 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSwiftLearn: A Data-Efficient Training Method of Deep Learning Models using Importance Sampling
Nov 25, 2023
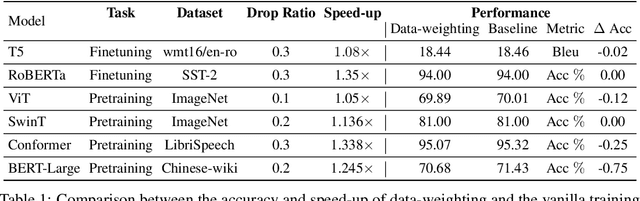

In this paper, we present SwiftLearn, a data-efficient approach to accelerate training of deep learning models using a subset of data samples selected during the warm-up stages of training. This subset is selected based on an importance criteria measured over the entire dataset during warm-up stages, aiming to preserve the model performance with fewer examples during the rest of training. The importance measure we propose could be updated during training every once in a while, to make sure that all of the data samples have a chance to return to the training loop if they show a higher importance. The model architecture is unchanged but since the number of data samples controls the number of forward and backward passes during training, we can reduce the training time by reducing the number of training samples used in each epoch of training. Experimental results on a variety of CV and NLP models during both pretraining and finetuning show that the model performance could be preserved while achieving a significant speed-up during training. More specifically, BERT finetuning on GLUE benchmark shows that almost 90% of the data can be dropped achieving an end-to-end average speedup of 3.36x while keeping the average accuracy drop less than 0.92%.
Reproducing AmbientGAN: Generative models from lossy measurements
Oct 23, 2018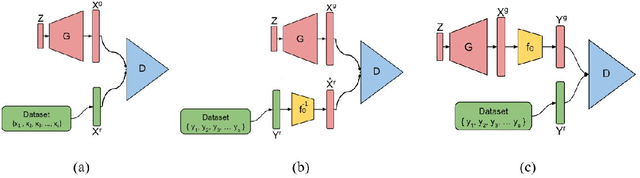



In recent years, Generative Adversarial Networks (GANs) have shown substantial progress in modeling complex distributions of data. These networks have received tremendous attention since they can generate implicit probabilistic models that produce realistic data using a stochastic procedure. While such models have proven highly effective in diverse scenarios, they require a large set of fully-observed training samples. In many applications access to such samples are difficult or even impractical and only noisy or partial observations of the desired distribution is available. Recent research has tried to address the problem of incompletely observed samples to recover the distribution of the data. \citep{zhu2017unpaired} and \citep{yeh2016semantic} proposed methods to solve ill-posed inverse problem using cycle-consistency and latent-space mappings in adversarial networks, respectively. \citep{bora2017compressed} and \citep{kabkab2018task} have applied similar adversarial approaches to the problem of compressed sensing. In this work, we focus on a new variant of GAN models called AmbientGAN, which incorporates a measurement process (e.g. adding noise, data removal and projection) into the GAN training. While in the standard GAN, the discriminator distinguishes a generated image from a real image, in AmbientGAN model the discriminator has to separate a real measurement from a simulated measurement of a generated image. The results shown by \citep{bora2018ambientgan} are quite promising for the problem of incomplete data, and have potentially important implications for generative approaches to compressed sensing and ill-posed problems.
* This work was submitted as final project for the course IFT6135: Representation Learning - A Deep Learning Course, University of Montreal, Winter 2018
Brain Tumor Segmentation Using Deep Learning by Type Specific Sorting of Images
Sep 20, 2018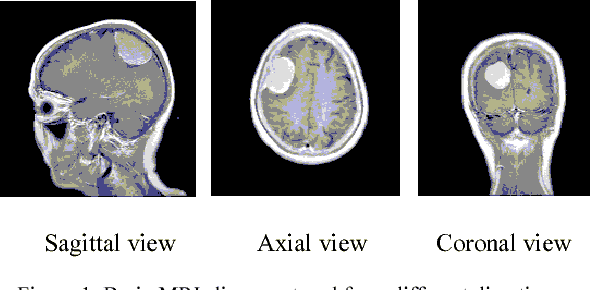
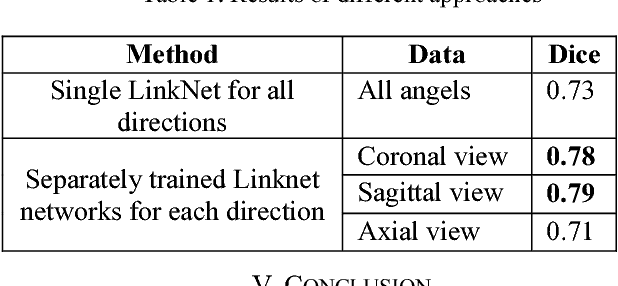

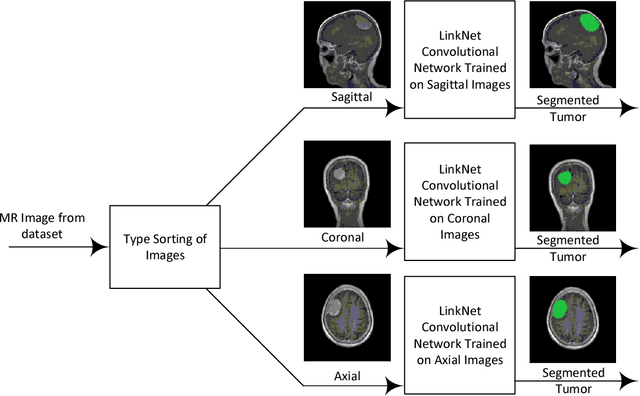
Recently deep learning has been playing a major role in the field of computer vision. One of its applications is the reduction of human judgment in the diagnosis of diseases. Especially, brain tumor diagnosis requires high accuracy, where minute errors in judgment may lead to disaster. For this reason, brain tumor segmentation is an important challenge for medical purposes. Currently several methods exist for tumor segmentation but they all lack high accuracy. Here we present a solution for brain tumor segmenting by using deep learning. In this work, we studied different angles of brain MR images and applied different networks for segmentation. The effect of using separate networks for segmentation of MR images is evaluated by comparing the results with a single network. Experimental evaluations of the networks show that Dice score of 0.73 is achieved for a single network and 0.79 in obtained for multiple networks.