 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Unified Convergence Analysis for Semi-Decentralized Learning: Sampled-to-Sampled vs. Sampled-to-All Communication
Nov 17, 2025In semi-decentralized federated learning, devices primarily rely on device-to-device communication but occasionally interact with a central server. Periodically, a sampled subset of devices uploads their local models to the server, which computes an aggregate model. The server can then either (i) share this aggregate model only with the sampled clients (sampled-to-sampled, S2S) or (ii) broadcast it to all clients (sampled-to-all, S2A). Despite their practical significance, a rigorous theoretical and empirical comparison of these two strategies remains absent. We address this gap by analyzing S2S and S2A within a unified convergence framework that accounts for key system parameters: sampling rate, server aggregation frequency, and network connectivity. Our results, both analytical and experimental, reveal distinct regimes where one strategy outperforms the other, depending primarily on the degree of data heterogeneity across devices. These insights lead to concrete design guidelines for practical semi-decentralized FL deployments.
Green Federated Learning via Carbon-Aware Client and Time Slot Scheduling
Sep 10, 2025Training large-scale machine learning models incurs substantial carbon emissions. Federated Learning (FL), by distributing computation across geographically dispersed clients, offers a natural framework to leverage regional and temporal variations in Carbon Intensity (CI). This paper investigates how to reduce emissions in FL through carbon-aware client selection and training scheduling. We first quantify the emission savings of a carbon-aware scheduling policy that leverages slack time -- permitting a modest extension of the training duration so that clients can defer local training rounds to lower-carbon periods. We then examine the performance trade-offs of such scheduling which stem from statistical heterogeneity among clients, selection bias in participation, and temporal correlation in model updates. To leverage these trade-offs, we construct a carbon-aware scheduler that integrates slack time, $\alpha$-fair carbon allocation, and a global fine-tuning phase. Experiments on real-world CI data show that our scheduler outperforms slack-agnostic baselines, achieving higher model accuracy across a wide range of carbon budgets, with especially strong gains under tight carbon constraints.
Whisper D-SGD: Correlated Noise Across Agents for Differentially Private Decentralized Learning
Jan 24, 2025


Decentralized learning enables distributed agents to train a shared machine learning model through local computation and peer-to-peer communication. Although each agent retains its dataset locally, the communication of local models can still expose private information to adversaries. To mitigate these threats, local differential privacy (LDP) injects independent noise per agent, but it suffers a larger utility gap than central differential privacy (CDP). We introduce Whisper D-SGD, a novel covariance-based approach that generates correlated privacy noise across agents, unifying several state-of-the-art methods as special cases. By leveraging network topology and mixing weights, Whisper D-SGD optimizes the noise covariance to achieve network-wide noise cancellation. Experimental results show that Whisper D-SGD cancels more noise than existing pairwise-correlation schemes, substantially narrowing the CDP-LDP gap and improving model performance under the same privacy guarantees.
FedStale: leveraging stale client updates in federated learning
May 07, 2024

