 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient and Optimal No-Regret Caching under Partial Observation
Paper and Code
Mar 04, 2025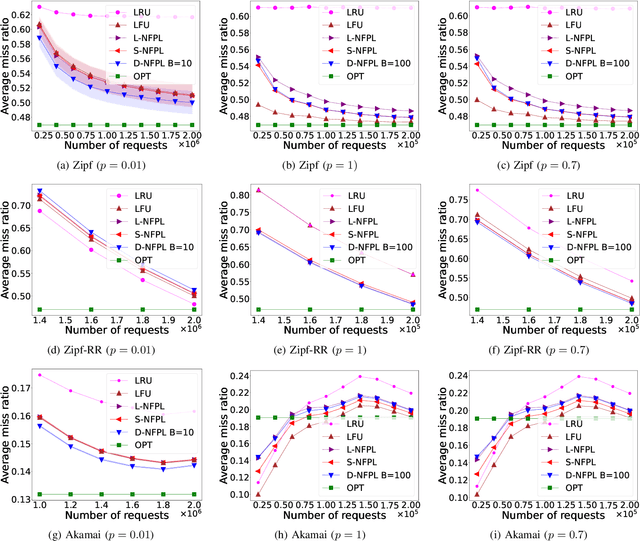
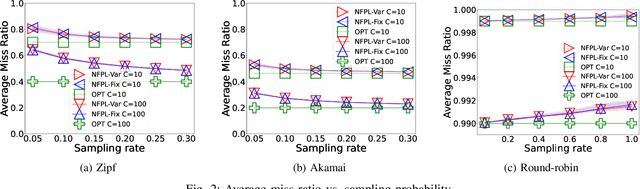


Online learning algorithms have been successfully used to design caching policies with sublinear regret in the total number of requests, with no statistical assumption about the request sequence. Most existing algorithms involve computationally expensive operations and require knowledge of all past requests. However, this may not be feasible in practical scenarios like caching at a cellular base station. Therefore, we study the caching problem in a more restrictive setting where only a fraction of past requests are observed, and we propose a randomized caching policy with sublinear regret based on the classic online learning algorithm Follow-the-Perturbed-Leader (FPL). Our caching policy is the first to attain the asymptotically optimal regret bound while ensuring asymptotically constant amortized time complexity in the partial observability setting of requests. The experimental evaluation compares the proposed solution against classic caching policies and validates the proposed approach under synthetic and real-world request traces.