 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBEACON: Benefit-Aware Early-Exit for Automatic Modulation Classification via Recoverability Prediction
Apr 09, 2026Convolutional neural networks (CNNs) have emerged as a powerful tool for automatic modulation classification (AMC) by directly extracting discriminative features from raw in-phase and quadrature (I/Q) signals. However, deploying CNN-based AMC models on IoT devices remains challenging because of limited computational resources, energy constraints, and real-time processing requirements. Early-exit (EE) strategies alleviate this burden by allowing qualified samples to terminate inference at an EE branch. However, our empirical analysis reveals a critical limitation of existing confidence-based EE strategies: they predominantly select samples whose early and final predictions are correct and consistent, while failing to capture whether deeper inference can provide a tangible accuracy gain. To address this limitation, we propose BEACON, a Benefit-Aware Early-Exit framework for AMC via recoverability prediction. BEACON introduces a benefit-aware EE criterion that explicitly predicts recoverable errors, defined as instances where the final-exit branch corrects an initial early-branch misclassification. Using only short-branch observables, we design a lightweight benefit-aware predictor (LBAP) to implement this criterion, estimating the likelihood of such recoverable cases and triggering deeper inference only when an accuracy gain is expected. Extensive experiments on ResNet-18-based AMC models demonstrate that the proposed approach consistently outperforms state-of-the-art baselines, achieving a superior accuracy-computation tradeoff across diverse EE threshold settings and signal-to-noise ratio regimes. These findings validate the effectiveness of the benefit-aware criterion and its practicality for energy-efficient on-device AMC under stringent resource constraints.
WirelessJEPA: A Multi-Antenna Foundation Model using Spatio-temporal Wireless Latent Predictions
Jan 28, 2026We propose WirelessJEPA, a novel wireless foundation model (WFM) that uses the Joint Embedding Predictive Architecture (JEPA). WirelessJEPA learns general-purpose representations directly from real-world multi-antenna IQ data by predicting latent representations of masked signal regions. This enables multiple diverse downstream tasks without reliance on carefully engineered contrastive augmentations. To adapt JEPA to wireless signals, we introduce a 2D antenna time representation that reshapes multi-antenna IQ streams into structured grids, allowing convolutional processing with block masking and efficient sparse computation over unmasked patches. Building on this representation, we propose novel spatio temporal mask geometries that encode inductive biases across antennas and time. We evaluate WirelessJEPA across six downstream tasks and demonstrate it's robust performance and strong task generalization. Our results establish that JEPA-based learning as a promising direction for building generalizable WFMs.
Multimodal Wireless Foundation Models
Nov 19, 2025Wireless foundation models (WFMs) have recently demonstrated promising capabilities, jointly performing multiple wireless functions and adapting effectively to new environments. However, while current WFMs process only one modality, depending on the task and operating conditions, the most informative modality changes and no single modality is best for all tasks. WFMs should therefore be designed to accept multiple modalities to enable a broader and more diverse range of tasks and scenarios. In this work, we propose and build the first multimodal wireless foundation model capable of processing both raw IQ streams and image-like wireless modalities (e.g., spectrograms and CSI) and performing multiple tasks across both. We introduce masked wireless modeling for the multimodal setting, a self-supervised objective and pretraining recipe that learns a joint representation from IQ streams and image-like wireless modalities. We evaluate the model on five tasks across both modality families: image-based (human activity sensing, RF signal classification, 5G NR positioning) and IQ-based (RF device fingerprinting, interference detection/classification). The multimodal WFM is competitive with single-modality WFMs, and in several cases surpasses their performance. Our results demonstrates the strong potential of developing multimodal WFMs that support diverse wireless tasks across different modalities. We believe this provides a concrete step toward both AI-native 6G and the vision of joint sensing, communication, and localization.
