 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing Evaluation Metrics for Neural Test Oracle Generation
Oct 11, 2023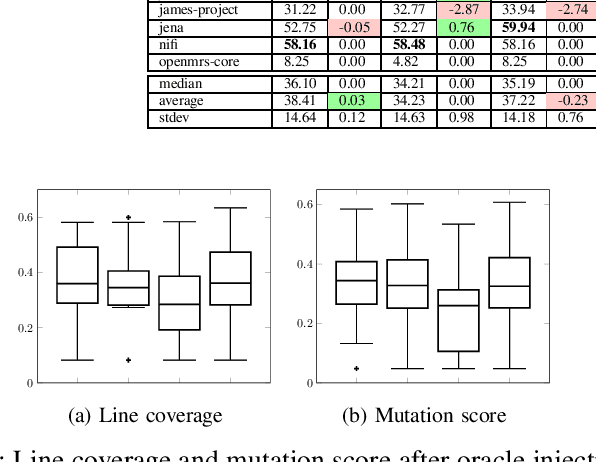


In this work, we revisit existing oracle generation studies plus ChatGPT to empirically investigate the current standing of their performance in both NLG-based and test adequacy metrics. Specifically, we train and run four state-of-the-art test oracle generation models on five NLG-based and two test adequacy metrics for our analysis. We apply two different correlation analyses between these two different sets of metrics. Surprisingly, we found no significant correlation between the NLG-based metrics and test adequacy metrics. For instance, oracles generated from ChatGPT on the project activemq-artemis had the highest performance on all the NLG-based metrics among the studied NOGs, however, it had the most number of projects with a decrease in test adequacy metrics compared to all the studied NOGs. We further conduct a qualitative analysis to explore the reasons behind our observations, we found that oracles with high NLG-based metrics but low test adequacy metrics tend to have complex or multiple chained method invocations within the oracle's parameters, making it hard for the model to generate completely, affecting the test adequacy metrics. On the other hand, oracles with low NLG-based metrics but high test adequacy metrics tend to have to call different assertion types or a different method that functions similarly to the ones in the ground truth. Overall, this work complements prior studies on test oracle generation with an extensive performance evaluation with both NLG and test adequacy metrics and provides guidelines for better assessment of deep learning applications in software test generation in the future.
Automated Test Case Generation Using Code Models and Domain Adaptation
Aug 15, 2023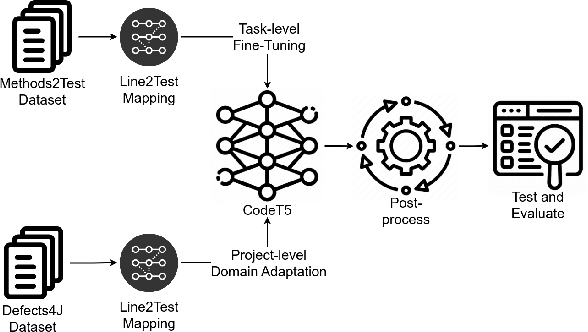



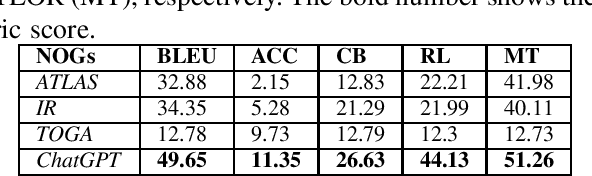
State-of-the-art automated test generation techniques, such as search-based testing, are usually ignorant about what a developer would create as a test case. Therefore, they typically create tests that are not human-readable and may not necessarily detect all types of complex bugs developer-written tests would do. In this study, we leverage Transformer-based code models to generate unit tests that can complement search-based test generation. Specifically, we use CodeT5, i.e., a state-of-the-art large code model, and fine-tune it on the test generation downstream task. For our analysis, we use the Methods2test dataset for fine-tuning CodeT5 and Defects4j for project-level domain adaptation and evaluation. The main contribution of this study is proposing a fully automated testing framework that leverages developer-written tests and available code models to generate compilable, human-readable unit tests. Results show that our approach can generate new test cases that cover lines that were not covered by developer-written tests. Using domain adaptation, we can also increase line coverage of the model-generated unit tests by 49.9% and 54% in terms of mean and median (compared to the model without domain adaptation). We can also use our framework as a complementary solution alongside common search-based methods to increase the overall coverage with mean and median of 25.3% and 6.3%. It can also increase the mutation score of search-based methods by killing extra mutants (up to 64 new mutants were killed per project in our experiments).