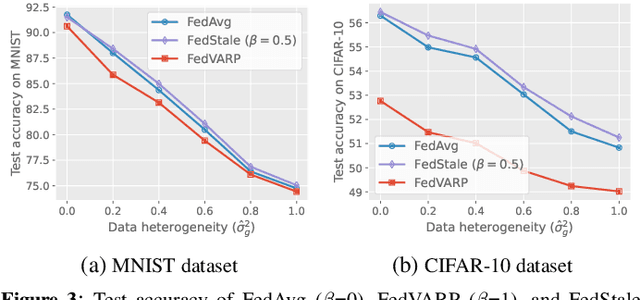
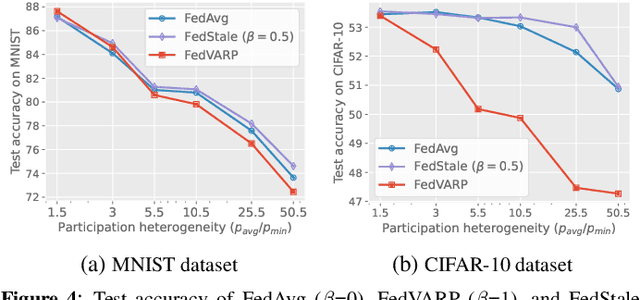
Federated learning algorithms, such as FedAvg, are negatively affected by data heterogeneity and partial client participation. To mitigate the latter problem, global variance reduction methods, like FedVARP, leverage stale model updates for non-participating clients. These methods are effective under homogeneous client participation. Yet, this paper shows that, when some clients participate much less than others, aggregating updates with different levels of staleness can detrimentally affect the training process. Motivated by this observation, we introduce FedStale, a novel algorithm that updates the global model in each round through a convex combination of "fresh" updates from participating clients and "stale" updates from non-participating ones. By adjusting the weight in the convex combination, FedStale interpolates between FedAvg, which only uses fresh updates, and FedVARP, which treats fresh and stale updates equally. Our analysis of FedStale convergence yields the following novel findings: i) it integrates and extends previous FedAvg and FedVARP analyses to heterogeneous client participation; ii) it underscores how the least participating client influences convergence error; iii) it provides practical guidelines to best exploit stale updates, showing that their usefulness diminishes as data heterogeneity decreases and participation heterogeneity increases. Extensive experiments featuring diverse levels of client data and participation heterogeneity not only confirm these findings but also show that FedStale outperforms both FedAvg and FedVARP in many settings.
Federated Learning for Cooperative Inference Systems: The Case of Early Exit Networks
May 07, 2024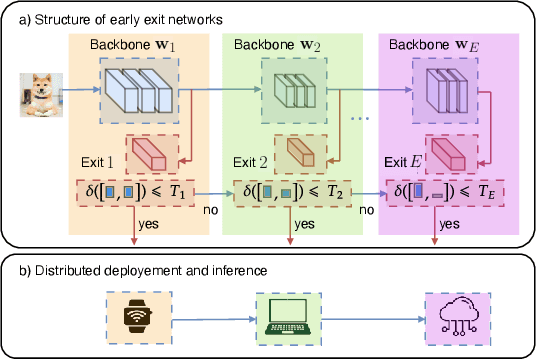
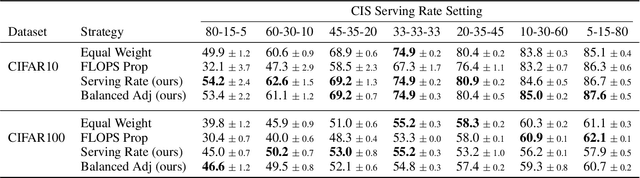
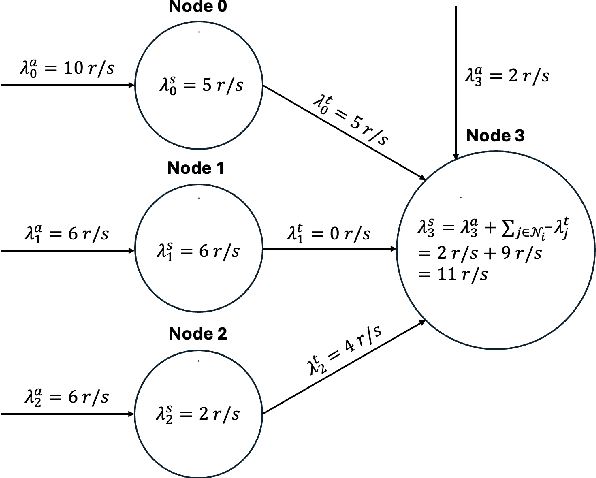
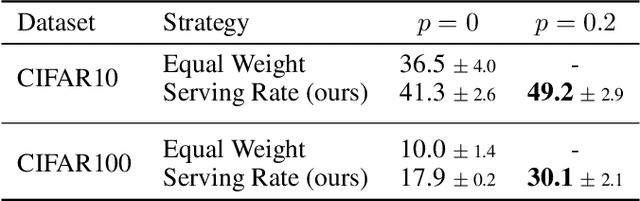
As Internet of Things (IoT) technology advances, end devices like sensors and smartphones are progressively equipped with AI models tailored to their local memory and computational constraints. Local inference reduces communication costs and latency; however, these smaller models typically underperform compared to more sophisticated models deployed on edge servers or in the cloud. Cooperative Inference Systems (CISs) address this performance trade-off by enabling smaller devices to offload part of their inference tasks to more capable devices. These systems often deploy hierarchical models that share numerous parameters, exemplified by Deep Neural Networks (DNNs) that utilize strategies like early exits or ordered dropout. In such instances, Federated Learning (FL) may be employed to jointly train the models within a CIS. Yet, traditional training methods have overlooked the operational dynamics of CISs during inference, particularly the potential high heterogeneity in serving rates across clients. To address this gap, we propose a novel FL approach designed explicitly for use in CISs that accounts for these variations in serving rates. Our framework not only offers rigorous theoretical guarantees, but also surpasses state-of-the-art (SOTA) training algorithms for CISs, especially in scenarios where inference request rates or data availability are uneven among clients.
Federated Learning under Heterogeneous and Correlated Client Availability
Jan 11, 2023



The enormous amount of data produced by mobile and IoT devices has motivated the development of federated learning (FL), a framework allowing such devices (or clients) to collaboratively train machine learning models without sharing their local data. FL algorithms (like FedAvg) iteratively aggregate model updates computed by clients on their own datasets. Clients may exhibit different levels of participation, often correlated over time and with other clients. This paper presents the first convergence analysis for a FedAvg-like FL algorithm under heterogeneous and correlated client availability. Our analysis highlights how correlation adversely affects the algorithm's convergence rate and how the aggregation strategy can alleviate this effect at the cost of steering training toward a biased model. Guided by the theoretical analysis, we propose CA-Fed, a new FL algorithm that tries to balance the conflicting goals of maximizing convergence speed and minimizing model bias. To this purpose, CA-Fed dynamically adapts the weight given to each client and may ignore clients with low availability and large correlation. Our experimental results show that CA-Fed achieves higher time-average accuracy and a lower standard deviation than state-of-the-art AdaFed and F3AST, both on synthetic and real datasets.