 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards training digitally-tied analog blocks via hybrid gradient computation
Sep 05, 2024Power efficiency is plateauing in the standard digital electronics realm such that novel hardware, models, and algorithms are needed to reduce the costs of AI training. The combination of energy-based analog circuits and the Equilibrium Propagation (EP) algorithm constitutes one compelling alternative compute paradigm for gradient-based optimization of neural nets. Existing analog hardware accelerators, however, typically incorporate digital circuitry to sustain auxiliary non-weight-stationary operations, mitigate analog device imperfections, and leverage existing digital accelerators.This heterogeneous hardware approach calls for a new theoretical model building block. In this work, we introduce Feedforward-tied Energy-based Models (ff-EBMs), a hybrid model comprising feedforward and energy-based blocks accounting for digital and analog circuits. We derive a novel algorithm to compute gradients end-to-end in ff-EBMs by backpropagating and "eq-propagating" through feedforward and energy-based parts respectively, enabling EP to be applied to much more flexible and realistic architectures. We experimentally demonstrate the effectiveness of the proposed approach on ff-EBMs where Deep Hopfield Networks (DHNs) are used as energy-based blocks. We first show that a standard DHN can be arbitrarily split into any uniform size while maintaining performance. We then train ff-EBMs on ImageNet32 where we establish new SOTA performance in the EP literature (46 top-1 %). Our approach offers a principled, scalable, and incremental roadmap to gradually integrate self-trainable analog computational primitives into existing digital accelerators.
Reproducing AmbientGAN: Generative models from lossy measurements
Oct 23, 2018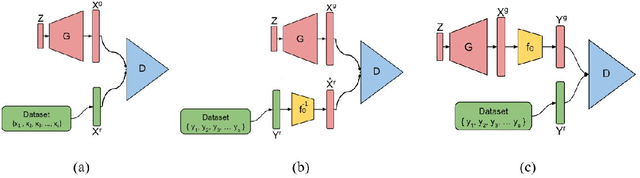



In recent years, Generative Adversarial Networks (GANs) have shown substantial progress in modeling complex distributions of data. These networks have received tremendous attention since they can generate implicit probabilistic models that produce realistic data using a stochastic procedure. While such models have proven highly effective in diverse scenarios, they require a large set of fully-observed training samples. In many applications access to such samples are difficult or even impractical and only noisy or partial observations of the desired distribution is available. Recent research has tried to address the problem of incompletely observed samples to recover the distribution of the data. \citep{zhu2017unpaired} and \citep{yeh2016semantic} proposed methods to solve ill-posed inverse problem using cycle-consistency and latent-space mappings in adversarial networks, respectively. \citep{bora2017compressed} and \citep{kabkab2018task} have applied similar adversarial approaches to the problem of compressed sensing. In this work, we focus on a new variant of GAN models called AmbientGAN, which incorporates a measurement process (e.g. adding noise, data removal and projection) into the GAN training. While in the standard GAN, the discriminator distinguishes a generated image from a real image, in AmbientGAN model the discriminator has to separate a real measurement from a simulated measurement of a generated image. The results shown by \citep{bora2018ambientgan} are quite promising for the problem of incomplete data, and have potentially important implications for generative approaches to compressed sensing and ill-posed problems.
* This work was submitted as final project for the course IFT6135: Representation Learning - A Deep Learning Course, University of Montreal, Winter 2018