Adaptive Pareto-Optimal Token Merging for Edge Transformer Models in Semantic Communication
Sep 11, 2025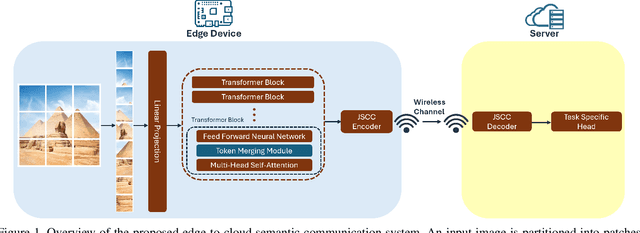
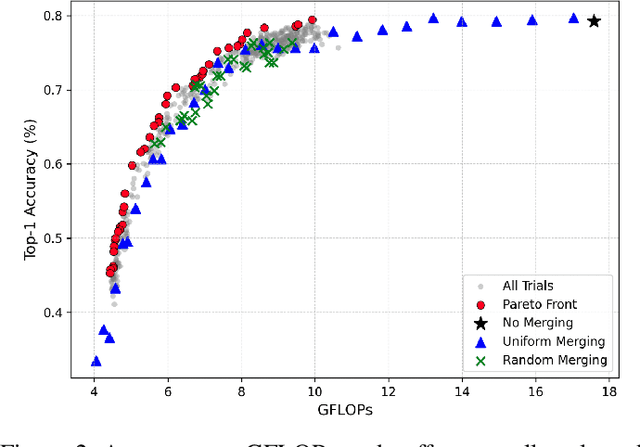
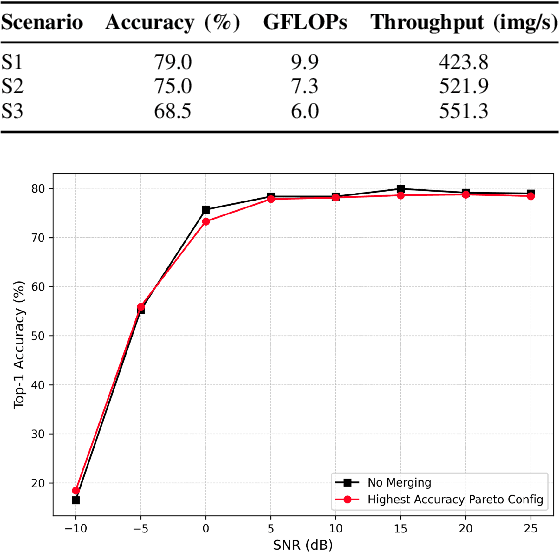
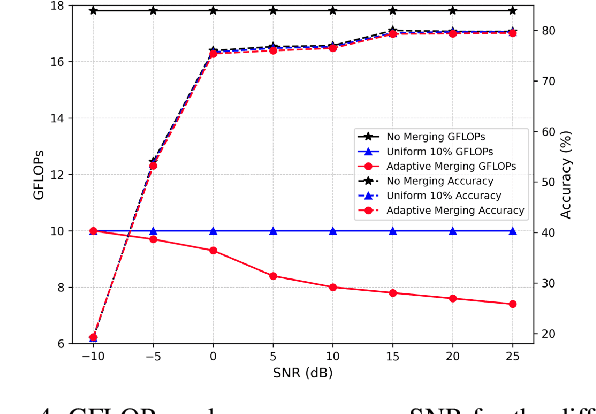
Large-scale transformer models have emerged as a powerful tool for semantic communication systems, enabling edge devices to extract rich representations for robust inference across noisy wireless channels. However, their substantial computational demands remain a major barrier to practical deployment in resource-constrained 6G networks. In this paper, we present a training-free framework for adaptive token merging in pretrained vision transformers to jointly reduce inference time and transmission resource usage. We formulate the selection of per-layer merging proportions as a multi-objective optimization problem to balance accuracy and computational cost. We employ Gaussian process-based Bayesian optimization to construct a Pareto frontier of optimal configurations, enabling flexible runtime adaptation to dynamic application requirements and channel conditions. Extensive experiments demonstrate that our method consistently outperforms other baselines and achieves significant reductions in floating-point operations while maintaining competitive accuracy across a wide range of signal-to-noise ratio (SNR) conditions. Additional results highlight the effectiveness of adaptive policies that adjust merging aggressiveness in response to channel quality, providing a practical mechanism to trade off latency and semantic fidelity on demand. These findings establish a scalable and efficient approach for deploying transformer-based semantic communication in future edge intelligence systems.
