 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan ChatGPT Support Developers? An Empirical Evaluation of Large Language Models for Code Generation
Feb 18, 2024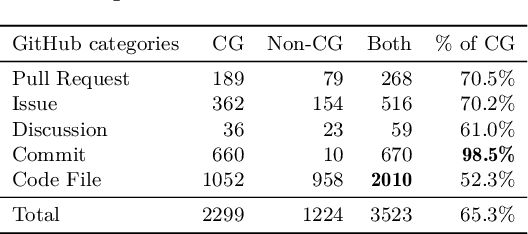
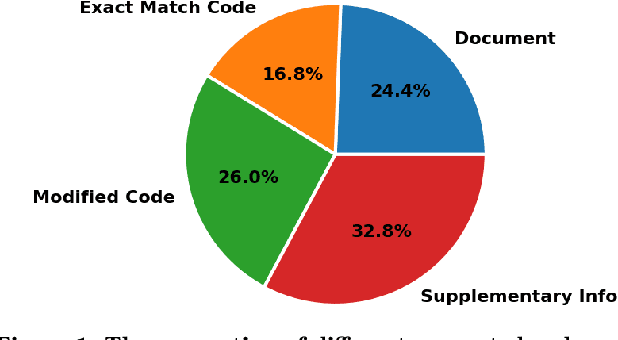

Large language models (LLMs) have demonstrated notable proficiency in code generation, with numerous prior studies showing their promising capabilities in various development scenarios. However, these studies mainly provide evaluations in research settings, which leaves a significant gap in understanding how effectively LLMs can support developers in real-world. To address this, we conducted an empirical analysis of conversations in DevGPT, a dataset collected from developers' conversations with ChatGPT (captured with the Share Link feature on platforms such as GitHub). Our empirical findings indicate that the current practice of using LLM-generated code is typically limited to either demonstrating high-level concepts or providing examples in documentation, rather than to be used as production-ready code. These findings indicate that there is much future work needed to improve LLMs in code generation before they can be integral parts of modern software development.