 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating the Low-Rank Decomposed Models
Paper and Code
Jul 24, 2024
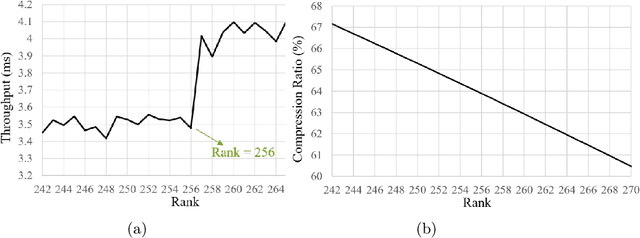
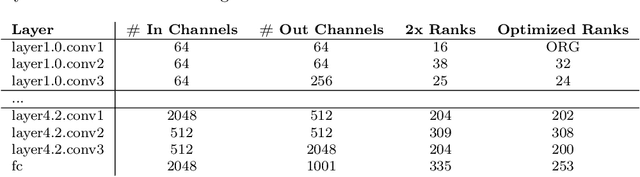
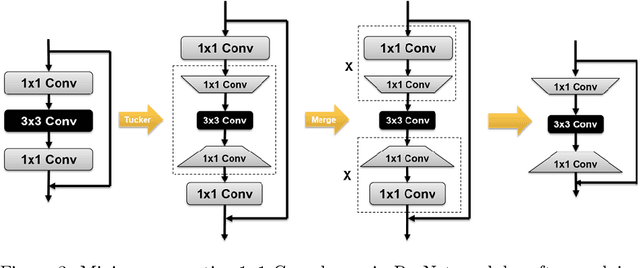
Tensor decomposition is a mathematically supported technique for data compression. It consists of applying some kind of a Low Rank Decomposition technique on the tensors or matrices in order to reduce the redundancy of the data. However, it is not a popular technique for compressing the AI models duo to the high number of new layers added to the architecture after decomposition. Although the number of parameters could shrink significantly, it could result in the model be more than twice deeper which could add some latency to the training or inference. In this paper, we present a comprehensive study about how to modify low rank decomposition technique in AI models so that we could benefit from both high accuracy and low memory consumption as well as speeding up the training and inference