IQFM A Wireless Foundational Model for I/Q Streams in AI-Native 6G
Jun 07, 2025Foundational models have shown remarkable potential in natural language processing and computer vision, yet remain in their infancy in wireless communications. While a few efforts have explored image-based modalities such as channel state information (CSI) and frequency spectrograms, foundational models that operate directly on raw IQ data remain largely unexplored. This paper presents, IQFM, the first I/Q signal foundational model for wireless communications. IQFM supporting diverse tasks: modulation classification, angle-of-arrival (AoA), beam prediction, and RF fingerprinting, without heavy preprocessing or handcrafted features. We also introduce a task-aware augmentation strategy that categorizes transformations into core augmentations, such as cyclic time shifting, and task-specific augmentations. This strategy forms the basis for structured, task-dependent representation learning within a contrastive self-supervised learning (SSL) framework. Using this strategy, the lightweight encoder, pre-trained via SSL on over-the-air multi-antenna IQ data, achieves up to 99.67% and 65.45% accuracy on modulation and AoA classification, respectively, using only one labeled sample per class, outperforming supervised baselines by up to 7x and 145x. The model also generalizes to out-of-distribution tasks; when adapted to new tasks using only 500 samples per class and minimal parameter updates via LoRA, the same frozen encoder achieves 94.15% on beam prediction (vs. 89.53% supervised), 50.00% on RML2016a modulation classification (vs. 49.30%), and 96.05% on RF fingerprinting (vs. 96.64%). These results demonstrate the potential of raw IQ-based foundational models as efficient, reusable encoders for multi-task learning in AI-native 6G systems.
6G WavesFM: A Foundation Model for Sensing, Communication, and Localization
Apr 18, 2025



This paper introduces WavesFM, a novel Wireless Foundation Model (WFM) framework, capable of supporting a wide array of communication, sensing, and localization tasks. Our proposed architecture combines a shared Vision Transformer (ViT) backbone with task-specific multi-layer perceptron (MLP) heads and incorporates Low-Rank Adaptation (LoRA) for parameter-efficient fine-tuning. This design promotes full parameter sharing across tasks, significantly reducing the computational and memory footprint without sacrificing performance. The model processes both image-like wireless modalities, such as spectrograms and channel state information (CSI), and in-phase and quadrature (IQ) signals arranged as orthogonal frequency-division multiplexing (OFDM) resource grids. We demonstrate the strong generalization capabilities of WavesFM through extensive experiments on four downstream tasks: Fifth Generation New Radio (5G NR) positioning; multiple-input multiple-output OFDM (MIMO-OFDM) channel estimation; human activity sensing; and radio-frequency (RF) signal classification. Compared to supervised baselines trained individually, our approach achieves superior performance while sharing 80% of its parameters across tasks. Furthermore, we show that pretraining on domain-relevant data not only boosts performance but also accelerates convergence, reducing training time by up to 5x. These results demonstrate that our unified WFM can support diverse tasks and deliver significant gains in both performance and efficiency, highlighting the transformative potential of foundation models to drive AI-native paradigms in future sixth-generation (6G) networks.
