 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFault Localization in Deep Learning-based Software: A System-level Approach
Nov 12, 2024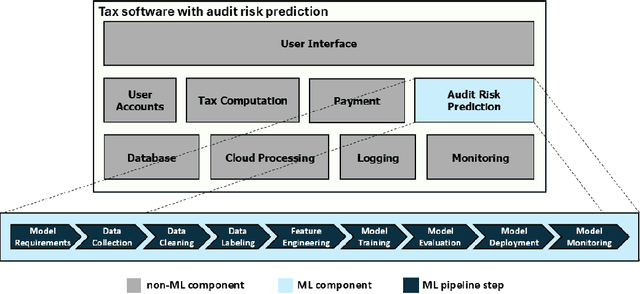

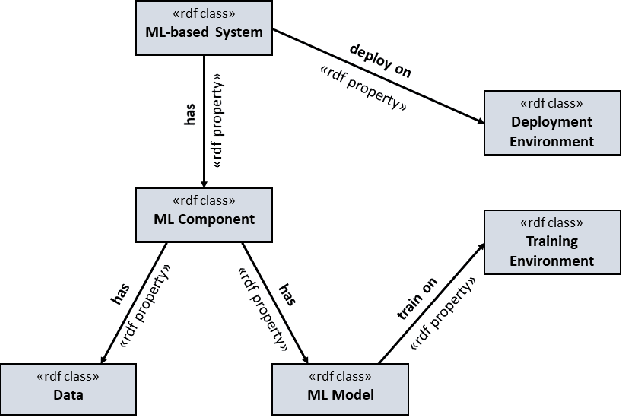
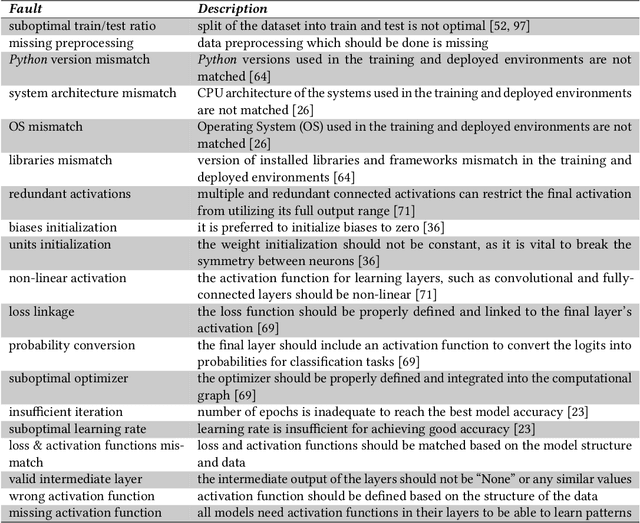
Over the past decade, Deep Learning (DL) has become an integral part of our daily lives. This surge in DL usage has heightened the need for developing reliable DL software systems. Given that fault localization is a critical task in reliability assessment, researchers have proposed several fault localization techniques for DL-based software, primarily focusing on faults within the DL model. While the DL model is central to DL components, there are other elements that significantly impact the performance of DL components. As a result, fault localization methods that concentrate solely on the DL model overlook a large portion of the system. To address this, we introduce FL4Deep, a system-level fault localization approach considering the entire DL development pipeline to effectively localize faults across the DL-based systems. In an evaluation using 100 faulty DL scripts, FL4Deep outperformed four previous approaches in terms of accuracy for three out of six DL-related faults, including issues related to data (84%), mismatched libraries between training and deployment (100%), and loss function (69%). Additionally, FL4Deep demonstrated superior precision and recall in fault localization for five categories of faults including three mentioned fault types in terms of accuracy, plus insufficient training iteration and activation function.
Bug Characterization in Machine Learning-based Systems
Jul 26, 2023Rapid growth of applying Machine Learning (ML) in different domains, especially in safety-critical areas, increases the need for reliable ML components, i.e., a software component operating based on ML. Understanding the bugs characteristics and maintenance challenges in ML-based systems can help developers of these systems to identify where to focus maintenance and testing efforts, by giving insights into the most error-prone components, most common bugs, etc. In this paper, we investigate the characteristics of bugs in ML-based software systems and the difference between ML and non-ML bugs from the maintenance viewpoint. We extracted 447,948 GitHub repositories that used one of the three most popular ML frameworks, i.e., TensorFlow, Keras, and PyTorch. After multiple filtering steps, we select the top 300 repositories with the highest number of closed issues. We manually investigate the extracted repositories to exclude non-ML-based systems. Our investigation involved a manual inspection of 386 sampled reported issues in the identified ML-based systems to indicate whether they affect ML components or not. Our analysis shows that nearly half of the real issues reported in ML-based systems are ML bugs, indicating that ML components are more error-prone than non-ML components. Next, we thoroughly examined 109 identified ML bugs to identify their root causes, symptoms, and calculate their required fixing time. The results also revealed that ML bugs have significantly different characteristics compared to non-ML bugs, in terms of the complexity of bug-fixing (number of commits, changed files, and changed lines of code). Based on our results, fixing ML bugs are more costly and ML components are more error-prone, compared to non-ML bugs and non-ML components respectively. Hence, paying a significant attention to the reliability of the ML components is crucial in ML-based systems.
Bugs in Machine Learning-based Systems: A Faultload Benchmark
Jun 24, 2022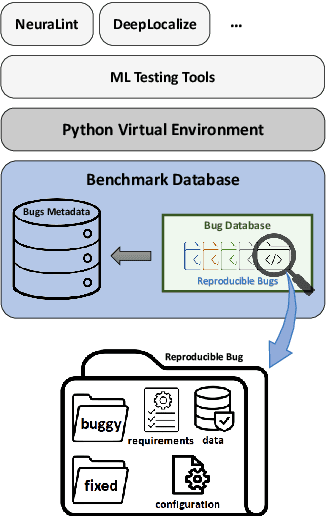

