 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafeSlice: Enabling SLA-Compliant O-RAN Slicing via Safe Deep Reinforcement Learning
Mar 17, 2025Deep reinforcement learning (DRL)-based slicing policies have shown significant success in simulated environments but face challenges in physical systems such as open radio access networks (O-RANs) due to simulation-to-reality gaps. These policies often lack safety guarantees to ensure compliance with service level agreements (SLAs), such as the strict latency requirements of immersive applications. As a result, a deployed DRL slicing agent may make resource allocation (RA) decisions that degrade system performance, particularly in previously unseen scenarios. Real-world immersive applications require maintaining SLA constraints throughout deployment to prevent risky DRL exploration. In this paper, we propose SafeSlice to address both the cumulative (trajectory-wise) and instantaneous (state-wise) latency constraints of O-RAN slices. We incorporate the cumulative constraints by designing a sigmoid-based risk-sensitive reward function that reflects the slices' latency requirements. Moreover, we build a supervised learning cost model as part of a safety layer that projects the slicing agent's RA actions to the nearest safe actions, fulfilling instantaneous constraints. We conduct an exhaustive experiment that supports multiple services, including real virtual reality (VR) gaming traffic, to investigate the performance of SafeSlice under extreme and changing deployment conditions. SafeSlice achieves reductions of up to 83.23% in average cumulative latency, 93.24% in instantaneous latency violations, and 22.13% in resource consumption compared to the baselines. The results also indicate SafeSlice's robustness to changing the threshold configurations of latency constraints, a vital deployment scenario that will be realized by the O-RAN paradigm to empower mobile network operators (MNOs).
Safe and Accelerated Deep Reinforcement Learning-based O-RAN Slicing: A Hybrid Transfer Learning Approach
Sep 18, 2023The open radio access network (O-RAN) architecture supports intelligent network control algorithms as one of its core capabilities. Data-driven applications incorporate such algorithms to optimize radio access network (RAN) functions via RAN intelligent controllers (RICs). Deep reinforcement learning (DRL) algorithms are among the main approaches adopted in the O-RAN literature to solve dynamic radio resource management problems. However, despite the benefits introduced by the O-RAN RICs, the practical adoption of DRL algorithms in real network deployments falls behind. This is primarily due to the slow convergence and unstable performance exhibited by DRL agents upon deployment and when encountering previously unseen network conditions. In this paper, we address these challenges by proposing transfer learning (TL) as a core component of the training and deployment workflows for the DRL-based closed-loop control of O-RAN functionalities. To this end, we propose and design a hybrid TL-aided approach that leverages the advantages of both policy reuse and distillation TL methods to provide safe and accelerated convergence in DRL-based O-RAN slicing. We conduct a thorough experiment that accommodates multiple services, including real VR gaming traffic to reflect practical scenarios of O-RAN slicing. We also propose and implement policy reuse and distillation-aided DRL and non-TL-aided DRL as three separate baselines. The proposed hybrid approach shows at least: 7.7% and 20.7% improvements in the average initial reward value and the percentage of converged scenarios, and a 64.6% decrease in reward variance while maintaining fast convergence and enhancing the generalizability compared with the baselines.
How Does Forecasting Affect the Convergence of DRL Techniques in O-RAN Slicing?
Sep 01, 2023The success of immersive applications such as virtual reality (VR) gaming and metaverse services depends on low latency and reliable connectivity. To provide seamless user experiences, the open radio access network (O-RAN) architecture and 6G networks are expected to play a crucial role. RAN slicing, a critical component of the O-RAN paradigm, enables network resources to be allocated based on the needs of immersive services, creating multiple virtual networks on a single physical infrastructure. In the O-RAN literature, deep reinforcement learning (DRL) algorithms are commonly used to optimize resource allocation. However, the practical adoption of DRL in live deployments has been sluggish. This is primarily due to the slow convergence and performance instabilities suffered by the DRL agents both upon initial deployment and when there are significant changes in network conditions. In this paper, we investigate the impact of time series forecasting of traffic demands on the convergence of the DRL-based slicing agents. For that, we conduct an exhaustive experiment that supports multiple services including real VR gaming traffic. We then propose a novel forecasting-aided DRL approach and its respective O-RAN practical deployment workflow to enhance DRL convergence. Our approach shows up to 22.8%, 86.3%, and 300% improvements in the average initial reward value, convergence rate, and number of converged scenarios respectively, enhancing the generalizability of the DRL agents compared with the implemented baselines. The results also indicate that our approach is robust against forecasting errors and that forecasting models do not have to be ideal.