SafeSlice: Enabling SLA-Compliant O-RAN Slicing via Safe Deep Reinforcement Learning
Mar 17, 2025Deep reinforcement learning (DRL)-based slicing policies have shown significant success in simulated environments but face challenges in physical systems such as open radio access networks (O-RANs) due to simulation-to-reality gaps. These policies often lack safety guarantees to ensure compliance with service level agreements (SLAs), such as the strict latency requirements of immersive applications. As a result, a deployed DRL slicing agent may make resource allocation (RA) decisions that degrade system performance, particularly in previously unseen scenarios. Real-world immersive applications require maintaining SLA constraints throughout deployment to prevent risky DRL exploration. In this paper, we propose SafeSlice to address both the cumulative (trajectory-wise) and instantaneous (state-wise) latency constraints of O-RAN slices. We incorporate the cumulative constraints by designing a sigmoid-based risk-sensitive reward function that reflects the slices' latency requirements. Moreover, we build a supervised learning cost model as part of a safety layer that projects the slicing agent's RA actions to the nearest safe actions, fulfilling instantaneous constraints. We conduct an exhaustive experiment that supports multiple services, including real virtual reality (VR) gaming traffic, to investigate the performance of SafeSlice under extreme and changing deployment conditions. SafeSlice achieves reductions of up to 83.23% in average cumulative latency, 93.24% in instantaneous latency violations, and 22.13% in resource consumption compared to the baselines. The results also indicate SafeSlice's robustness to changing the threshold configurations of latency constraints, a vital deployment scenario that will be realized by the O-RAN paradigm to empower mobile network operators (MNOs).
Intelligent Spectrum Sharing in Integrated TN-NTNs: A Hierarchical Deep Reinforcement Learning Approach
Mar 09, 2025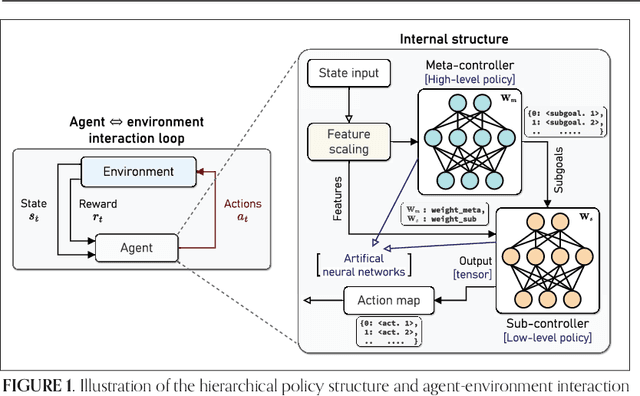


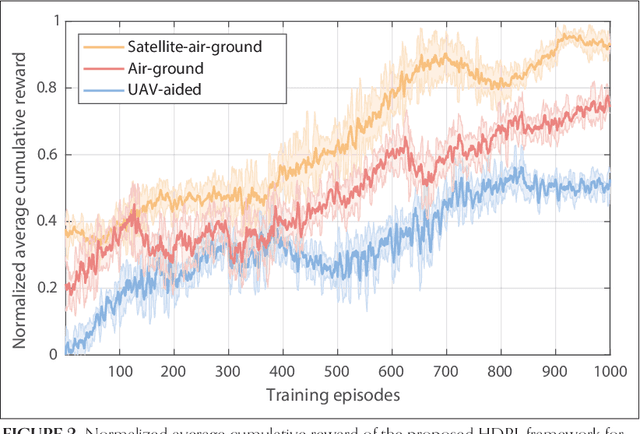
Integrating non-terrestrial networks (NTNs) with terrestrial networks (TNs) is key to enhancing coverage, capacity, and reliability in future wireless communications. However, the multi-tier, heterogeneous architecture of these integrated TN-NTNs introduces complex challenges in spectrum sharing and interference management. Conventional optimization approaches struggle to handle the high-dimensional decision space and dynamic nature of these networks. This paper proposes a novel hierarchical deep reinforcement learning (HDRL) framework to address these challenges and enable intelligent spectrum sharing. The proposed framework leverages the inherent hierarchy of the network, with separate policies for each tier, to learn and optimize spectrum allocation decisions at different timescales and levels of abstraction. By decomposing the complex spectrum sharing problem into manageable sub-tasks and allowing for efficient coordination among the tiers, the HDRL approach offers a scalable and adaptive solution for spectrum management in future TN-NTNs. Simulation results demonstrate the superior performance of the proposed framework compared to traditional approaches, highlighting its potential to enhance spectral efficiency and network capacity in dynamic, multi-tier environments.
