 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProtoAoA: Few-Shot Angle-of-Arrival Estimation using Prototypical Networks
Apr 15, 2026Angle-of-arrival (AoA) estimation is a crucial function in wireless communications used for localization, beam-forming, interference management, and other applications. Deep learning (DL) solutions have been proposed for AoA to mitigate limitations of traditional AoA estimation techniques such as sensitivity to noise and the inability to generalize across different array characteristics. A challenge, however, of DL-based approaches is their reliance on large data collection campaigns and model training. This paper proposes the application of Prototypical Networks (PN) to address this challenge and utilizes a real-world dataset collected on a software defined radio (SDR) testbed to validate the effectiveness of the proposed solution. Prototypical Networks excel in extracting representative embeddings from unstructured input data, establishing class prototypes during training that can be few-shot trained on unseen classes. We demonstrate the efficacy of PNs for AoA classification using complex IQ samples, focusing on its ability to correctly classify new, unseen angles that the model was not trained on previously. Our results show that training our proposed ProtoAoA on only 23% of the AoA dataset classes can attain a mean absolute error (MAE) of 3 degrees with only 4-shots of training on the unseen angles - and an MAE of 2 degrees with 32-shots of training data. These results demonstrate that the developed prototypical network architecture requires remarkably few data samples to achieve reliable AoA estimation - and highlights its potential for other wireless applications where data availability is limited.
ProtoBeam: Generalizing Deep Beam Prediction to Unseen Antennas using Prototypical Networks
Jan 06, 2025



Deep learning techniques have recently emerged to efficiently manage mmWave beam transmissions without requiring time consuming beam sweeping strategies. A fundamental challenge in these methods is their dependency on hardware-specific training data and their limited ability to generalize. Large drops in performance are reported in literature when DL models trained in one antenna environment are applied in another. This paper proposes the application of Prototypical Networks to address this challenge and utilizes the DeepBeam real-world dataset to validate the developed solutions. Prototypical Networks excel in extracting features to establish class-specific prototypes during the training, resulting in precise embeddings that encapsulate the defining features of the data. We demonstrate the effectiveness of PN to enable generalization of deep beam predictors across unseen antennas. Our approach, which integrates data normalization and prototype normalization with the PN, achieves an average beam classification accuracy of 74.11 percent when trained and tested on different antenna datasets. This is an improvement of 398 percent compared to baseline performances reported in literature that do not account for such domain shifts. To the best of our knowledge, this work represents the first demonstration of the value of Prototypical Networks for domain adaptation in wireless networks, providing a foundation for future research in this area.
Building 6G Radio Foundation Models with Transformer Architectures
Nov 15, 2024Foundation deep learning (DL) models are general models, designed to learn general, robust and adaptable representations of their target modality, enabling finetuning across a range of downstream tasks. These models are pretrained on large, unlabeled datasets using self-supervised learning (SSL). Foundation models have demonstrated better generalization than traditional supervised approaches, a critical requirement for wireless communications where the dynamic environment demands model adaptability. In this work, we propose and demonstrate the effectiveness of a Vision Transformer (ViT) as a radio foundation model for spectrogram learning. We introduce a Masked Spectrogram Modeling (MSM) approach to pretrain the ViT in a self-supervised fashion. We evaluate the ViT-based foundation model on two downstream tasks: Channel State Information (CSI)-based Human Activity sensing and Spectrogram Segmentation. Experimental results demonstrate competitive performance to supervised training while generalizing across diverse domains. Notably, the pretrained ViT model outperforms a four-times larger model that is trained from scratch on the spectrogram segmentation task, while requiring significantly less training time, and achieves competitive performance on the CSI-based human activity sensing task. This work demonstrates the effectiveness of ViT with MSM for pretraining as a promising technique for scalable foundation model development in future 6G networks.
Self-Supervised Radio Pre-training: Toward Foundational Models for Spectrogram Learning
Nov 14, 2024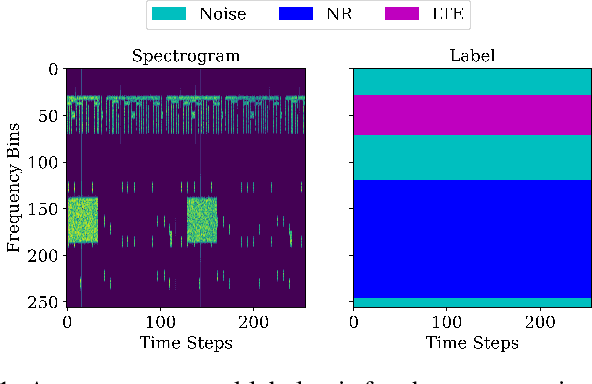
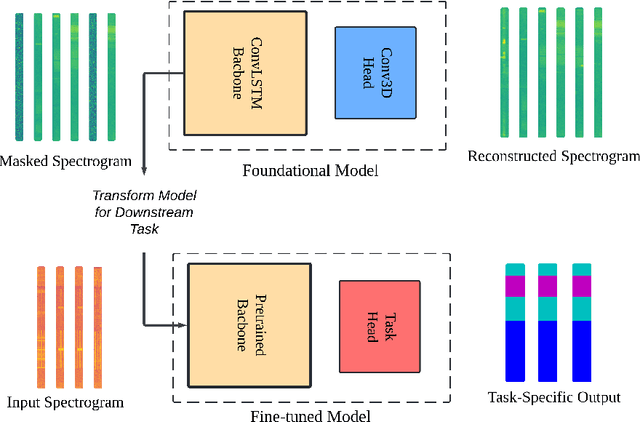
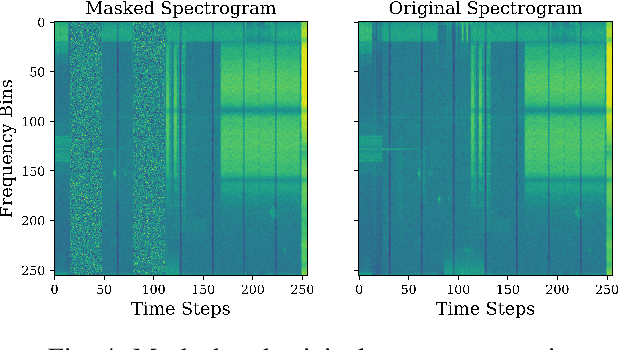
Foundational deep learning (DL) models are general models, trained on large, diverse, and unlabelled datasets, typically using self-supervised learning techniques have led to significant advancements especially in natural language processing. These pretrained models can be fine-tuned for related downstream tasks, offering faster development and reduced training costs, while often achieving improved performance. In this work, we introduce Masked Spectrogram Modeling, a novel self-supervised learning approach for pretraining foundational DL models on radio signals. Adopting a Convolutional LSTM architecture for efficient spatio-temporal processing, we pretrain the model with an unlabelled radio dataset collected from over-the-air measurements. Subsequently, the pretrained model is fine-tuned for two downstream tasks: spectrum forecasting and segmentation. Experimental results demonstrate that our methodology achieves competitive performance in both forecasting accuracy and segmentation, validating its effectiveness for developing foundational radio models.