 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse Training Theory for Scalable and Efficient Agents
Mar 02, 2021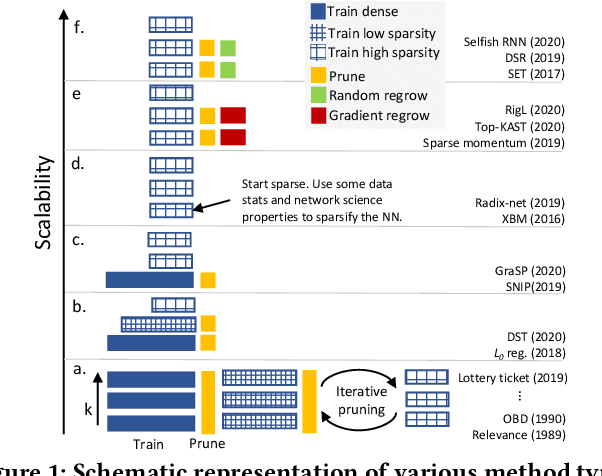
A fundamental task for artificial intelligence is learning. Deep Neural Networks have proven to cope perfectly with all learning paradigms, i.e. supervised, unsupervised, and reinforcement learning. Nevertheless, traditional deep learning approaches make use of cloud computing facilities and do not scale well to autonomous agents with low computational resources. Even in the cloud, they suffer from computational and memory limitations, and they cannot be used to model adequately large physical worlds for agents which assume networks with billions of neurons. These issues are addressed in the last few years by the emerging topic of sparse training, which trains sparse networks from scratch. This paper discusses sparse training state-of-the-art, its challenges and limitations while introducing a couple of new theoretical research directions which has the potential of alleviating sparse training limitations to push deep learning scalability well beyond its current boundaries. Nevertheless, the theoretical advancements impact in complex multi-agents settings is discussed from a real-world perspective, using the smart grid case study.
Truly Sparse Neural Networks at Scale
Feb 02, 2021

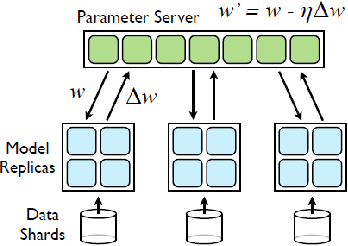

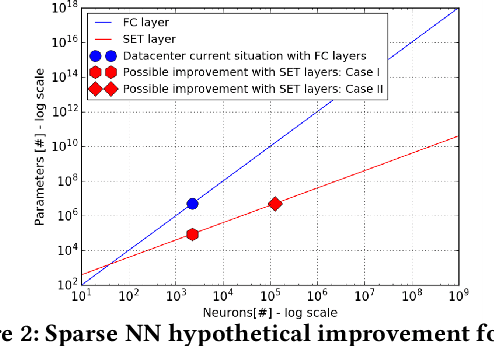
Recently, sparse training methods have started to be established as a de facto approach for training and inference efficiency in artificial neural networks. Yet, this efficiency is just in theory. In practice, everyone uses a binary mask to simulate sparsity since the typical deep learning software and hardware are optimized for dense matrix operations. In this paper, we take an orthogonal approach, and we show that we can train truly sparse neural networks to harvest their full potential. To achieve this goal, we introduce three novel contributions, specially designed for sparse neural networks: (1) a parallel training algorithm and its corresponding sparse implementation from scratch, (2) an activation function with non-trainable parameters to favour the gradient flow, and (3) a hidden neurons importance metric to eliminate redundancies. All in one, we are able to break the record and to train the largest neural network ever trained in terms of representational power -- reaching the bat brain size. The results show that our approach has state-of-the-art performance while opening the path for an environmentally friendly artificial intelligence era.