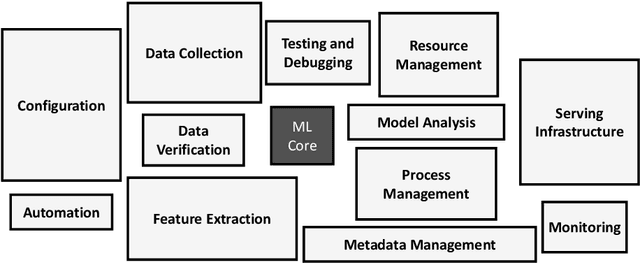

The rapid escalation of applying Machine Learning (ML) in various domains has led to paying more attention to the quality of ML components. There is then a growth of techniques and tools aiming at improving the quality of ML components and integrating them into the ML-based system safely. Although most of these tools use bugs' lifecycle, there is no standard benchmark of bugs to assess their performance, compare them and discuss their advantages and weaknesses. In this study, we firstly investigate the reproducibility and verifiability of the bugs in ML-based systems and show the most important factors in each one. Then, we explore the challenges of generating a benchmark of bugs in ML-based software systems and provide a bug benchmark namely defect4ML that satisfies all criteria of standard benchmark, i.e. relevance, reproducibility, fairness, verifiability, and usability. This faultload benchmark contains 113 bugs reported by ML developers on GitHub and Stack Overflow, using two of the most popular ML frameworks: TensorFlow and Keras. defect4ML also addresses important challenges in Software Reliability Engineering of ML-based software systems, like: 1) fast changes in frameworks, by providing various bugs for different versions of frameworks, 2) code portability, by delivering similar bugs in different ML frameworks, 3) bug reproducibility, by providing fully reproducible bugs with complete information about required dependencies and data, and 4) lack of detailed information on bugs, by presenting links to the bugs' origins. defect4ML can be of interest to ML-based systems practitioners and researchers to assess their testing tools and techniques.