 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoom: Exploiting Weight and Activation Precisions to Accelerate Convolutional Neural Networks
Paper and Code
May 16, 2018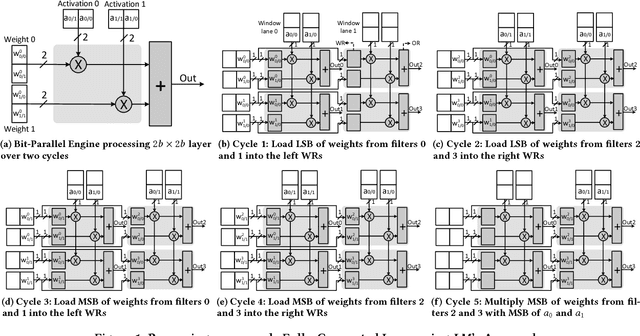
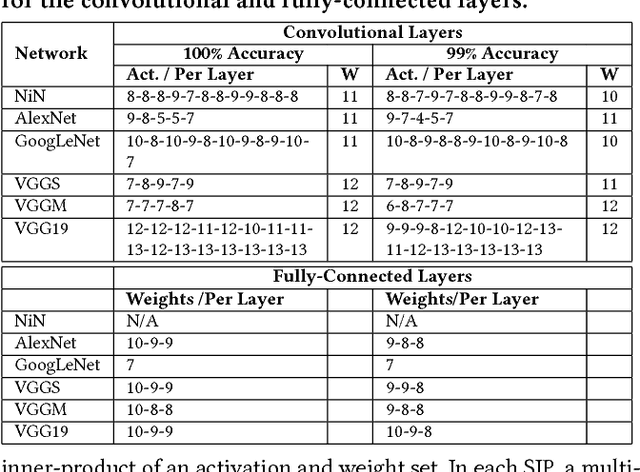
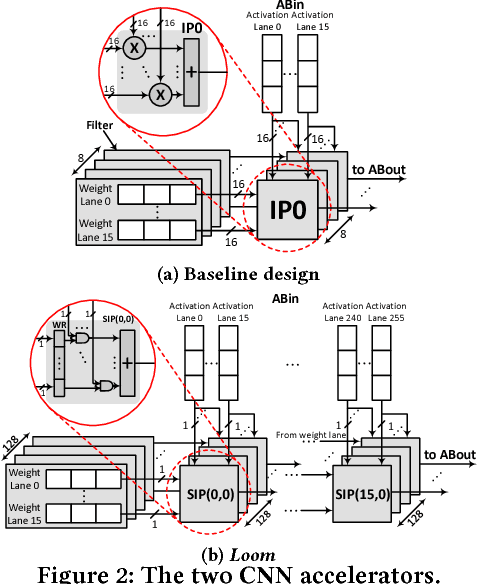
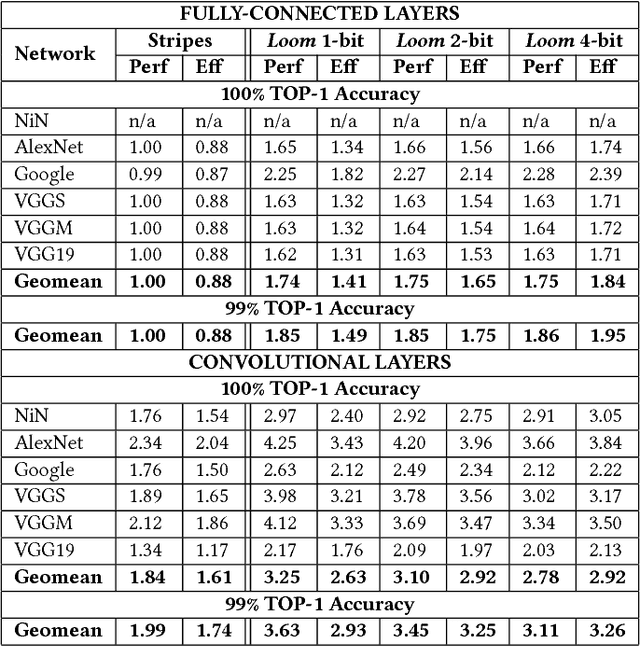
Loom (LM), a hardware inference accelerator for Convolutional Neural Networks (CNNs) is presented. In LM every bit of data precision that can be saved translates to proportional performance gains. Specifically, for convolutional layers LM's execution time scales inversely proportionally with the precisions of both weights and activations. For fully-connected layers LM's performance scales inversely proportionally with the precision of the weights. LM targets area- and bandwidth-constrained System-on-a-Chip designs such as those found on mobile devices that cannot afford the multi-megabyte buffers that would be needed to store each layer on-chip. Accordingly, given a data bandwidth budget, LM boosts energy efficiency and performance over an equivalent bit-parallel accelerator. For both weights and activations LM can exploit profile-derived perlayer precisions. However, at runtime LM further trims activation precisions at a much smaller than a layer granularity. Moreover, it can naturally exploit weight precision variability at a smaller granularity than a layer. On average, across several image classification CNNs and for a configuration that can perform the equivalent of 128 16b x 16b multiply-accumulate operations per cycle LM outperforms a state-of-the-art bit-parallel accelerator [1] by 4.38x without any loss in accuracy while being 3.54x more energy efficient. LM can trade-off accuracy for additional improvements in execution performance and energy efficiency and compares favorably to an accelerator that targeted only activation precisions. We also study 2- and 4-bit LM variants and find the the 2-bit per cycle variant is the most energy efficient.