 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Training of Artificial Neural Networks with Adaptive Sparse Connectivity inspired by Network Science
Paper and Code
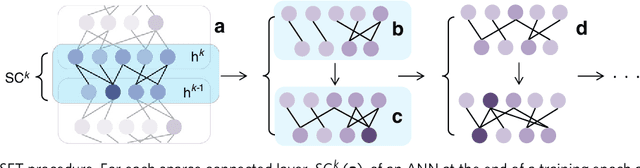
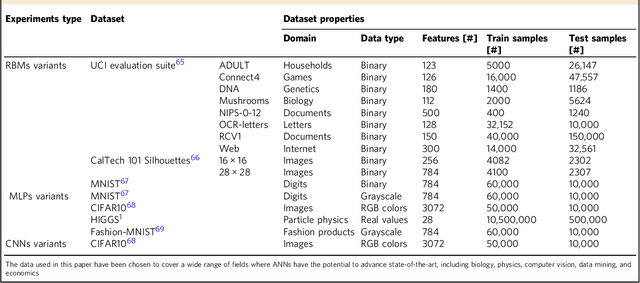
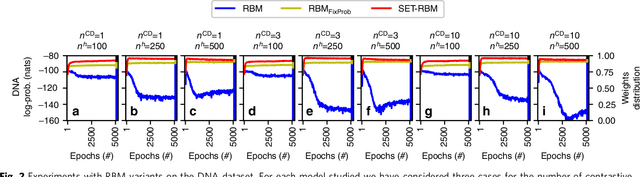
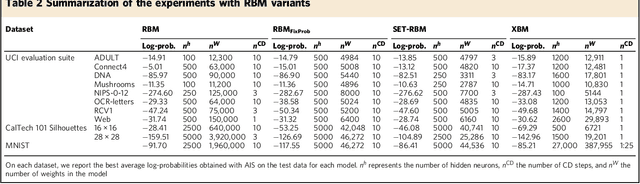
Through the success of deep learning in various domains, artificial neural networks are currently among the most used artificial intelligence methods. Taking inspiration from the network properties of biological neural networks (e.g. sparsity, scale-freeness), we argue that (contrary to general practice) artificial neural networks, too, should not have fully-connected layers. Here we propose sparse evolutionary training of artificial neural networks, an algorithm which evolves an initial sparse topology (Erd\H{o}s-R\'enyi random graph) of two consecutive layers of neurons into a scale-free topology, during learning. Our method replaces artificial neural networks fully-connected layers with sparse ones before training, reducing quadratically the number of parameters, with no decrease in accuracy. We demonstrate our claims on restricted Boltzmann machines, multi-layer perceptrons, and convolutional neural networks for unsupervised and supervised learning on 15 datasets. Our approach has the potential to enable artificial neural networks to scale up beyond what is currently possible.