Toward Safe and Accelerated Deep Reinforcement Learning for Next-Generation Wireless Networks
Sep 16, 2022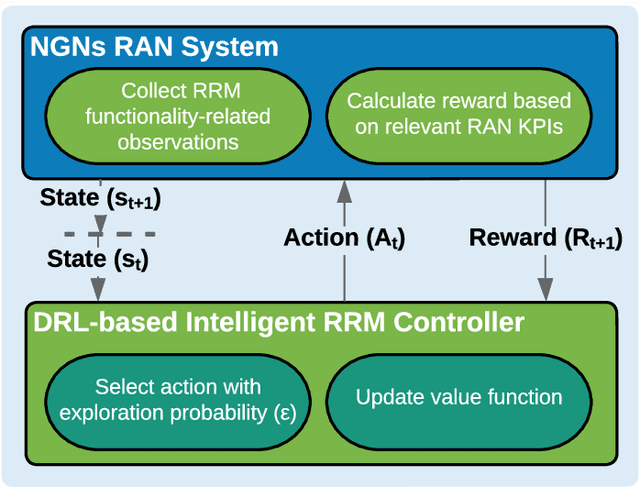
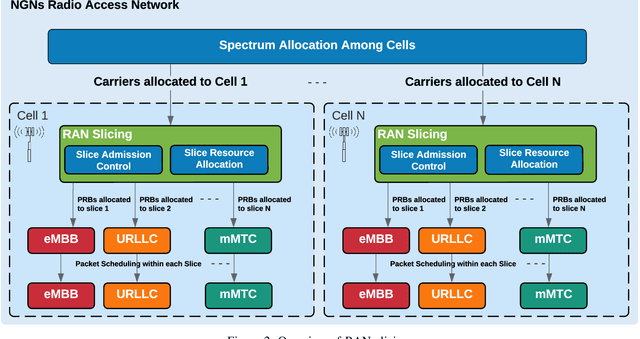
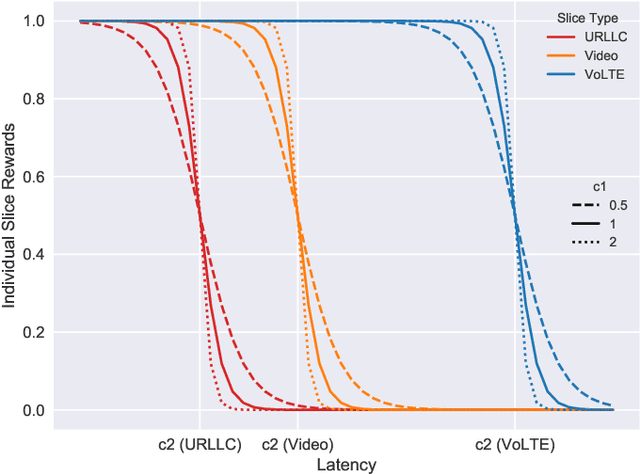
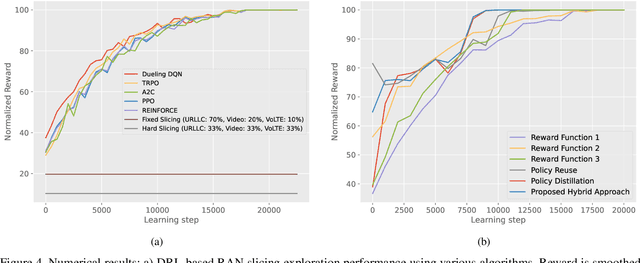
Deep reinforcement learning (DRL) algorithms have recently gained wide attention in the wireless networks domain. They are considered promising approaches for solving dynamic radio resource management (RRM) problems in next-generation networks. Given their capabilities to build an approximate and continuously updated model of the wireless network environments, DRL algorithms can deal with the multifaceted complexity of such environments. Nevertheless, several challenges hinder the practical adoption of DRL in commercial networks. In this article, we first discuss two key practical challenges that are faced but rarely tackled when developing DRL-based RRM solutions. We argue that it is inevitable to address these DRL-related challenges for DRL to find its way to RRM commercial solutions. In particular, we discuss the need to have safe and accelerated DRL-based RRM solutions that mitigate the slow convergence and performance instability exhibited by DRL algorithms. We then review and categorize the main approaches used in the RRM domain to develop safe and accelerated DRL-based solutions. Finally, a case study is conducted to demonstrate the importance of having safe and accelerated DRL-based RRM solutions. We employ multiple variants of transfer learning (TL) techniques to accelerate the convergence of intelligent radio access network (RAN) slicing DRL-based controllers. We also propose a hybrid TL-based approach and sigmoid function-based rewards as examples of safe exploration in DRL-based RAN slicing.