 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient and Optimal No-Regret Caching under Partial Observation
Mar 04, 2025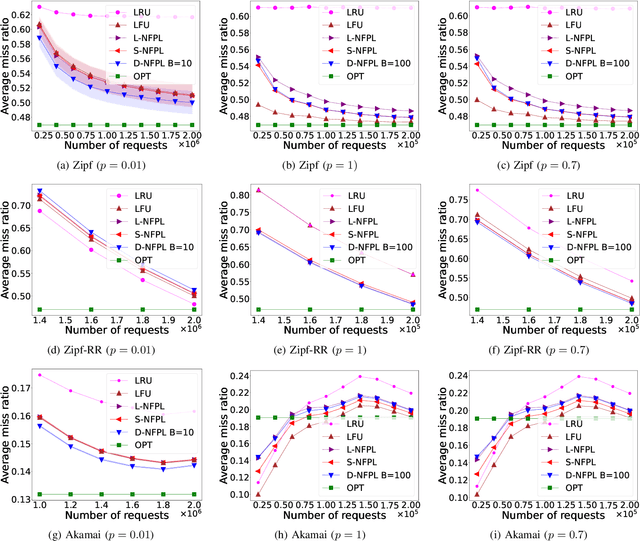
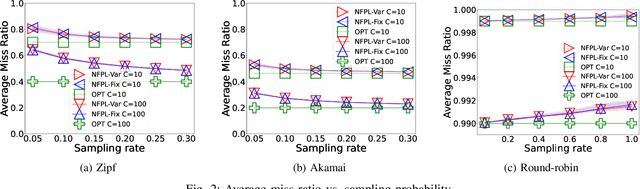


Online learning algorithms have been successfully used to design caching policies with sublinear regret in the total number of requests, with no statistical assumption about the request sequence. Most existing algorithms involve computationally expensive operations and require knowledge of all past requests. However, this may not be feasible in practical scenarios like caching at a cellular base station. Therefore, we study the caching problem in a more restrictive setting where only a fraction of past requests are observed, and we propose a randomized caching policy with sublinear regret based on the classic online learning algorithm Follow-the-Perturbed-Leader (FPL). Our caching policy is the first to attain the asymptotically optimal regret bound while ensuring asymptotically constant amortized time complexity in the partial observability setting of requests. The experimental evaluation compares the proposed solution against classic caching policies and validates the proposed approach under synthetic and real-world request traces.
No-Regret Caching with Noisy Request Estimates
Sep 05, 2023

Online learning algorithms have been successfully used to design caching policies with regret guarantees. Existing algorithms assume that the cache knows the exact request sequence, but this may not be feasible in high load and/or memory-constrained scenarios, where the cache may have access only to sampled requests or to approximate requests' counters. In this paper, we propose the Noisy-Follow-the-Perturbed-Leader (NFPL) algorithm, a variant of the classic Follow-the-Perturbed-Leader (FPL) when request estimates are noisy, and we show that the proposed solution has sublinear regret under specific conditions on the requests estimator. The experimental evaluation compares the proposed solution against classic caching policies and validates the proposed approach under both synthetic and real request traces.
Federated Learning under Heterogeneous and Correlated Client Availability
Jan 11, 2023



The enormous amount of data produced by mobile and IoT devices has motivated the development of federated learning (FL), a framework allowing such devices (or clients) to collaboratively train machine learning models without sharing their local data. FL algorithms (like FedAvg) iteratively aggregate model updates computed by clients on their own datasets. Clients may exhibit different levels of participation, often correlated over time and with other clients. This paper presents the first convergence analysis for a FedAvg-like FL algorithm under heterogeneous and correlated client availability. Our analysis highlights how correlation adversely affects the algorithm's convergence rate and how the aggregation strategy can alleviate this effect at the cost of steering training toward a biased model. Guided by the theoretical analysis, we propose CA-Fed, a new FL algorithm that tries to balance the conflicting goals of maximizing convergence speed and minimizing model bias. To this purpose, CA-Fed dynamically adapts the weight given to each client and may ignore clients with low availability and large correlation. Our experimental results show that CA-Fed achieves higher time-average accuracy and a lower standard deviation than state-of-the-art AdaFed and F3AST, both on synthetic and real datasets.