 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTensorDash: Exploiting Sparsity to Accelerate Deep Neural Network Training and Inference
Sep 01, 2020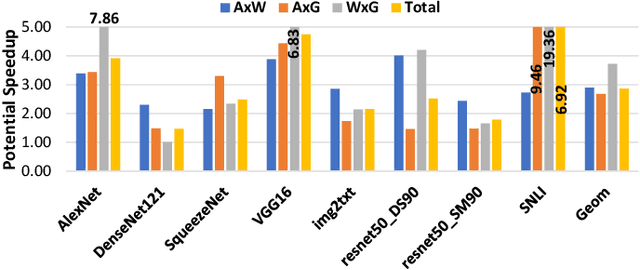
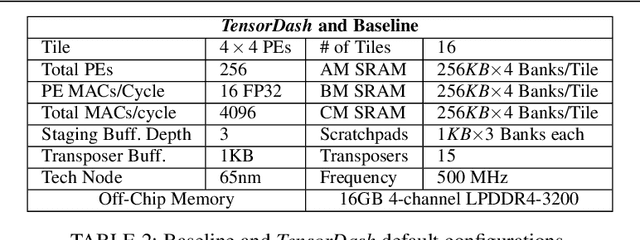
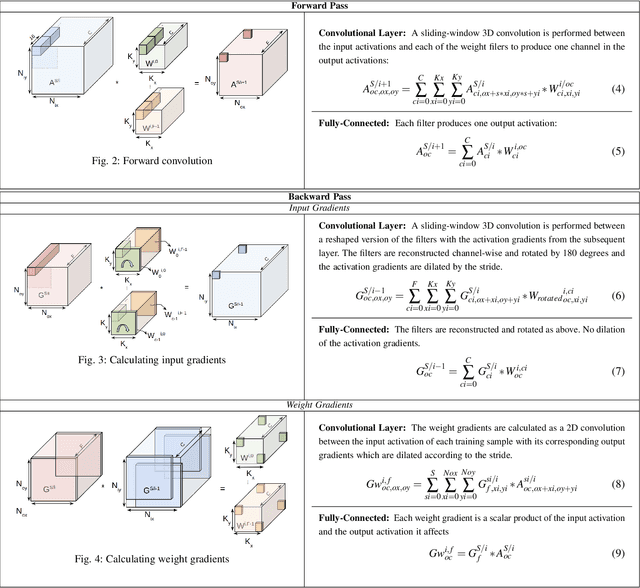
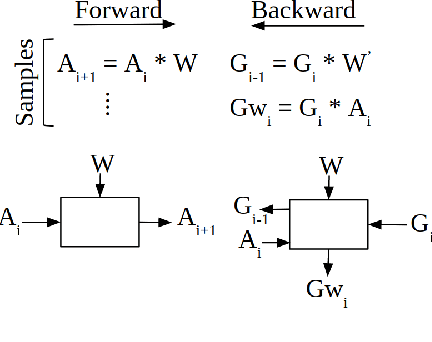
TensorDash is a hardware level technique for enabling data-parallel MAC units to take advantage of sparsity in their input operand streams. When used to compose a hardware accelerator for deep learning, TensorDash can speedup the training process while also increasing energy efficiency. TensorDash combines a low-cost, sparse input operand interconnect comprising an 8-input multiplexer per multiplier input, with an area-efficient hardware scheduler. While the interconnect allows a very limited set of movements per operand, the scheduler can effectively extract sparsity when it is present in the activations, weights or gradients of neural networks. Over a wide set of models covering various applications, TensorDash accelerates the training process by $1.95{\times}$ while being $1.89\times$ more energy-efficient, $1.6\times$ more energy efficient when taking on-chip and off-chip memory accesses into account. While TensorDash works with any datatype, we demonstrate it with both single-precision floating-point units and bfloat16.
Reduced-Precision Strategies for Bounded Memory in Deep Neural Nets
Jan 08, 2016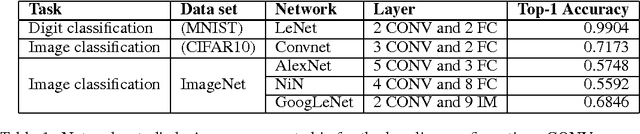
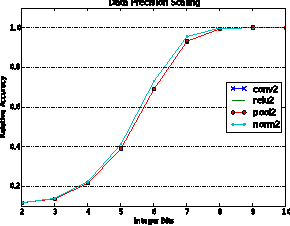
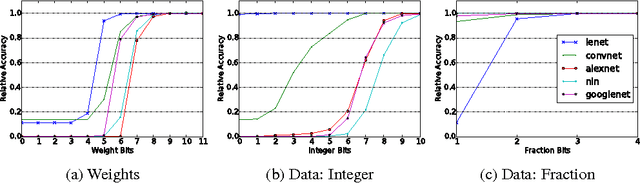
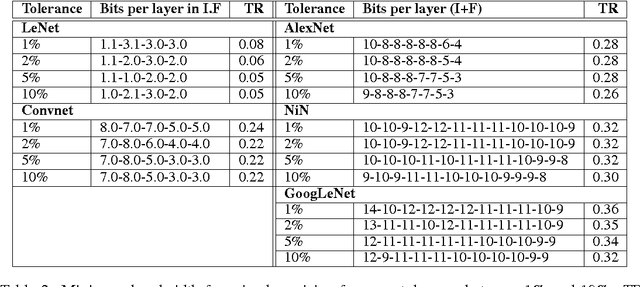
This work investigates how using reduced precision data in Convolutional Neural Networks (CNNs) affects network accuracy during classification. More specifically, this study considers networks where each layer may use different precision data. Our key result is the observation that the tolerance of CNNs to reduced precision data not only varies across networks, a well established observation, but also within networks. Tuning precision per layer is appealing as it could enable energy and performance improvements. In this paper we study how error tolerance across layers varies and propose a method for finding a low precision configuration for a network while maintaining high accuracy. A diverse set of CNNs is analyzed showing that compared to a conventional implementation using a 32-bit floating-point representation for all layers, and with less than 1% loss in relative accuracy, the data footprint required by these networks can be reduced by an average of 74% and up to 92%.