Computation Offloading Strategies in Integrated Terrestrial and Non-Terrestrial Networks
Feb 21, 2025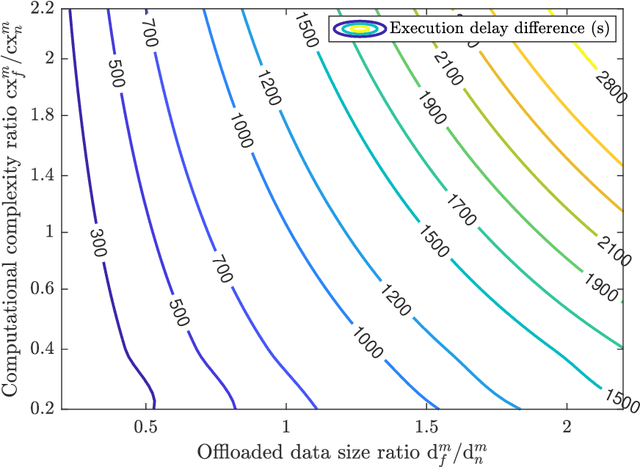

The rapid growth of computation-intensive applications like augmented reality, autonomous driving, remote healthcare, and smart cities has exposed the limitations of traditional terrestrial networks, particularly in terms of inadequate coverage, limited capacity, and high latency in remote areas. This chapter explores how integrated terrestrial and non-terrestrial networks (IT-NTNs) can address these challenges and enable efficient computation offloading. We examine mobile edge computing (MEC) and its evolution toward multiple-access edge computing, highlighting the critical role computation offloading plays for resource-constrained devices. We then discuss the architecture of IT-NTNs, focusing on how terrestrial base stations, unmanned aerial vehicles (UAVs), high-altitude platforms (HAPs), and LEO satellites work together to deliver ubiquitous connectivity. Furthermore, we analyze various computation offloading strategies, including edge, cloud, and hybrid offloading, outlining their strengths and weaknesses. Key enabling technologies such as NOMA, mmWave/THz communication, and reconfigurable intelligent surfaces (RIS) are also explored as essential components of existing algorithms for resource allocation, task offloading decisions, and mobility management. Finally, we conclude by highlighting the transformative impact of computation offloading in IT-NTNs across diverse application areas and discuss key challenges and future research directions, emphasizing the potential of these networks to revolutionize communication and computation paradigms.
ProtoBeam: Generalizing Deep Beam Prediction to Unseen Antennas using Prototypical Networks
Jan 06, 2025



Deep learning techniques have recently emerged to efficiently manage mmWave beam transmissions without requiring time consuming beam sweeping strategies. A fundamental challenge in these methods is their dependency on hardware-specific training data and their limited ability to generalize. Large drops in performance are reported in literature when DL models trained in one antenna environment are applied in another. This paper proposes the application of Prototypical Networks to address this challenge and utilizes the DeepBeam real-world dataset to validate the developed solutions. Prototypical Networks excel in extracting features to establish class-specific prototypes during the training, resulting in precise embeddings that encapsulate the defining features of the data. We demonstrate the effectiveness of PN to enable generalization of deep beam predictors across unseen antennas. Our approach, which integrates data normalization and prototype normalization with the PN, achieves an average beam classification accuracy of 74.11 percent when trained and tested on different antenna datasets. This is an improvement of 398 percent compared to baseline performances reported in literature that do not account for such domain shifts. To the best of our knowledge, this work represents the first demonstration of the value of Prototypical Networks for domain adaptation in wireless networks, providing a foundation for future research in this area.