spanning whole-body manipulation, legged manipulation, locomotion, and expressive movement--using a single unified neural network controller. Our project website: https://humanoid-teleop.github.io
Control with adaptive Q-learning
Nov 03, 2020
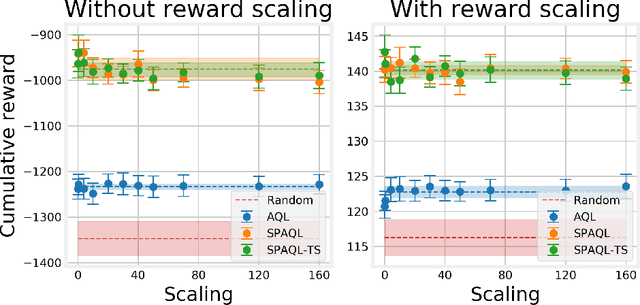

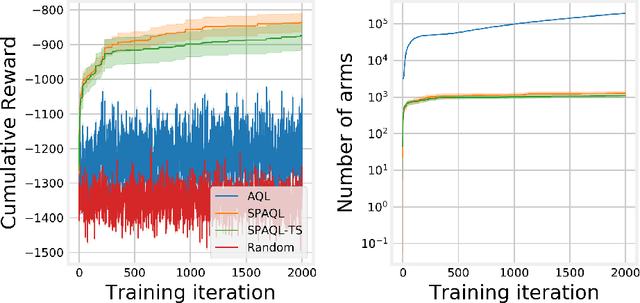
This paper evaluates adaptive Q-learning (AQL) and single-partition adaptive Q-learning (SPAQL), two algorithms for efficient model-free episodic reinforcement learning (RL), in two classical control problems (Pendulum and Cartpole). AQL adaptively partitions the state-action space of a Markov decision process (MDP), while learning the control policy, i. e., the mapping from states to actions. The main difference between AQL and SPAQL is that the latter learns time-invariant policies, where the mapping from states to actions does not depend explicitly on the time step. This paper also proposes the SPAQL with terminal state (SPAQL-TS), an improved version of SPAQL tailored for the design of regulators for control problems. The time-invariant policies are shown to result in a better performance than the time-variant ones in both problems studied. These algorithms are particularly fitted to RL problems where the action space is finite, as is the case with the Cartpole problem. SPAQL-TS solves the OpenAI Gym Cartpole problem, while also displaying a higher sample efficiency than trust region policy optimization (TRPO), a standard RL algorithm for solving control tasks. Moreover, the policies learned by SPAQL are interpretable, while TRPO policies are typically encoded as neural networks, and therefore hard to interpret. Yielding interpretable policies while being sample-efficient are the major advantages of SPAQL.
Single-partition adaptive Q-learning
Jul 14, 2020
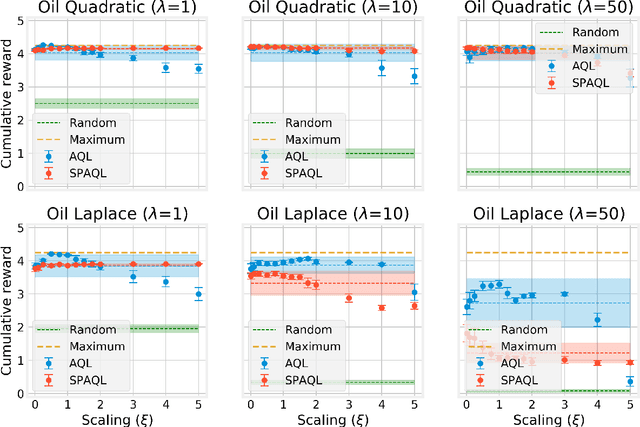
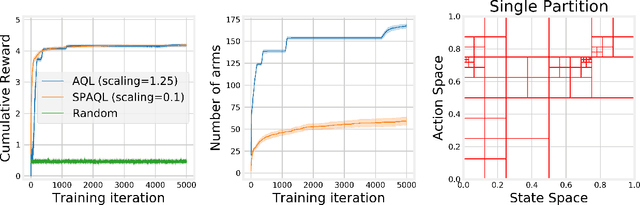
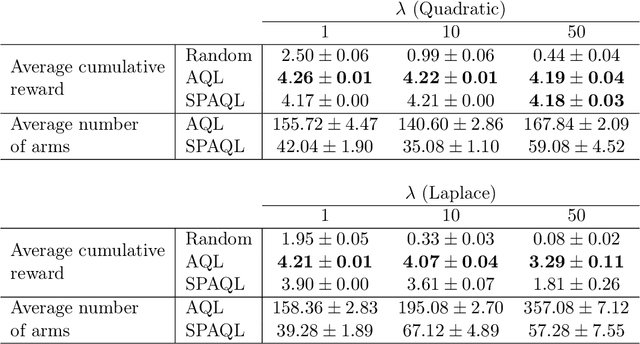
This paper introduces single-partition adaptive Q-learning (SPAQL), an algorithm for model-free episodic reinforcement learning (RL), which adaptively partitions the state-action space of a Markov decision process (MDP), while simultaneously learning a time-invariant policy (i. e., the mapping from states to actions does not depend explicitly on the episode time step) for maximizing the cumulative reward. The trade-off between exploration and exploitation is handled by using a mixture of upper confidence bounds (UCB) and Boltzmann exploration during training, with a temperature parameter that is automatically tuned as training progresses. The algorithm is an improvement over adaptive Q-learning (AQL). It converges faster to the optimal solution, while also using fewer arms. Tests on episodes with a large number of time steps show that SPAQL has no problems scaling, unlike AQL. Based on this empirical evidence, we claim that SPAQL may have a higher sample efficiency than AQL, thus being a relevant contribution to the field of efficient model-free RL methods.